You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
88 lines
7.5 KiB
88 lines
7.5 KiB
|
5 years ago
|
---
|
||
|
|
早期(编译器)优化
|
||
|
|
---
|
||
|
|
|
||
|
|
### 目录
|
||
|
|
|
||
|
|
1. 概述
|
||
|
|
2. Javac 编译器
|
||
|
|
- 解析和填充符号表
|
||
|
|
- 语义分析和字节码生成
|
||
|
|
3. 小结
|
||
|
|
|
||
|
|
### 概述
|
||
|
|
|
||
|
|
Java 语言的 ”编译器“ 其实是一段 ”不确定“ 的操作过程,因为它可能是指一个前端编译器把 java 文件转变成 class 文件的过程;也可能是指虚拟机的后端运行期编译器(JIT 编译器)把字节码转变成机器码的过程;还可能是指使用静态提前编译器(AOT 编译器)直接把 java 文件编译成本地机器代码的过程。下面列举了这三类编译过程中一些比较有代表的编译器:
|
||
|
|
|
||
|
|
- 前端编译器:Javac
|
||
|
|
- JIT 编译器:HotSpot VM 的 C1、C2 编译器
|
||
|
|
- AOT 编译器:ART
|
||
|
|
|
||
|
|
这三类过程中最符合大家对 Java 程序编译认知的应该就是第一类,在本章的后续文字里,提到的编译器都只限于第一类编译过程。限制了编译范围之后,对于 “优化” 二字的定义就需要宽松一些,因为 Javac 这类编译器对代码的运行效率几乎没有任何优化措施。虚拟机设计团队把对性能的优化集中到了后端的即时编译器中,这样可以让那些不是由 Javac 产生的 Class 文件也同样能享受到编译器优化所带来的好处。但是 Javac 做了很多针对 Java 语言编码过程的优化措施来改善程序的编码风格和提高编码效率。相当多的 Java 语法特性,都是靠编译器的 “语法糖” 来实现的。可以说,Java 中即时编译器在运行期的优化过程对于程序运行来说更重要,而前端编译器在编译器的优化过程对于程序编码来说关系更加密切。
|
||
|
|
|
||
|
|
### Javac 编译器
|
||
|
|
|
||
|
|
Javac 编译过程大致可以分为三个过程:
|
||
|
|
|
||
|
|
1. 解析与填充符号表过程
|
||
|
|
2. 插入式注解处理器的注解处理过程
|
||
|
|
3. 分析与字节码生成过程
|
||
|
|
|
||
|
|
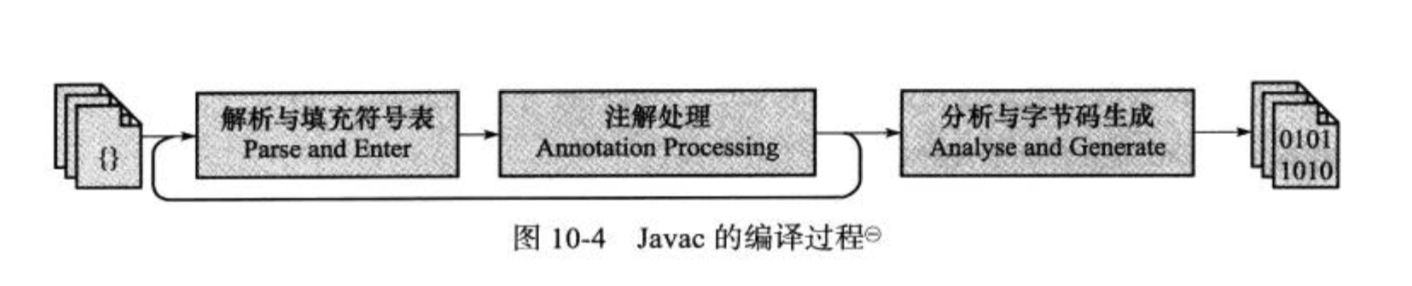
|
||
|
|
|
||
|
|
#### 解析与填充符号表
|
||
|
|
|
||
|
|
解析步骤包括了经典程序编译原理中的词法分析和语法分析两个过程。
|
||
|
|
|
||
|
|
词法分析是将源代码的字符流变为标记(Token)集合,单个字符是程序编写过程的最小元素,而标记则是编译过程中的最小元素,关键字、变量名、字面量、运算符都可以成为标记,如 "int a = b + 2" 这句代码包含了 6 个标记,分别是 int、a、=、b、+、2,虽然关键字 int 由三个字符构成,但是它只是一个 Token,不可再拆分。
|
||
|
|
|
||
|
|
语法分析是根据 Token 序列构造抽象语法树的过程,抽象语法树(AST)是一种用来描述程序代码语法结构的树形表示方式,语法树的每一个节点都代表着程序代码中的一个语法结构,例如包、类型、修饰符、接口、返回值甚至代码注释等都可以是一个语法结构。
|
||
|
|
|
||
|
|
完成了词法分析和语法分析之后,下一步就是填充符号表的过程。符号表是由一组符号地址和符号信息构成的表格,你可以把它想象成哈希表中的 K-V 值对的形式。符号表中所登记的信息在编译的不同阶段都要用到。在语义分析中,符号表所登记的内容将用于语义检查和产生中间代码。在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的依据。
|
||
|
|
|
||
|
|
#### 语义分析与字节码生成
|
||
|
|
|
||
|
|
语法分析之后,编译器获得了程序代码的抽象语法树表示,语法树能表示一个结构正确的源程序的抽象,但是无法保证源程序是符合逻辑的。而语义分析的主要任务是对结构上正确的源程序进行上下文有关性质的审查,如进行类型审查。比如:
|
||
|
|
|
||
|
|
```java
|
||
|
|
int a = 1;
|
||
|
|
boolean b= false;
|
||
|
|
|
||
|
|
int c = 1 + b; //无法编译
|
||
|
|
```
|
||
|
|
|
||
|
|
Javac 的编译过程中,语义分析过程分为标注检查以及数据及控制流分析两个步骤。
|
||
|
|
|
||
|
|
标注检查步骤检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配等。在标注检查步骤中,还有一个重要的动作称为常量折叠,如果我们在代码中写了如下定义:
|
||
|
|
|
||
|
|
```java
|
||
|
|
int a = 1 + 2;
|
||
|
|
```
|
||
|
|
|
||
|
|
那么在语法树上仍然可以看到字面量 1、2 和操作符 +,但是经过常量折叠之后,它们将会被折叠为字面量 3。
|
||
|
|
|
||
|
|
数据及控制流分析是对程序上下文逻辑更进一步的验证,它可以检查出诸如程序局部变量使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等问题。编译时期的数据以及控制流分析与类加载时的数据及控制流分析的目的基本上是一致的,但校验范围有区别,有一些校验项只有在编译期或运行期才能进行。
|
||
|
|
|
||
|
|
```java
|
||
|
|
public void foo(int arg) {
|
||
|
|
int var = 0;
|
||
|
|
|
||
|
|
}
|
||
|
|
|
||
|
|
public final foo(final int arg) {
|
||
|
|
final var = 0;
|
||
|
|
|
||
|
|
}
|
||
|
|
```
|
||
|
|
|
||
|
|
在这两个方法中,在代码编写时程序肯定会受到 final 修饰符的影响,但是这两段代码编译出来的 Class 文件是没有任何区别的。之前已经讲过,局部变量与字段(实例变量、类变量)是有区别的,它在常量池中没有 CONSTANT_Fieldref_info 的符号引用,自然就没有访问标志(Access_Flags)的信息,甚至可能连名称都不会保留下来,自然在 Class 文件中不可能知道一个局部变量是不是声明为 final 了。因此,将局部变量声明为 final,对运行期是没有影响的,变量的不变性仅仅由编译器在编译期间保障。
|
||
|
|
|
||
|
|
字节码生成是 Javac 编译过程的最后一个阶段,该阶段不仅仅是把前面各个步骤所生成的信息(语法树、符号表)转化成字节码写到磁盘中,编译器还进行了少量的代码添加和转换工作。
|
||
|
|
|
||
|
|
例如,前面多次提到的实例构造器 \<init>() 方法和类构造器 \<clinit>() 方法就是在这个阶段添加到语法树之中的(注意,这里的实例构造器并不是指默认构造函数,如果用户代码中没有提供任何构造函数,那编译器将会添加一个没有参数、访问性与当前类一致的默认构造函数),这两个构造器的产生过程实际上是一个代码收敛的过程,编译器会把语句块(实例构造器而言是 “{}” 块,对于类构造器而言是 "static{}" 块)、变量初始化(实例变量和类变量)、调用父类的实例构造器(仅仅是实例构造器,\<clinit>() 方法中无需调用父类的 \<clinit>() 方法,虚拟机会自动保证父类构造器的执行,但在 \<clinit>() 方法中经常会生成调用 java.lang.Object 的 \<init>() 方法的代码)等操作收敛到 \<init>() 和 \<clinit>() 方法之中,并且保证一定是按先执行父类的实例构造器,然后初始化变量,最后执行语句块的顺序进行。除了生成构造器以外,还有其他的一些代码替换工作用于优化程序的实现逻辑,如把字符串的加操作替换为 StringBuffer 或 StringBuilder 操作等。
|
||
|
|
|
||
|
|
完成了对语法树的遍历和调整之后,就会把填充了所有所需信息的符号表交给 ClassWrite 类,有这个类的 writeClass() 方法输出字节码,生成最终的 Class 文件,到此为止整个编译过程宣告结束。
|
||
|
|
|
||
|
|
### 小结
|
||
|
|
|
||
|
|
在前端编译器中,“优化” 手段主要用于提升程序的编码效率,之所以把 Javac 这类将 Java 代码转变为字节码的编译器称为前端编译器,只因为它只完成了从程序到抽象语法树或中间字节码的生成,而在此之后,比如内置在虚拟机内部的后端编译器,更多是编译优化的承担者。
|