@ -1,159 +1,159 @@ |
||||
--- |
||||
HTTP/2.0 |
||||
--- |
||||
|
||||
#### 目录 |
||||
|
||||
1. 思维导图 |
||||
2. 前言 |
||||
3. 设计和技术目标 |
||||
* 二进制分帧层 |
||||
* 流、消息与帧 |
||||
* 多项请求与响应 |
||||
* 请求优先级 |
||||
* 服务器推送 |
||||
* 首部压缩 |
||||
4. 二进制分帧层简介 |
||||
|
||||
#### 前言 |
||||
|
||||
HTTP/2.0 的目的就是通过支持请求与响应的多路复用来减少延迟,通过压缩 HTTP 首部字段将协议开销降至最低,同时增加对请求优先级和服务器推送的支持。为达到这些目标,HTTP/2.0 还会给我们带来大量其他协议层面的辅助实现,比如新的流量控制、错误处理和更新机制。 |
||||
|
||||
HTTP/2.0 不会改动 HTTP 的语义,HTTP 方法、状态码、URI 及首部字段,等等这些核心概念一如往常。但是,HTTP/2.0 修改了格式化数据(分帧)的方式,以及客户端与服务器间传输这些数据的方式。这两点统帅全局,通过新的组帧机制向我们的应用隐藏了所有复杂性。换句话说,所有原来的应用都可以不必修改而在新协议运行。 |
||||
|
||||
#### 设计和技术目标 |
||||
|
||||
HTTP/1.x 的设计初衷主要是实现要简单:HTTP/0.9 只用一行协议就启动了万维网;HTTP/1.0 则是对流行的 0.9 扩展的一个正式说明;HTTP/1.1 则是 IETF 的一份官方标准。因此,HTTP 0.9~1.x 只描述了现实是怎么一回事:HTTP 是应用最广泛、采用最多的一个互联网应用协议。 |
||||
|
||||
然而,实现简单是以牺牲应用性能为代价的,而这正是 HTTP/2.0 要致力于解决的:HTTP/2.0 通过支持首部字段压缩和在同一个连接上发送多个并发消息,让应用更有效地利用网络资源,减少感知的延迟时间。而且,它还支持服务器到客户端的主动推送机制。 |
||||
|
||||
##### 二进制分帧层 |
||||
|
||||
HTTP/2.0 性能增强的核心,全在于新增的二进制分帧层,它定义了如何封装 HTTP 消息并在客户端与服务器之间传输。 |
||||
|
||||
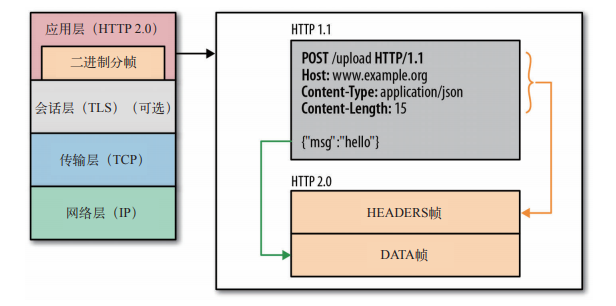 |
||||
|
||||
这里所谓的层,指的是位于套接字接口与应用可见的高层 HTTP API 之间的一个新机制:HTTP 的语义,包括各种动词、方法、首部,都不受影响,不同的是传输期间对它们的编码方式变了。HTTP/1.x 以换行符作为纯文本的分隔符,而 HTTP/2.0 将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码。 |
||||
|
||||
##### 流、消息和帧 |
||||
|
||||
新的二进制分帧机制改变了客户端与服务器之间交互数据的格式,为了说明这个过程,我们需要了解 HTTP/2.0 两个新的概念: |
||||
|
||||
* 流 |
||||
|
||||
已建立的连接上的双向字节流。 |
||||
|
||||
* 消息 |
||||
|
||||
与逻辑消息对应的完整的一系列数据帧。 |
||||
|
||||
* 帧 |
||||
|
||||
HTTP/2.0 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流。 |
||||
|
||||
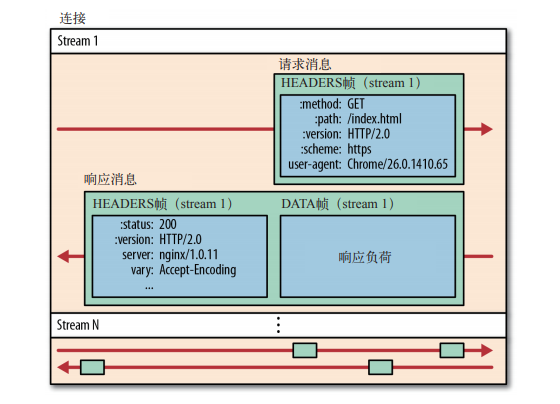 |
||||
|
||||
所有 HTTP/2.0 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一个或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。 |
||||
|
||||
这简简单单的几句话里浓缩了大量的信息,要理解 HTTP/2.0,就必须理解流、消息和帧这几个基础概念: |
||||
|
||||
1. 所有通信都在一个 TCP 连接上完成 |
||||
2. 流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2 ~N) |
||||
3. 消息是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成 |
||||
4. 帧是最小的通信单位,承载着特定类型的数据,如 HTTP 首部、负荷,等等 |
||||
|
||||
简言之,HTTP/2.0 把 HTTP 协议通信的基本单位缩小为一个一个的帧,这些帧对应着逻辑流中的消息。相应的,很多流可以并行的在同一个 TCP 连接上交换消息。 |
||||
|
||||
##### 多向请求与响应 |
||||
|
||||
在 HTTP/1.x 中,如果客户端想发送多个并行的请求以及改进性能,那么必须使用多个 TCP 连接。这是 HTTP/1.x 交互模型的直接结果,该模型会保证每个连接每次只交互一个响应(多个响应必须排队)。更糟糕的是,这种模型也会导致队首阻塞,从而造成底层 TCP 连接的效率低下。 |
||||
|
||||
HTTP/2.0 中新的二进制分帧层突破了这些限制,实现了多向请求和响应:客户端和服务器可以把 HTTP 消息分解为互不依赖的帧,然后乱序发送,最后再在另一端把它们重新组合起来。 |
||||
|
||||
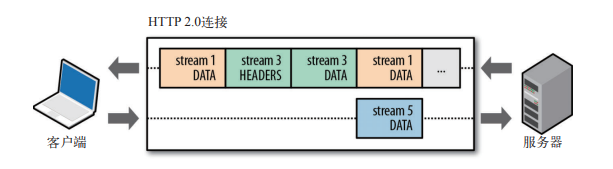 |
||||
|
||||
上图中包含了同一个连接上多个传输中的数据流:客户端正在向服务器传输一个 DATA 帧(stream 5),与此同时,服务器正向客户端乱序发送 stream 1 和 stream 3 的一系列帧。此时,一个连接上有 3 个请求/响应并行交换! |
||||
|
||||
把 HTTP 消息分解为独立的帧,交错发送,然后在另一端重新组装是 HTTP/2.0 最重要的一项增强。事实上,这个机制会在整个 Web 技术栈中引发一系列连锁反应,从而带来巨大的性能提升,因为: |
||||
|
||||
* 可以并行交错的发送请求,请求之间互不影响 |
||||
* 可以并行交错的发送响应,响应之间互不干扰 |
||||
* 只使用一个连接即可并行发送多个请求和响应 |
||||
* 消除不必要的延迟,从而减少页面加载的时间 |
||||
* 不必再为绕过 HTTP/1.x 限制而多做很多工作 |
||||
|
||||
总之,HTTP/2.0 的二进制分帧机制解决了 HTTP/1.x 中存在的队首阻塞问题,也消除了并行处理和发送请求及响应时对多个连接的依赖。结果,就是应用速度更快,开发更简单,部署成本更低。 |
||||
|
||||
> 支持多向请求与响应,可以省掉针对 HTTP/1.x 限制所费的那些脑筋和工作,比如拼接文件、图片精灵、域名分区。类似的,通过减少 TCP 连接的数量,HTTP/2.0 也会减少客户端和服务器的 CPU 及内存占用。 |
||||
|
||||
##### 请求优先级 |
||||
|
||||
把 HTTP 消息分解为很多独立的帧之后,就可以通过优化这些帧的交错和传输顺序,进一步提升性能。为了做到这一点,每个流都可以带一个 31 比特的优先值: |
||||
|
||||
* 0 表示最高优先级 |
||||
* 2^31 - 1 表示最低优先级 |
||||
|
||||
有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。具体来讲,服务器可以根据流的优先级,控制资源分配(CPU、内存、带宽),而在响应数据准备好之后,优先将最高优先级的帧发送给客户端。 |
||||
|
||||
##### 服务器推送 |
||||
|
||||
HTTP/2.0 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确的请求。 |
||||
|
||||
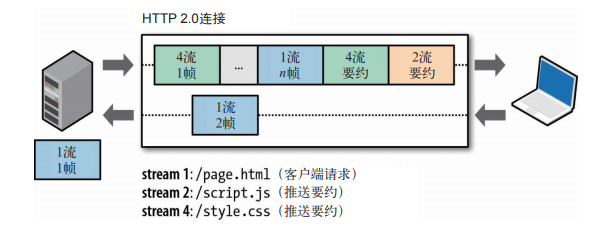 |
||||
|
||||
建立 HTTP/2.0 连接后,客户端与服务器交换 SETTINGS 帧,借此可以限定双向并发的流的最大数量。因此,客户端可以限定推送流的数量,或者通过把这个值设置为 0 而完全禁用服务器推送。 |
||||
|
||||
为什么需要这样一个机制呢?通常的 Web 应用都由几十个资源组成,客户端需要分析服务器提供的文档才能逐个找到它们。那为什么不让服务器提前就把这些资源推送给客户端,从而减少额外的时间延迟呢?服务器已经知道客户端下一步要请求什么资源了,这时候服务器推送即可派上用场。上篇文章所说的 “嵌入资源” 也可以算作服务器推送。把资源直接插入到文档中,就是把资源直接推送给客户端,而无需客户端请求。在 HTTP/2.0 中,唯一的不同就是把这个过程从应用中拿出来,放到 HTTP 协议本身来实现,而且还带来了如下好处: |
||||
|
||||
* 客户端可以缓存推送过来的资源 |
||||
* 客户端可以拒绝推送过来的资源 |
||||
* 推送资源可以由不同的页面共享 |
||||
* 服务器可以按照优先级推送资源 |
||||
|
||||
最后还有一点,就是推送的资源将直接进入客户端缓存,就像客户端请求了似的。不存在客户端 API 或 JavaScript 回调方法等通知机制,可以用于确定资源何时到达。整个过程对运行在浏览器中的 Web 应用来说好像根本不存在。 |
||||
|
||||
##### 首部压缩 |
||||
|
||||
HTTP 的每一次通信都会携带一组首部,用于描述传输的资源及其属性。在 HTTP/1.x 中,这些元数据都是以纯文本形式发送的,通常会给每个请求增加 500~800 字节的负荷。如果算上 HTTP Cookie,增加的负荷通常会达到上千字节。为减少这些开销并提升性能,HTTP/2.0 会压缩首部元数据: |
||||
|
||||
* HTTP/2.0 在客户端和服务器端使用 “首部表” 来跟踪和存储之前发送的键值对,对于相同的数据,不在通过每次请求和响应发送。 |
||||
* 首部表在 HTTP/2.0 的连接存续期内始终存在,由客户端和服务器共同渐进的更新。 |
||||
* 每个新的首部键值对要么被追加到当前表的末尾,要么替换表中之前的值 |
||||
|
||||
于是,HTTP/2.0 连接的两端都知道已经发送了哪些首部,这些首部的值是什么,从而可以针对之前的数据只编码发送差异数据。 |
||||
|
||||
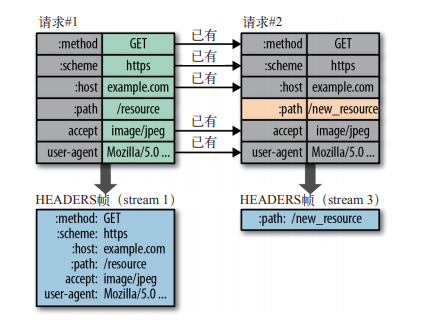 |
||||
|
||||
请求与响应首部的定义在 HTTP/2.0 中基本没有改变,只是所有首部键必须全部小写,而且请求行要独立为 :method、:scheme、:host 和 :path 等这些键值对。 |
||||
|
||||
在前面的例子中,第二次请求只需要发送变化了的路径首部(:path),其他首部没有变化,不用再发送了。这样就可以避免传输冗余的首部,从而显著减少每个请求的开销。 |
||||
|
||||
#### 二进制分帧层简介 |
||||
|
||||
HTTP/2.0 的根本改进还是新增的长度前置的二进制分帧层。与 HTTP/1.x 使用换行符分隔纯文本不同,二进制分帧层更加简洁,通过代码处理起来更简单也更有效。 |
||||
|
||||
建立了 HTTP/2.0 连接后,客户端与服务器会通过交换帧来通信,帧是基于这个新协议通信的最小单位。所有帧都共享一个 8 字节的首部,如下图所示,其中包含帧的长度、类型、标志,还有一个保留位和一个 31 位的流标识符。 |
||||
|
||||
 |
||||
|
||||
* 16 位的长度前缀意味着一帧大约可以携带 64 KB 数据,不包括 8 字节首部 |
||||
* 8 位的类型字段决定如何解释帧其余部分的内容 |
||||
* 8 位的标志字段允许不同的帧类型定义特定于帧的消息标志 |
||||
* 1 位的保留字段始终置为 0 |
||||
* 31 位的流标识符唯一标识 HTTP/2.0 的流 |
||||
|
||||
知道了帧类型,解析器就知道该如何解析帧的其余内容了,HTTP/2.0 规定了如下帧类型: |
||||
|
||||
* DATA:用于传输 HTTP 消息体 |
||||
* HEADERS:用于传输关于流的额外的首部字段 |
||||
* PRIORITY:用于指定或重新指定引用资源的优先级 |
||||
* RST_STREAM:用于通知流的非正常终止 |
||||
* SETTINGS:用于通知两端通信方式的配置数据 |
||||
* PUSH_PROMISE:用于发出创建流和服务器引用资源的要约 |
||||
* PING:用于计算往返时间,执行 “活性” 检查 |
||||
* GOAWAY:用于通知对端停止在当前连接中创建流 |
||||
* WINDOW_UPDATE:用于针对个别流或个别连接实现流量控制 |
||||
* CONTINUATION:用于继续一系列首部块片段 |
||||
|
||||
服务器可以利用 GOAWAY 类型的帧告诉客户端要处理的最后一个流的 ID,从而消除一些请求竞争,而且浏览器也可以据此智能的重试或取消 “悬着的” 请求。这也是保证复用连接安全的一个重要和必要的功能。 |
||||
|
||||
--- |
||||
HTTP/2.0 |
||||
--- |
||||
|
||||
#### 目录 |
||||
|
||||
1. 思维导图 |
||||
2. 前言 |
||||
3. 设计和技术目标 |
||||
* 二进制分帧层 |
||||
* 流、消息与帧 |
||||
* 多项请求与响应 |
||||
* 请求优先级 |
||||
* 服务器推送 |
||||
* 首部压缩 |
||||
4. 二进制分帧层简介 |
||||
|
||||
#### 前言 |
||||
|
||||
HTTP/2.0 的目的就是通过支持请求与响应的多路复用来减少延迟,通过压缩 HTTP 首部字段将协议开销降至最低,同时增加对请求优先级和服务器推送的支持。为达到这些目标,HTTP/2.0 还会给我们带来大量其他协议层面的辅助实现,比如新的流量控制、错误处理和更新机制。 |
||||
|
||||
HTTP/2.0 不会改动 HTTP 的语义,HTTP 方法、状态码、URI 及首部字段,等等这些核心概念一如往常。但是,HTTP/2.0 修改了格式化数据(分帧)的方式,以及客户端与服务器间传输这些数据的方式。这两点统帅全局,通过新的组帧机制向我们的应用隐藏了所有复杂性。换句话说,所有原来的应用都可以不必修改而在新协议运行。 |
||||
|
||||
#### 设计和技术目标 |
||||
|
||||
HTTP/1.x 的设计初衷主要是实现要简单:HTTP/0.9 只用一行协议就启动了万维网;HTTP/1.0 则是对流行的 0.9 扩展的一个正式说明;HTTP/1.1 则是 IETF 的一份官方标准。因此,HTTP 0.9~1.x 只描述了现实是怎么一回事:HTTP 是应用最广泛、采用最多的一个互联网应用协议。 |
||||
|
||||
然而,实现简单是以牺牲应用性能为代价的,而这正是 HTTP/2.0 要致力于解决的:HTTP/2.0 通过支持首部字段压缩和在同一个连接上发送多个并发消息,让应用更有效地利用网络资源,减少感知的延迟时间。而且,它还支持服务器到客户端的主动推送机制。 |
||||
|
||||
##### 二进制分帧层 |
||||
|
||||
HTTP/2.0 性能增强的核心,全在于新增的二进制分帧层,它定义了如何封装 HTTP 消息并在客户端与服务器之间传输。 |
||||
|
||||
 |
||||
|
||||
这里所谓的层,指的是位于套接字接口与应用可见的高层 HTTP API 之间的一个新机制:HTTP 的语义,包括各种动词、方法、首部,都不受影响,不同的是传输期间对它们的编码方式变了。HTTP/1.x 以换行符作为纯文本的分隔符,而 HTTP/2.0 将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码。 |
||||
|
||||
##### 流、消息和帧 |
||||
|
||||
新的二进制分帧机制改变了客户端与服务器之间交互数据的格式,为了说明这个过程,我们需要了解 HTTP/2.0 两个新的概念: |
||||
|
||||
* 流 |
||||
|
||||
已建立的连接上的双向字节流。 |
||||
|
||||
* 消息 |
||||
|
||||
与逻辑消息对应的完整的一系列数据帧。 |
||||
|
||||
* 帧 |
||||
|
||||
HTTP/2.0 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流。 |
||||
|
||||
 |
||||
|
||||
所有 HTTP/2.0 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一个或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。 |
||||
|
||||
这简简单单的几句话里浓缩了大量的信息,要理解 HTTP/2.0,就必须理解流、消息和帧这几个基础概念: |
||||
|
||||
1. 所有通信都在一个 TCP 连接上完成 |
||||
2. 流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2 ~N) |
||||
3. 消息是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成 |
||||
4. 帧是最小的通信单位,承载着特定类型的数据,如 HTTP 首部、负荷,等等 |
||||
|
||||
简言之,HTTP/2.0 把 HTTP 协议通信的基本单位缩小为一个一个的帧,这些帧对应着逻辑流中的消息。相应的,很多流可以并行的在同一个 TCP 连接上交换消息。 |
||||
|
||||
##### 多向请求与响应 |
||||
|
||||
在 HTTP/1.x 中,如果客户端想发送多个并行的请求以及改进性能,那么必须使用多个 TCP 连接。这是 HTTP/1.x 交互模型的直接结果,该模型会保证每个连接每次只交互一个响应(多个响应必须排队)。更糟糕的是,这种模型也会导致队首阻塞,从而造成底层 TCP 连接的效率低下。 |
||||
|
||||
HTTP/2.0 中新的二进制分帧层突破了这些限制,实现了多向请求和响应:客户端和服务器可以把 HTTP 消息分解为互不依赖的帧,然后乱序发送,最后再在另一端把它们重新组合起来。 |
||||
|
||||
 |
||||
|
||||
上图中包含了同一个连接上多个传输中的数据流:客户端正在向服务器传输一个 DATA 帧(stream 5),与此同时,服务器正向客户端乱序发送 stream 1 和 stream 3 的一系列帧。此时,一个连接上有 3 个请求/响应并行交换! |
||||
|
||||
把 HTTP 消息分解为独立的帧,交错发送,然后在另一端重新组装是 HTTP/2.0 最重要的一项增强。事实上,这个机制会在整个 Web 技术栈中引发一系列连锁反应,从而带来巨大的性能提升,因为: |
||||
|
||||
* 可以并行交错的发送请求,请求之间互不影响 |
||||
* 可以并行交错的发送响应,响应之间互不干扰 |
||||
* 只使用一个连接即可并行发送多个请求和响应 |
||||
* 消除不必要的延迟,从而减少页面加载的时间 |
||||
* 不必再为绕过 HTTP/1.x 限制而多做很多工作 |
||||
|
||||
总之,HTTP/2.0 的二进制分帧机制解决了 HTTP/1.x 中存在的队首阻塞问题,也消除了并行处理和发送请求及响应时对多个连接的依赖。结果,就是应用速度更快,开发更简单,部署成本更低。 |
||||
|
||||
> 支持多向请求与响应,可以省掉针对 HTTP/1.x 限制所费的那些脑筋和工作,比如拼接文件、图片精灵、域名分区。类似的,通过减少 TCP 连接的数量,HTTP/2.0 也会减少客户端和服务器的 CPU 及内存占用。 |
||||
|
||||
##### 请求优先级 |
||||
|
||||
把 HTTP 消息分解为很多独立的帧之后,就可以通过优化这些帧的交错和传输顺序,进一步提升性能。为了做到这一点,每个流都可以带一个 31 比特的优先值: |
||||
|
||||
* 0 表示最高优先级 |
||||
* 2^31 - 1 表示最低优先级 |
||||
|
||||
有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。具体来讲,服务器可以根据流的优先级,控制资源分配(CPU、内存、带宽),而在响应数据准备好之后,优先将最高优先级的帧发送给客户端。 |
||||
|
||||
##### 服务器推送 |
||||
|
||||
HTTP/2.0 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确的请求。 |
||||
|
||||
 |
||||
|
||||
建立 HTTP/2.0 连接后,客户端与服务器交换 SETTINGS 帧,借此可以限定双向并发的流的最大数量。因此,客户端可以限定推送流的数量,或者通过把这个值设置为 0 而完全禁用服务器推送。 |
||||
|
||||
为什么需要这样一个机制呢?通常的 Web 应用都由几十个资源组成,客户端需要分析服务器提供的文档才能逐个找到它们。那为什么不让服务器提前就把这些资源推送给客户端,从而减少额外的时间延迟呢?服务器已经知道客户端下一步要请求什么资源了,这时候服务器推送即可派上用场。上篇文章所说的 “嵌入资源” 也可以算作服务器推送。把资源直接插入到文档中,就是把资源直接推送给客户端,而无需客户端请求。在 HTTP/2.0 中,唯一的不同就是把这个过程从应用中拿出来,放到 HTTP 协议本身来实现,而且还带来了如下好处: |
||||
|
||||
* 客户端可以缓存推送过来的资源 |
||||
* 客户端可以拒绝推送过来的资源 |
||||
* 推送资源可以由不同的页面共享 |
||||
* 服务器可以按照优先级推送资源 |
||||
|
||||
最后还有一点,就是推送的资源将直接进入客户端缓存,就像客户端请求了似的。不存在客户端 API 或 JavaScript 回调方法等通知机制,可以用于确定资源何时到达。整个过程对运行在浏览器中的 Web 应用来说好像根本不存在。 |
||||
|
||||
##### 首部压缩 |
||||
|
||||
HTTP 的每一次通信都会携带一组首部,用于描述传输的资源及其属性。在 HTTP/1.x 中,这些元数据都是以纯文本形式发送的,通常会给每个请求增加 500~800 字节的负荷。如果算上 HTTP Cookie,增加的负荷通常会达到上千字节。为减少这些开销并提升性能,HTTP/2.0 会压缩首部元数据: |
||||
|
||||
* HTTP/2.0 在客户端和服务器端使用 “首部表” 来跟踪和存储之前发送的键值对,对于相同的数据,不在通过每次请求和响应发送。 |
||||
* 首部表在 HTTP/2.0 的连接存续期内始终存在,由客户端和服务器共同渐进的更新。 |
||||
* 每个新的首部键值对要么被追加到当前表的末尾,要么替换表中之前的值 |
||||
|
||||
于是,HTTP/2.0 连接的两端都知道已经发送了哪些首部,这些首部的值是什么,从而可以针对之前的数据只编码发送差异数据。 |
||||
|
||||
 |
||||
|
||||
请求与响应首部的定义在 HTTP/2.0 中基本没有改变,只是所有首部键必须全部小写,而且请求行要独立为 :method、:scheme、:host 和 :path 等这些键值对。 |
||||
|
||||
在前面的例子中,第二次请求只需要发送变化了的路径首部(:path),其他首部没有变化,不用再发送了。这样就可以避免传输冗余的首部,从而显著减少每个请求的开销。 |
||||
|
||||
#### 二进制分帧层简介 |
||||
|
||||
HTTP/2.0 的根本改进还是新增的长度前置的二进制分帧层。与 HTTP/1.x 使用换行符分隔纯文本不同,二进制分帧层更加简洁,通过代码处理起来更简单也更有效。 |
||||
|
||||
建立了 HTTP/2.0 连接后,客户端与服务器会通过交换帧来通信,帧是基于这个新协议通信的最小单位。所有帧都共享一个 8 字节的首部,如下图所示,其中包含帧的长度、类型、标志,还有一个保留位和一个 31 位的流标识符。 |
||||
|
||||
 |
||||
|
||||
* 16 位的长度前缀意味着一帧大约可以携带 64 KB 数据,不包括 8 字节首部 |
||||
* 8 位的类型字段决定如何解释帧其余部分的内容 |
||||
* 8 位的标志字段允许不同的帧类型定义特定于帧的消息标志 |
||||
* 1 位的保留字段始终置为 0 |
||||
* 31 位的流标识符唯一标识 HTTP/2.0 的流 |
||||
|
||||
知道了帧类型,解析器就知道该如何解析帧的其余内容了,HTTP/2.0 规定了如下帧类型: |
||||
|
||||
* DATA:用于传输 HTTP 消息体 |
||||
* HEADERS:用于传输关于流的额外的首部字段 |
||||
* PRIORITY:用于指定或重新指定引用资源的优先级 |
||||
* RST_STREAM:用于通知流的非正常终止 |
||||
* SETTINGS:用于通知两端通信方式的配置数据 |
||||
* PUSH_PROMISE:用于发出创建流和服务器引用资源的要约 |
||||
* PING:用于计算往返时间,执行 “活性” 检查 |
||||
* GOAWAY:用于通知对端停止在当前连接中创建流 |
||||
* WINDOW_UPDATE:用于针对个别流或个别连接实现流量控制 |
||||
* CONTINUATION:用于继续一系列首部块片段 |
||||
|
||||
服务器可以利用 GOAWAY 类型的帧告诉客户端要处理的最后一个流的 ID,从而消除一些请求竞争,而且浏览器也可以据此智能的重试或取消 “悬着的” 请求。这也是保证复用连接安全的一个重要和必要的功能。 |
||||
|
||||
@ -0,0 +1,173 @@ |
||||
--- |
||||
UDP 的构成 |
||||
--- |
||||
|
||||
#### 目录 |
||||
|
||||
1. 前言 |
||||
2. 无协议服务 |
||||
3. UDP 与网络地址转换器 |
||||
* 连接状态超时 |
||||
* NAT 穿透 |
||||
* STUN、TURN 与 ICE |
||||
4. 针对 UDP 的优化建议 |
||||
|
||||
#### 前言 |
||||
|
||||
1980 年 8月,紧随 TCP/IP 之后,UDP(用户数据报协议)被 John Postel 加入了核心网络协议套件。UDP 的主要功能和亮点不在于它引入了什么特性,而在于它忽略了哪些特性。UDP 经常被称为无(Null)协议,RFC 768 描述了其运作机制,全文完全可以写在一张餐巾纸上。 |
||||
|
||||
> 数据报 |
||||
> |
||||
> 一个完整、独立的数据实体,携带着从源节点到目的地节点的足够信息,对这些节点间之前的数据交换和传输网络没有任何依赖。 |
||||
|
||||
数据报(datagram)和分组(packet)是两个经常被人混用的词,实际上它们还是有区别的。分组可以用来指代任何格式化的数据块,而数据报则通常只用来描述那些通过不可靠的服务传输的分组,既不保证送达,也不发送失败通知。正因为如此,很多场合下人们都把 UDP 中 User 的 U 改成 Unreliable(不可靠)的 U,于是 UDP 就成了 “不可靠数据报协议”。这也是为什么把 UDP 分组称为数据报更为恰当的原因。 |
||||
|
||||
关于 UDP 的应用,最广为人知同时也是所有浏览器和因特网应用都赖以运作的,就是 DNS。DNS 负责把主机名转换成 IP 地址。可是,尽管浏览器有赖于 UDP,但这个协议以前从未被看成网页和应用的关键传输机制。HTTP 并未规定要使用 TCP,但现实中所有 HTTP 实现都是用 TCP。 |
||||
|
||||
不过,这都是过去的事了。IETF 和 W3C 工作组共同制定了一套新 API --- WebRTC(Web 实时通信)。WebRTC 着眼于在浏览器中通过 UDP 实现原生的语音和视频实时通信,以及其他形式的 P2P(端到端)通信。正是因为 WebRTC 的出现,UDP 作为浏览器中重要传输机制的地位才得以突显,而且还有了浏览器 API! |
||||
|
||||
#### 无协议服务 |
||||
|
||||
要理解为什么 UDP 被人称作 “无协议”,必须从作为 TCP 和 UDP 下一层的 IP 协议说起。 |
||||
|
||||
IP 层的主要任务就是按照地址从源主机向目标主机发送数据报。为此,消息会被封装在一个 IP 分组内,其中载明了源地址和目标地址,以及其他一些路由参数。注意,数据报这个词暗示了一个重要的信息:IP 层不保证消息可靠的交互,也不发送失败通知,实际上是把底层网络的不可靠性直接暴露给了上一层。如果某个路由节点因为网络阻塞、负载过高或其他原因而删除了 IP 分组,那么在必要的情况下,IP 的上一层协议要负责检测、恢复和重发数据。 |
||||
|
||||
下面看一下 IPv4 首部(20 字节): |
||||
|
||||
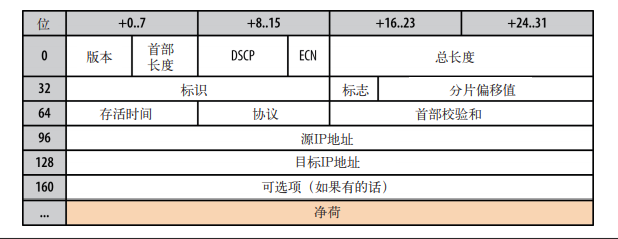 |
||||
|
||||
UDP 协议会用自己的分组结构(如下图)封装用户消息,它只增加了 4 个字段:源端口、目标端口、分组长度和效验和。这样,当 IP 把分组送达目标主机时,主机能够拆开 UDP 分组,根据目标端口找到目标应用程序,然后再把消息发送过去。仅此而已。 |
||||
|
||||
下面就是 UDP 首部(8 字节): |
||||
|
||||
 |
||||
|
||||
事实上,UDP 数据报中的源端口和效验和字段都是可选的。IP 分组的首部也有效验和,应用程序可以忽略 UDP 效验和。也就是说,所有错误检测和错误纠正工作都可以委托给上层的应用程序。说到底,UDP 仅仅是在 IP 层之上通过嵌入应用程序的源端口和目标端口,提供了一个 “应用程序多路复用” 机制。明白了这一点,就可以总结一下 UDP 的无服务是怎么回事了。 |
||||
|
||||
* 不保证消息交互 |
||||
|
||||
不确认,不重传,无超时。 |
||||
|
||||
* 不保证交互顺序 |
||||
|
||||
不设置包序号,不重拍,不会发生队首阻塞。 |
||||
|
||||
* 不跟踪连接状态 |
||||
|
||||
不必建立连接或重启状态机。 |
||||
|
||||
* 不需要拥塞控制 |
||||
|
||||
不内置客户端或网络反馈机制。 |
||||
|
||||
TCP 是一个面向字节流的协议,能够以多个分组形式发送应用程序消息,且对分组中的消息范围没有任何明确限制。因此,连接的两端存在一个连接状态,每个分组都有序号,丢失还要重发,并且要按顺序交互。相对来说,UDP 数据报有明确的限制:数据报必须封装在 IP 分组中,应用程序必须读取完整的消息。换句话说,数据报不能分片。 |
||||
|
||||
UDP 是一个简单、无状态的协议,适合作为其他上层应用协议的辅助。实际上,这个协议的所有决定都需要由上层的应用程序作出。 |
||||
|
||||
#### UDP 与网络地址转换器 |
||||
|
||||
令人遗憾的是,IPv4 地址只有 32 位长,因而最多只能提供 42.9 亿个唯一 IP 地址。1990 年代初,互联网上的主机数量呈指数级增长,但不可能所有主机都分配一个唯一的 IP 地址。1994 年,作为解决 IPv4 地址即将耗尽的一个临时性方案,IP 网络地址转换器(NAT)规范出台了。 |
||||
|
||||
建议的 IP 重用方案就是在网络边缘加入 NAT 设备,每个 NAT 设备负责维护一个表,表中包含本地 IP 和端口到全球唯一(外网)IP 和端口的映射。这样,NAT 设备背后的 IP 地址空间就可以在各种不同的网络中得到重用,从而解决地址耗尽问题。 |
||||
|
||||
IP 地址网络转换器: |
||||
|
||||
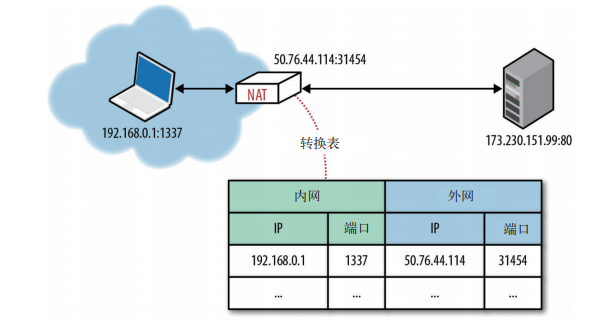 |
||||
|
||||
然而,这个临时性的方案居然就那么一直沿用了下来。新增的 NAT 设备不仅立竿见影的解决了地址耗尽问题,而且还迅速成为很多公司及家庭代理和路由器、安全装置、防火墙,以及其他很多硬件和软件设备中的内置组件。NAT 不再是个临时性方案,它已经成了因特网基础设施的一个组成部分。 |
||||
|
||||
作为监管全球 IP 地址分配的机构,IANA 为私有网络保留了三段 IP 地址,这些 IP 地址经常可以在 NAT 设备后面的内网中看到。 |
||||
|
||||
保留的 IP 地址范围: |
||||
|
||||
| IP 地址范围 | 地址数量 | |
||||
| ----------------------------- | ---------- | |
||||
| 10.0.0.0 - 10.255.255.255 | 16 777 216 | |
||||
| 172.16.0.0 - 172.31.255.255 | 1 048 576 | |
||||
| 192.168.0.0 - 192.168.255.255 | 65 536 | |
||||
|
||||
其中一段 IP 地址是不是很眼熟?在你的局域网中,路由器给你的计算机分配的 IP 地址很可能位于其中一段。这个地址就是你在内网中的私有地址。在需要与外网通信时,NAT 设备会将它们转换成外网地址。 |
||||
|
||||
为防止路由器错误和引起不必要的麻烦,不允许给外网计算机分配这些保留的私有地址。 |
||||
|
||||
##### 连接状态超时 |
||||
|
||||
NAT 转换的问题(至少对于 UDP 而言)在于必须维护一份精确的路由表才能保证数据转发。NAT 设备依赖连接状态,而 UDP 没有状态。这种根本上的错配是很多 UDP 数据报传输问题的总根源。况且,客户端前面有很多个 NAT 设备的情况也不鲜见,问题由此进一步恶化了。 |
||||
|
||||
每个 TCP 连接都有一个设计周密的协议状态机,从握手开始,然后传输应用数据,最后通过明确的信号确认关闭连接。在这种设计下,路由设备可以监控连接状态,根据情况创建或删除路由表中的条目。而 UDP 呢,没有握手,没有连接终止,实际根本没有可监控的连接状态机。 |
||||
|
||||
发送出站的 UDP 不费事,但路由响应却需要转换表中有一个条目能告诉我们本地目标主机的 IP 和端口。因此,转换器必须保存每个 UDP 流的状态,而 UDP 自身却没有状态。 |
||||
|
||||
更糟糕的是,NAT 设备还被赋予了删除转换记录的责任,但由于 UDP 没有连接终止确认环节,任何一端随时都可以停止传输数据报,而不必发送通告。为解决这个问题,UDP 路由记录会定时过期。定时多长?没有规定,完全取决于转换器的制造商、型号、版本和配置。因此,对于较长时间的 UDP 通信,有一个事实上的最佳做法,即引入一个双向 keep-alive 分组,周期性的重置传输路径上所有 NAT 设备中转换记录的计时器。 |
||||
|
||||
##### NAT 穿透 |
||||
|
||||
不可预测的连接状态处理是 NAT 设备带来的一个严重问题,但更为严重的则是很多应用程序根本不能建立 UDP 连接。尤其是 P2P 应用程序,涉及 VoIP、游戏和文件共享等,它们客户端与服务器经常需要角色互换,以实现端到端的双向通信。 |
||||
|
||||
NAT 带来的第一个问题,就是内部客户端不知道外网 IP 地址,制只知道内网 IP 地址。NAT 负责重写每个 UDP 分组中的源端口、地址,以及 IP 分组中的源 IP 地址。如果客户端在应用数据中以其内网 IP 地址与外网主机通信,必然连接失败。所谓的 “透明” 转换因此也就成了一句空话,如果应用程序想与私有网络外部的主机通信,那么它首先必须知道自己的外网 IP 地址。 |
||||
|
||||
然鹅,知道外网 IP 地址还不是实现 UDP 传输的充分条件。任何到达 NAT 设备外网 IP 的分组还必须有一个目标端口,而且 NAT 转换表中也要有一个条目可以将其转换为内部主机的 IP 地址和端口号。如果没有这个条目(通常是从外网传数据进来),那到达地分组就会被删除。此时的 NAT 设备就像一个分组过滤器,除非用户通过端口转发或类似机制配置过,否则它无法确定将分组发送给哪台内部主机。 |
||||
|
||||
由于没有映射规则,入站分组直接被删除: |
||||
|
||||
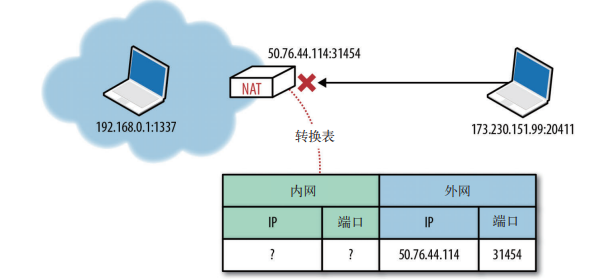 |
||||
|
||||
需要注意的是,上述行为对客户端应用程序不是问题。客户端应用程序基于内部网络实现交互,会在交互期间建立必要的转换记录。不过,如果隔着 NAT 设备,那客户端(作为服务器)处理来自 P2P 应用程序(VoIP、游戏、文件共享)的入站连接时,就必须面对 NAT 穿透问题。 |
||||
|
||||
为解决 UDP 与 NAT 的这种不搭配,人们发明了很多穿透技术(TURN、STUN、ICE),用于在 UDP 主机之间建立端对端的连接。 |
||||
|
||||
##### STUN、TURN 与 ICE |
||||
|
||||
STUN 是一个协议,可以让应用程序发现网络中的地址转换器,发现之后进一步取得为当前连接分配的外网 IP 地址和端口。为此,这个协议需要一个已知的第三方 STUN 服务器支持,该服务器必须架设在公网上。 |
||||
|
||||
STUN 查询外网 IP 地址和端口: |
||||
|
||||
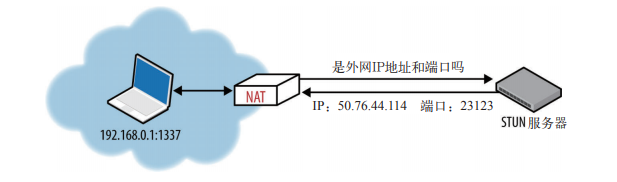 |
||||
|
||||
假设 STUN 服务器的 IP 地址已知(通过 DNS 查找或手工指定),应用程序首先向 STUN 服务器发送一个绑定请求。然后,STUN 服务器返回一个响应,其中包含在外网中代表客户端的 IP 地址和端口号。这种简单的方式解决了前面讨论的一些问题: |
||||
|
||||
* 应用程序可以获得外网 IP 和端口,并利用这些信息与对端通信 |
||||
* 发送到 STUN 服务器的出站绑定请求将在通信要经过的 NAT 中建立路由条目,使得到达该 IP 和端口的入站分组可以找到内网中的应用程序。 |
||||
* STUN 协议定义了一个简单的 keep-alive 探测机制,可以保证 NAT 路由条目不超时 |
||||
|
||||
有了这个机制,两台主机端需要通过 UDP 通信时,它们首先都会向各自的 STUN 服务器发送绑定请求,然后分别使用响应中的外网 IP 地址和端口号交换数据。 |
||||
|
||||
但在实际应用中,STUN 并不能适应所有类型的 NAT 和网络配置。不仅如此,某些情况下 UDP 还会被防火墙或其他网络设备完全屏蔽。这种情况在很多企业网很常见。为解决这个问题,在 STUN 失败的情况下,我们还可以使用 TURN 协议作为后备。TURN 可以在最坏的情况下跳过 UDP 而切换到 TCP。 |
||||
|
||||
TURN 中的关键词当然是中继。这个协议依赖于外网中继设备在两端间传递数据。 |
||||
|
||||
TURN 中继服务器: |
||||
|
||||
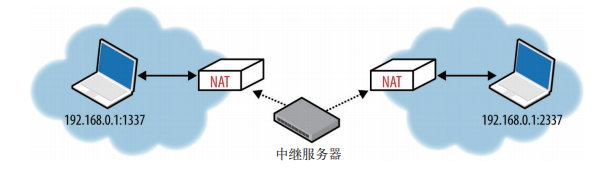 |
||||
|
||||
* 两端都要向同一台 TURN 服务器发送分配请求未建立连接,然后在进行权限协商 |
||||
* 协商完毕,两端都把数据发送到 TURN 服务器,再有 TURN 服务器转发,从而实现通信 |
||||
|
||||
很明显,这就不再是端对端的数据交换了!TURN 是在任何网络中为两端提供连接的最可靠方式,但运维 TURN 服务器的投入也很大。至少,为满足传输数据的需要,中继设备的容量必须足够大。因此,最好在其他直连手段都失败的情况下,在使用 TURN。 |
||||
|
||||
##### ICE |
||||
|
||||
构建高效的 NAT 穿透方案可不容易。好在,我们还有 ICE 协议。ICE 规定了一套方法,致力于在通信各端之间建立一条最有效的通信:能直连就直连,必要时 STUN 协商,再不行使用 TURN。 |
||||
|
||||
ICE 先后尝试直连、STUN 和 TURN: |
||||
|
||||
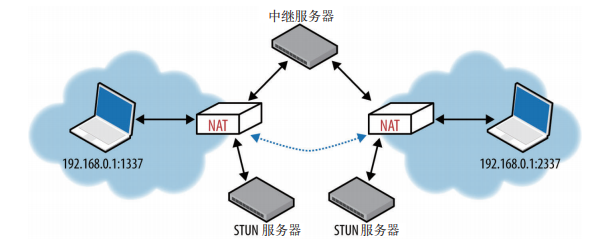 |
||||
|
||||
#### 针对 UDP 的优化建议 |
||||
|
||||
UDP 是一个简单常用的协议,经常用于引导其他传输协议。事实上,UDP 的特色在于它所省略的那些功能:连接状态、握手、重发、重组、重排、拥塞控制、拥塞预防、流量控制,甚至可选的错误检测,统统没有。这个面向消息的最简单的传输层在提供灵活性的同时,也给实现者带来了麻烦。你的应用程序很可能需要从头实现上诉几个或大部分功能,而且每项功能都必须保证与网络中的其他主机和协议和谐共存。 |
||||
|
||||
与内置流量和拥塞控制以及拥塞预防的 TCP 不同,UDP 应用程序必须自己实现这些机制。拥塞处理做的不到位的 UDP 应用程序很容易堵塞网络,造成网络性能下降,严重时还会导致网络拥塞崩溃。如果你想在自己的应用程序中使用 UDP,务必要认真研究和学习当下的最佳实践和建议。RFC 5405 就是这么一份文档,它对设计单播 UDP 应用程序给出了很多设计建议,简述如下: |
||||
|
||||
* 应用程序必须容忍各种因特网路径条件 |
||||
* 应用程序应该控制传输速度 |
||||
* 应用程序应该对所有流量进行拥塞控制 |
||||
* 应用程序应该使用与 TCP 相近的带宽 |
||||
* 应用程序应该准备基于丢包的重发计数器 |
||||
* 应用程序应该不发送大于路径 MTU 的数据报 |
||||
* 应用程序应该处理数据报丢失、重复和重排 |
||||
* 应用程序应该足够稳定以支持两分钟以上的交付延迟 |
||||
* 应用程序应该支持 IPv4 UDP 校验和,必须支持 IPv6 校验和 |
||||
* 应用程序可以在需要时使用 keep-alive(最小间隔 15 秒) |
||||
|
||||
很高兴的告诉大家:WebRTC 就是符合这些要求的框架! |
||||
@ -0,0 +1,4 @@ |
||||
--- |
||||
传输层安全(TLS) |
||||
--- |
||||
|
||||
@ -1,62 +1,62 @@ |
||||
--- |
||||
针对浏览器的优化建议 |
||||
--- |
||||
|
||||
#### 前言 |
||||
|
||||
浏览器可远远不止一个网络套接字管理器那么简单,性能可以说是每个浏览器开发商的核心卖点,既然性能如此重要,那浏览器越来越聪明也就毫不奇怪了。预解析可能的 DNS 查询、预连接可能的目标、预取得和优先取得重要资源,这些都是浏览器变聪明的标志。 |
||||
|
||||
#### 优化建议 |
||||
|
||||
可行的优化手段会因浏览器而异,但从核心优化策略来说,可以宽泛的分为两类: |
||||
|
||||
* 基于文档的优化 |
||||
|
||||
熟悉网络协议,了解文档、CSS 和 JavaScript 解析管道,发现和优先安排关键网络资源,尽早分配请求并取得页面,使其尽快达到可交互的状态。主要方法是优先获取资源、提前解析等。 |
||||
|
||||
* 推测性优化 |
||||
|
||||
浏览器可以学习用户的导航模式,执行推测性优化,尝试预测用户的下一次操作,然后,预先解析 DNS、预先连接可能的目标。 |
||||
|
||||
好消息是,所有的这些优化都是由浏览器替我们自动完成的,经常可以节省几百 ms 的网络延迟。既然如此,那理解这些优化背后的原理就至关重要了,这样才能利用浏览器的这些特性,提升应用性能。大多数浏览器都利用了如下四种技术: |
||||
|
||||
1. 资源预取和排定优先次序 |
||||
|
||||
文档、CSS 和 JavaScript 解析器可以与网络协议层沟通,声明各种资源的优先级;初始渲染必需的阻塞资源具有最高优先级,而低优先级的请求可能会被临时保存在队列中。 |
||||
|
||||
2. DNS 预解析 |
||||
|
||||
对可能的域名进行提前解析,避免将来 HTTP 请求时的 DNS 延迟。预解析可以通过学习导航历史、用户的鼠标悬停,或其他页面信号来触发。 |
||||
|
||||
3. TCP 预连接 |
||||
|
||||
DNS 解析之后,浏览器可以根据预测的 HTTP 请求,推测性的打开 TCP 连接。如果猜对的话,则可以节省一次完整的往返(TCP 握手)时间。 |
||||
|
||||
4. 页面预渲染 |
||||
|
||||
某些浏览器可以让我们提升下一个可能的目标,从而在隐藏的标签页中预先渲染整个页面。这样,当用户真的触发导航时,就能立即切换过来。 |
||||
|
||||
从外部看,现代浏览器的网络协议实现以简单的资源获取机制的面目示人,而从内部来说,它又极为复杂精密,为了解如何优化性能,非常值得深入钻研。那么,在探寻的过程中,我们怎么利用浏览器的这些机制呢?首先,要密切关注每个页面的结构和交互: |
||||
|
||||
* CSS 和 JavaScript 等重要资源应该尽早在文档中出现 |
||||
* 应该尽早交互 CSS,从而解除渲染阻塞并让 JavaScript 执行 |
||||
* 非关键性 JavaScript 应该推迟,以避免阻塞 DOM 和 CSSOM 构建 |
||||
* HTML 文档由解析器递增解析,从而保证文档可以间歇性发送,以求得最佳性能 |
||||
|
||||
除了优化页面结构,还可以在文档中嵌入提示,以触发浏览器为我们采用其他优化机制: |
||||
|
||||
```html |
||||
<link rel="dns-prefetch" href="//hostname_to_resolve.com"> |
||||
<link rel="subresource" href="/javascript/myapp.js"> |
||||
<link rel="prefetch" href="/images/big.jpeg"> |
||||
<link rel="prerender" href="//example.org/next_page.html"> |
||||
``` |
||||
|
||||
从上到下,依次是: |
||||
|
||||
1. 预解析特定的域名 |
||||
2. 预取得页面后面要用到的关键性资源 |
||||
3. 预取得将来导航要用的资源 |
||||
4. 根据对用户下一个目标的预测,预渲染特定页面 |
||||
|
||||
--- |
||||
针对浏览器的优化建议 |
||||
--- |
||||
|
||||
#### 前言 |
||||
|
||||
浏览器可远远不止一个网络套接字管理器那么简单,性能可以说是每个浏览器开发商的核心卖点,既然性能如此重要,那浏览器越来越聪明也就毫不奇怪了。预解析可能的 DNS 查询、预连接可能的目标、预取得和优先取得重要资源,这些都是浏览器变聪明的标志。 |
||||
|
||||
#### 优化建议 |
||||
|
||||
可行的优化手段会因浏览器而异,但从核心优化策略来说,可以宽泛的分为两类: |
||||
|
||||
* 基于文档的优化 |
||||
|
||||
熟悉网络协议,了解文档、CSS 和 JavaScript 解析管道,发现和优先安排关键网络资源,尽早分配请求并取得页面,使其尽快达到可交互的状态。主要方法是优先获取资源、提前解析等。 |
||||
|
||||
* 推测性优化 |
||||
|
||||
浏览器可以学习用户的导航模式,执行推测性优化,尝试预测用户的下一次操作,然后,预先解析 DNS、预先连接可能的目标。 |
||||
|
||||
好消息是,所有的这些优化都是由浏览器替我们自动完成的,经常可以节省几百 ms 的网络延迟。既然如此,那理解这些优化背后的原理就至关重要了,这样才能利用浏览器的这些特性,提升应用性能。大多数浏览器都利用了如下四种技术: |
||||
|
||||
1. 资源预取和排定优先次序 |
||||
|
||||
文档、CSS 和 JavaScript 解析器可以与网络协议层沟通,声明各种资源的优先级;初始渲染必需的阻塞资源具有最高优先级,而低优先级的请求可能会被临时保存在队列中。 |
||||
|
||||
2. DNS 预解析 |
||||
|
||||
对可能的域名进行提前解析,避免将来 HTTP 请求时的 DNS 延迟。预解析可以通过学习导航历史、用户的鼠标悬停,或其他页面信号来触发。 |
||||
|
||||
3. TCP 预连接 |
||||
|
||||
DNS 解析之后,浏览器可以根据预测的 HTTP 请求,推测性的打开 TCP 连接。如果猜对的话,则可以节省一次完整的往返(TCP 握手)时间。 |
||||
|
||||
4. 页面预渲染 |
||||
|
||||
某些浏览器可以让我们提升下一个可能的目标,从而在隐藏的标签页中预先渲染整个页面。这样,当用户真的触发导航时,就能立即切换过来。 |
||||
|
||||
从外部看,现代浏览器的网络协议实现以简单的资源获取机制的面目示人,而从内部来说,它又极为复杂精密,为了解如何优化性能,非常值得深入钻研。那么,在探寻的过程中,我们怎么利用浏览器的这些机制呢?首先,要密切关注每个页面的结构和交互: |
||||
|
||||
* CSS 和 JavaScript 等重要资源应该尽早在文档中出现 |
||||
* 应该尽早交互 CSS,从而解除渲染阻塞并让 JavaScript 执行 |
||||
* 非关键性 JavaScript 应该推迟,以避免阻塞 DOM 和 CSSOM 构建 |
||||
* HTML 文档由解析器递增解析,从而保证文档可以间歇性发送,以求得最佳性能 |
||||
|
||||
除了优化页面结构,还可以在文档中嵌入提示,以触发浏览器为我们采用其他优化机制: |
||||
|
||||
```html |
||||
<link rel="dns-prefetch" href="//hostname_to_resolve.com"> |
||||
<link rel="subresource" href="/javascript/myapp.js"> |
||||
<link rel="prefetch" href="/images/big.jpeg"> |
||||
<link rel="prerender" href="//example.org/next_page.html"> |
||||
``` |
||||
|
||||
从上到下,依次是: |
||||
|
||||
1. 预解析特定的域名 |
||||
2. 预取得页面后面要用到的关键性资源 |
||||
3. 预取得将来导航要用的资源 |
||||
4. 根据对用户下一个目标的预测,预渲染特定页面 |
||||
|
||||
这里的每一个提示都会触发一个推测性优化机制。浏览器虽然不能保证落实,但可以利用这些提示优化加载策略。可惜的是,并非所有浏览器都支持这些提示,不过,如果它们不支持,也只会把提示当做空操作,有益无害。因此,一定要尽早可能利用这些字段。 |
||||
{kind=link}
|
After Width: | Height: | Size: 114 KiB |
{kind=link}
|
After Width: | Height: | Size: 91 KiB |
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
{kind=link}
|
After Width: | Height: | Size: 68 KiB |
{kind=link}
|
After Width: | Height: | Size: 52 KiB |
{kind=link}
|
After Width: | Height: | Size: 86 KiB |
{kind=link}
|
After Width: | Height: | Size: 19 KiB |