parent
5ba9c2ee53
commit
334a85fd1c
@ -0,0 +1,134 @@ |
||||
# iOS下的渲染框架 |
||||
|
||||
## 1.图形渲染框架 |
||||
|
||||
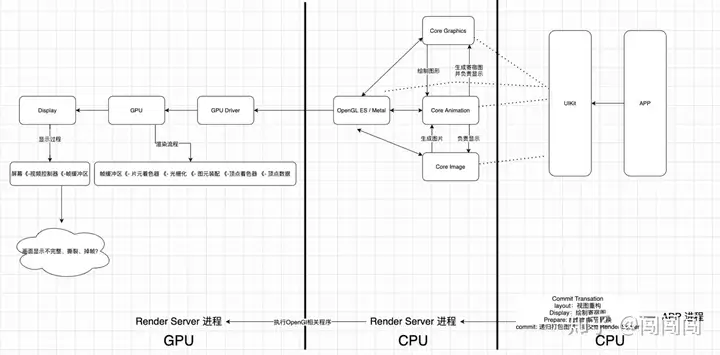
iOS APP图形渲染框架,APP在显示可视化的图形时,使用到了Core Animation、Core Graphics、Core Image等框架,这些框架在渲染图形时,都需要通过OpenGL ES / Metal来驱动GPU进行渲染与绘制。 |
||||
|
||||
 |
||||
|
||||
- **UIKit** |
||||
|
||||
UIKit是iOS开发最常用的框架,可以通过设置UIKit组件的布局以及相关属性来绘制界面。 |
||||
事实上,UIKit自身并不具备在屏幕成像的能力,其主要负责对用户操作事件的响应(UIView继承自UIResponder),事件响应的传递大体是经过逐层的**视图树**遍历实现的。 |
||||
|
||||
- **Core Animation** |
||||
|
||||
Core Animation源自于Layer Kit,动画只是Core Animation的冰山一角。 |
||||
Core Animation是一个复合引擎,其职责是**尽可能快地组合屏幕上不同的可视内容,这些可视内容可被分解成独立的图层(即CALayer),这些图层会被存储在一个叫做图层树的体系之中**。从本质上而言,CALayer是用户所能在屏幕上看见的一切的基础。 |
||||
|
||||
- **Core Graphics** |
||||
|
||||
Core Graphics是基于Quartz 的高级绘图引擎,主要用于运行时绘制图像。开发者可以使用此框架来处理基于路径的绘图,转换,颜色管理,离屏渲染,图案,渐变和阴影,图像数据管理,图像创建和图像遮罩以及PDF文档创建,显示和分析。 |
||||
|
||||
- **Core Image** |
||||
|
||||
Core Image与Core Graphics恰恰相反,Core Graphics用于在运行时创建图像,而Core Image用于处理运行前创建的图像。Core Image框架拥有一系列现成的图像过滤器,能对一寸照的图像进行高效的处理。大部分情况下,Core Image会在GPU中完成工作,如果GPU忙,会使用CPU进行处理。 |
||||
|
||||
## 2.UIView与CALayer的关系 |
||||
|
||||
CALayer事实上是用户所能在屏幕上看见的一切的基础。为什么UIKit中的视图能够呈现可视化内容,就是因为UIKit中的每一个UI视图控件其实内部都有一个关联的CALayer,即backing layer。 |
||||
|
||||
由于这种一一对应的关系,视图层级有用**视图树**的树形结构,对应CALayer层级也拥有**图层树**的树形结构。 |
||||
|
||||
其中,视图的职责是创建并管理图层,以确保当子视图在层级关系中添加或被移除时,其关联的图层在图层树中也有相同的操作,即保证视图树和图层树在结构上的一致性。 |
||||
|
||||
为什么iOS要基于UIView和CALayer提供两个平行的层级关系呢? |
||||
|
||||
其原因在于要做**职责分离**,这样也能避免很多重复代码。在iOS和Mac OSX两个平台上,事件和用户交互有很多地方的不同,基于多点触控的用户界面和基于鼠标键盘的交互有着本质的区别,这就是为什么iOS有UIKit和UIView,对应Mac OSX有AppKit和NSView的原因。它们在功能上很相似,但是在实现上有着显著的区别。实际上,这里并不是两个层级关系,而是四个。每一个都扮演着不同的角色。除了**视图树**和**图层树**,还有**呈现树**和**渲染树**。 |
||||
|
||||
那么为什么CALayer可以呈现可视化内容呢?因为CALayer基本等同于一个**纹理**。纹理是GPU进行图像渲染的重要依据。 |
||||
|
||||
在[图形渲染原理](https://link.zhihu.com/?target=https%3A//links.jianshu.com/go%3Fto%3Dhttp%3A%2F%2Fchuquan.me%2F2018%2F08%2F26%2Fgraphics-rending-principle-gpu%2F)中提到纹理本质上就是一张图片,因此CALayer也包含一个contents属性指向一块缓存区,称为backing store,可以存放位图(Bitmap)。iOS中将该缓存区保存的图片称为**寄宿图**。 |
||||
|
||||
 |
||||
|
||||
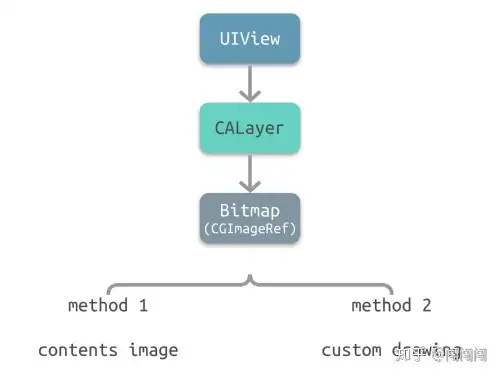
图形渲染流水线支持从顶点开始进行绘制(在流水线中,顶点会被处理生成纹理),也支持直接使用纹理(图片)进行渲染。相应地,在实际开发中,绘制界面也有两种方式: 一种是**手动绘制**;另一种是**使用图片**。 |
||||
|
||||
对此,iOS中也有两种相应的实现方式: |
||||
|
||||
- 使用图片:contents image |
||||
- 手动绘制:custom drawing |
||||
|
||||
**Contents Image** |
||||
Contents Image是指通过CALayer的contents属性来配置图片。然而,contents属性的类型为id,在这种情况下,可以给contents属性赋予任何值,app仍可以编译通过。但是在实践中,如果contents的值不是CGImage,得到的图层将是空白的。 |
||||
既然如此,为什么要将contents的属性类型定义为id而非CGImage。因为在Mac OS系统中,该属性对CGImage和NSImage类型的值都起作用,而在iOS系统中,该属性只对CGImage起作用。 |
||||
本质上,contents属性指向的一块缓存区域,称为backing store,可以存放bitmap数据。 |
||||
**Custom Drawing** |
||||
Custom Drawing是指使用Core Graphics直接绘制寄宿图。实际开发中,一般通过继承UIView并实现-drawRect:方法来自定义绘制。 |
||||
虽然-drawRect:是一个UIView方法,但事实上都是底层的CALayer完成了重绘工作并保存了产生的图片。 |
||||
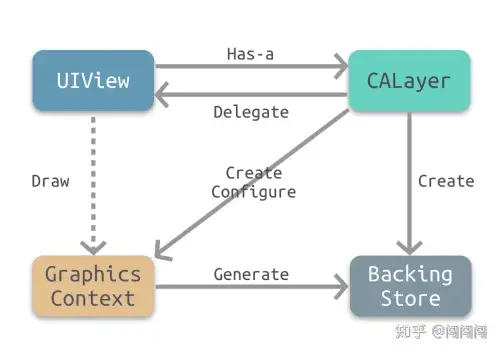
下图所示为drawRect:绘制定义寄宿图的基本原理 |
||||
|
||||
 |
||||
|
||||
- UIView有一个关联图层,即CALayer。 |
||||
- CALayer有一个可选的delegate属性,实现了CALayerDelegate协议。UIView作为CALayer的代理实现了CALayerDelegate协议。 |
||||
- 当需要重绘时,即调用-drawRect:,CALayer请求其代理给予一个寄宿图来显示。 |
||||
- CALayer首先会尝试调用-displayLayer:方法,此时代理可以直接设置contents属性。 |
||||
|
||||
```objective-c |
||||
- (void)displayLayer:(CALayer *)layer; |
||||
``` |
||||
|
||||
- 如果代理没有实现-displayLayer:方法,CALayer则会尝试调用`-`drawLayer:inContext:方法。在调用该方法前,CALayer会创建一个空的寄宿图(尺寸由bounds和contentScale决定)和一个Core Graphics的绘制上下文,为绘制寄宿图做准备,作为ctx参数传入。 |
||||
|
||||
```objective-c |
||||
- (void)drawLayer:(CALayer *)layer inContext:(CGContextRef)ctx; |
||||
``` |
||||
|
||||
- 最后,有Core Graphics绘制生成的寄宿图会存入backing store。 |
||||
|
||||
**三个框架间的依赖关系** |
||||
|
||||
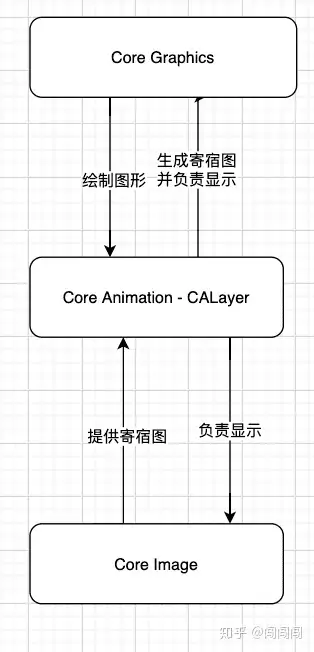
Core Animation、Core Graphics、Core Image这个三个框架间也存在着依赖关系。 |
||||
|
||||
上面提到CALayer是用户所能在屏幕上看到一切的基础。所以Core Graphics、Core Image是需要依赖于CALayer来显示界面的。由于CALayer又是Core Animation框架提供的,所以说Core Graphics、Core Image是依赖于``Core Animation ```的。 |
||||
|
||||
上文还提到每一个 UIView 内部都关联一个CALayer图层,即backing layer,每一个CALayer都包含一个content属性指向一块缓存区,即backing store, 里面存放位图(Bitmap)。iOS中将该缓存区保存的图片称为寄宿图。 |
||||
|
||||
这个寄宿图有两个设置方式: |
||||
|
||||
直接向content设置CGImage图片,这需要依赖Core Image来提供图片。 |
||||
|
||||
通过实现UIView的drawRect方法自定义绘图,这需要借助Core Graphics来绘制图形,再由CALayer生成图片。 |
||||
|
||||
 |
||||
|
||||
## 3.Core Animation 流水线 |
||||
|
||||
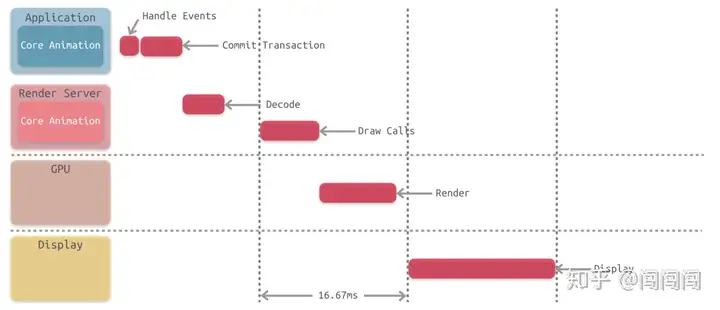
CALayer是如何调用 GPU 并显示可视化内容的呢?下面我们就需要介绍一下 Core Animation 流水线的工作原理。 |
||||
|
||||
 |
||||
|
||||
事实上,app 本身并不负责渲染,渲染则是由一个独立的进程负责,即Render Server进程。 |
||||
|
||||
App 通过 IPC 将渲染任务及相关数据提交给Render Server。Render Server处理完数据后,再传递至 GPU。最后由 GPU 调用 iOS 的图像设备进行显示。 |
||||
|
||||
Core Animation 流水线的详细过程如下: |
||||
|
||||
首先,由 app 处理事件(Handle Events),如:用户的点击操作,在此过程中 app 可能需要更新**视图树**,相应地,**图层树**也会被更新。 |
||||
|
||||
其次,app 通过 CPU 完成对显示内容的计算,如:视图的创建、布局计算、图片解码、文本绘制等。在完成对显示内容的计算之后,app 对图层进行打包,并在下一次 RunLoop 时将其发送至Render Server,即完成了一次Commit Transaction操作。 |
||||
|
||||
Render Server主要执行 Open GL、Core Graphics 相关程序,并调用 GPU |
||||
|
||||
GPU 则在物理层上完成了对图像的渲染。 |
||||
|
||||
最终,GPU 通过 Frame Buffer、视频控制器等相关部件,将图像显示在屏幕上。 |
||||
|
||||
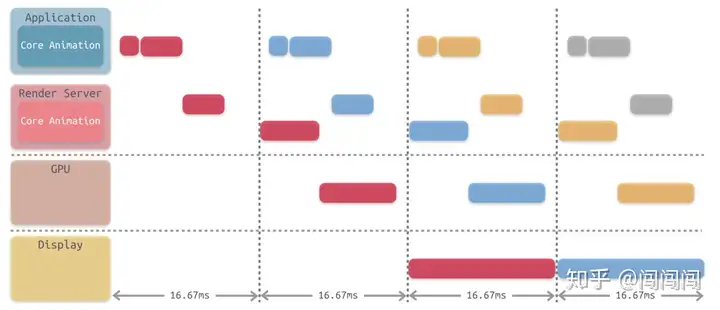
对上述步骤进行串联,它们执行所消耗的时间远远超过 16.67 ms,因此为了满足对屏幕的 60 FPS 刷新率的支持,需要将这些步骤进行分解,通过流水线的方式进行并行执行,如下图所示。 |
||||
|
||||
 |
||||
|
||||
**Commit Transaction** |
||||
|
||||
在 Core Animation 流水线中,app 调用Render Server前的最后一步 Commit Transaction 其实可以细分为 4 个步骤: |
||||
|
||||
Layout:主要进行视图构建,包括:LayoutSubviews方法的重载,addSubview:方法填充子视图等。 |
||||
|
||||
Display:视图绘制,这里仅仅是绘制寄宿图,该过程使用CPU和内存 |
||||
|
||||
Prepare:阶段属于附加步骤,一般处理图像的解码和转换等操作 |
||||
|
||||
Commit:主要将图层进行打包,并将它们发送至 Render Server。该过程会递归执行,因为图层和视图都是以树形结构存在。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/157556221 |
||||
@ -0,0 +1,367 @@ |
||||
# iOS音视频 -- AVFoundation捕捉 |
||||
|
||||
## 1、视频捕捉 |
||||
|
||||
### **1.1、实现QuickTime视频的录制** |
||||
|
||||
在上文中,简述了通过AVCapturePhotoOutput、AVCapturePhotoSettings来实现代理,获取当前摄像头所捕捉到的photo数据,生成一张图片。 |
||||
|
||||
视频录制过程大致也是如此,通过AVCaptureMovieFileOutput来获取视频数据,大致流程如下: |
||||
|
||||
\1. 开启录制之前需要判断当前是否处于录制状态,只有在非录制状态才能进入录制状态 |
||||
|
||||
```text |
||||
/// 是否在录制状态 |
||||
- (BOOL)isRecording { |
||||
return self.movieOutput.isRecording; |
||||
} |
||||
``` |
||||
|
||||
\2. 通过AVCaptureConnection来获取当前视频捕捉的连接信息 |
||||
|
||||
\1. 调整视频方向 |
||||
|
||||
\2. 判断是否支持视频稳定功能(非必要) |
||||
|
||||
\3. 判读是否支持平滑对焦(非必要) |
||||
|
||||
\4. 为视频输出配置输出路径 |
||||
|
||||
\5. 开始视频recording |
||||
|
||||
```text |
||||
/// 开始录制 |
||||
- (void)startRecording { |
||||
|
||||
if (![self isRecording]) { |
||||
//获取当前视频捕捉连接信息 |
||||
AVCaptureConnection *videoConnection = [self.movieOutput connectionWithMediaType:AVMediaTypeVideo]; |
||||
|
||||
//调整方向 |
||||
if ([videoConnection isVideoOrientationSupported]) { |
||||
videoConnection.videoOrientation = [self currentVideoOrientation]; |
||||
} |
||||
|
||||
//判断是否支持视频稳定功能(保证视频质量) |
||||
if ([videoConnection isVideoStabilizationSupported]) { |
||||
videoConnection.preferredVideoStabilizationMode = YES; |
||||
} |
||||
|
||||
//拿到活跃的摄像头 |
||||
AVCaptureDevice *device = [self activeCamera]; |
||||
//判断是否支持平滑对焦(当用户移动设备时, 能自动且快速的对焦) |
||||
if (device.isSmoothAutoFocusEnabled) { |
||||
NSError *error; |
||||
if ([device lockForConfiguration:&error]) { |
||||
device.smoothAutoFocusEnabled = YES; |
||||
[device unlockForConfiguration]; |
||||
} else { |
||||
//失败回调 |
||||
|
||||
} |
||||
} |
||||
|
||||
//获取路径 |
||||
self.outputURL = [self uniqueURL]; |
||||
|
||||
//摄像头的相关配置完成, 也获取到路径, 开始录制(这里录制QuckTime视频文件, 保存到相册) |
||||
[self.movieOutput startRecordingToOutputFileURL:self.outputURL recordingDelegate:self]; |
||||
|
||||
} |
||||
} |
||||
``` |
||||
|
||||
\3. 停止视频recording |
||||
|
||||
```text |
||||
/// 停止录制 |
||||
- (void)stopRecording { |
||||
if ([self isRecording]) { |
||||
[self.movieOutput stopRecording]; |
||||
} |
||||
} |
||||
///路径转换 |
||||
- (NSURL *)uniqueURL { |
||||
NSURL *url = [NSURL fileURLWithPath:[NSString stringWithFormat:@"%@%@", NSTemporaryDirectory(), @"output.mov"]]; |
||||
return url; |
||||
} |
||||
///获取方向值 |
||||
- (AVCaptureVideoOrientation)currentVideoOrientation { |
||||
AVCaptureVideoOrientation result; |
||||
|
||||
UIDeviceOrientation deviceOrientation = [UIDevice currentDevice].orientation; |
||||
switch (deviceOrientation) { |
||||
case UIDeviceOrientationPortrait: |
||||
case UIDeviceOrientationFaceUp: |
||||
case UIDeviceOrientationFaceDown: |
||||
result = AVCaptureVideoOrientationPortrait; |
||||
break; |
||||
case UIDeviceOrientationPortraitUpsideDown: |
||||
//如果这里设置成AVCaptureVideoOrientationPortraitUpsideDown,则视频方向和拍摄时的方向是相反的。 |
||||
result = AVCaptureVideoOrientationPortrait; |
||||
break; |
||||
case UIDeviceOrientationLandscapeLeft: |
||||
result = AVCaptureVideoOrientationLandscapeRight; |
||||
break; |
||||
case UIDeviceOrientationLandscapeRight: |
||||
result = AVCaptureVideoOrientationLandscapeLeft; |
||||
break; |
||||
default: |
||||
result = AVCaptureVideoOrientationPortrait; |
||||
break; |
||||
} |
||||
return result; |
||||
} |
||||
``` |
||||
|
||||
\4. 保存影片至相册 |
||||
|
||||
```text |
||||
///通过代理来获取视频数据#pragma mark - AVCaptureFileOutputRecordingDelegate |
||||
- (void)captureOutput:(AVCaptureFileOutput *)captureOutput |
||||
didFinishRecordingToOutputFileAtURL:(NSURL *)outputFileURL |
||||
fromConnections:(NSArray *)connections |
||||
error:(NSError *)error { |
||||
if (error) { |
||||
//错误回调 |
||||
|
||||
} else { |
||||
//视频写入到相册 |
||||
[self writeVideoToAssetsLibrary:[self.outputURL copy]]; |
||||
} |
||||
self.outputURL = nil; |
||||
} |
||||
//写入捕捉到的视频 |
||||
- (void)writeVideoToAssetsLibrary:(NSURL *)videoURL { |
||||
|
||||
__block PHObjectPlaceholder *assetPlaceholder = nil; |
||||
[[PHPhotoLibrary sharedPhotoLibrary] performChanges:^{ |
||||
//保存进相册 |
||||
PHAssetChangeRequest *changeRequest = [PHAssetChangeRequest creationRequestForAssetFromVideoAtFileURL:videoURL]; |
||||
assetPlaceholder = changeRequest.placeholderForCreatedAsset; |
||||
|
||||
} completionHandler:^(BOOL success, NSError * _Nullable error) { |
||||
NSLog(@"OK"); |
||||
//保存成功 |
||||
dispatch_async(dispatch_get_main_queue(), ^{ |
||||
|
||||
//通知外部一个略缩图 |
||||
[self generateThumbnailForVideoAtURL:videoURL]; |
||||
|
||||
}); |
||||
|
||||
}]; |
||||
} |
||||
``` |
||||
|
||||
\5. 生成一个略缩图通知外部 |
||||
|
||||
```text |
||||
///通过视频获取视频的第一帧图片当做略缩图 |
||||
- (void)generateThumbnailForVideoAtURL:(NSURL *)videoURL { |
||||
|
||||
dispatch_async(self.videoQueue, ^{ |
||||
|
||||
//拿到视频信息 |
||||
AVAsset *asset = [AVAsset assetWithURL:videoURL]; |
||||
AVAssetImageGenerator *imageGenerator = [AVAssetImageGenerator assetImageGeneratorWithAsset:asset]; |
||||
imageGenerator.maximumSize = CGSizeMake(100, 0); |
||||
imageGenerator.appliesPreferredTrackTransform = YES; |
||||
|
||||
//通过视频将第一帧图片数据转化为CGImage |
||||
CGImageRef imageRef = [imageGenerator copyCGImageAtTime:kCMTimeZero actualTime:NULL error:nil]; |
||||
UIImage *image = [UIImage imageWithCGImage:imageRef]; |
||||
|
||||
//通知外部 |
||||
NSNotificationCenter *nc = [NSNotificationCenter defaultCenter]; |
||||
[nc postNotificationName:ThumbnailCreatedNotification object:image]; |
||||
|
||||
}); |
||||
|
||||
|
||||
} |
||||
``` |
||||
|
||||
### **1.2、关于QuickTime** |
||||
|
||||
上文主要是通过AVCaptureMovieFileOutput将QuickTime影片捕捉到磁盘,这个类大多数核心功能继承与超类AVCaptureFileOutput。它有很多实用的功能,例如:录制到最长时限或录制到特定文件大小为止。 |
||||
|
||||
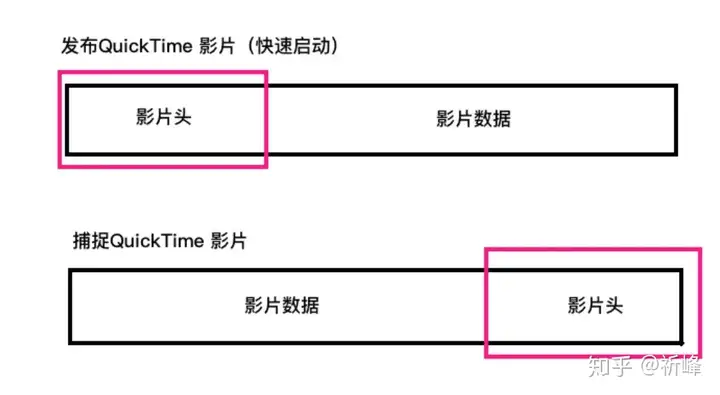
通常当QuickTime影片准备发布时,影片头的元数据处于文件的开始位置。这样可以让视频播放器快速读取头包含信息,来确定文件的内容、结构和其包含的多个样本的位置。当录制一个QuickTime影片时,直到所有的样片都完成捕捉后才能创建信息头。当录制结束时,创建头数据并将它附在文件结尾。 |
||||
|
||||
 |
||||
|
||||
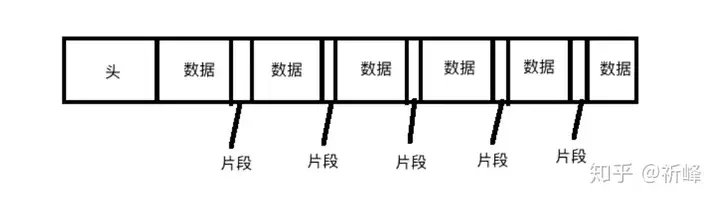
将创建头的过程放在所有影片样本完成捕捉之后存在一个问题。 在移动设备中,比如录制的时候接到电话或者程序崩溃等问题,影片头就不能被正确写入。会在磁盘生成一个不可读的影片文件。AVCaptureMovieFileOutput提供一个核心功能就是分段捕捉QuickTime影片。 |
||||
|
||||
 |
||||
|
||||
## 2、AVFoundation的人脸识别 |
||||
|
||||
人脸识别实际上是非常复杂的一个功能,要想自己完全实现人脸识别是非常困难的。苹果为我们做了很多人脸识别的功能,例如CoreImage、AVFoundation,都是有人脸识别的功能的。还有Vision face++ 等。这里就简单介绍一下AVFoundation中的人脸识别。 |
||||
|
||||
在拍摄视频中,我们通过AVFoundation的人脸识别,在屏幕界面上用一个红色矩形来标识识别到的人脸。 |
||||
|
||||
### **2.1、人脸识别流程** |
||||
|
||||
\1. 使用AVCaptureMetadataOutput来建立输出 |
||||
|
||||
\1. 添加进session |
||||
|
||||
\2. 设置获取数据类型 |
||||
|
||||
\3. 在主线程中执行任务 |
||||
|
||||
```text |
||||
- (BOOL)setupSessionOutputs:(NSError **)error { |
||||
//配置输入信息 |
||||
self.metadataOutput = [[AVCaptureMetadataOutput alloc] init]; |
||||
//对session添加输出 |
||||
if ([self.captureSession canAddOutput:self.metadataOutput]) { |
||||
[self.captureSession addOutput:self.metadataOutput]; |
||||
//从输出数据中设置只获取人脸数据(可以是人脸、二维码、一维码....) |
||||
NSArray *metadataObjectType = @[AVMetadataObjectTypeFace]; |
||||
self.metadataOutput.metadataObjectTypes = metadataObjectType; |
||||
|
||||
//因为人脸检测使用了硬件加速器GPU, 所以它的任务需要在主线程中执行 |
||||
dispatch_queue_t mainQueue = dispatch_get_main_queue(); |
||||
//设置metadataOutput代理方法, 检测视频中一帧一帧数据里是否包含人脸数据. 如果包含则调用回调方法 |
||||
[self.metadataOutput setMetadataObjectsDelegate:self queue:mainQueue]; |
||||
return YES; |
||||
} else { |
||||
//错误回调 |
||||
} |
||||
return NO; |
||||
} |
||||
``` |
||||
|
||||
\2. 实现相关代理方法,将捕捉到的人脸数据传递给layer层 |
||||
|
||||
```text |
||||
- (void)captureOutput:(AVCaptureOutput *)output didOutputMetadataObjects:(NSArray<__kindof AVMetadataObject *> *)metadataObjects fromConnection:(AVCaptureConnection *)connection { |
||||
|
||||
//metadataObjects包含了捕获到的人脸数据(人脸数据会重复, 会一直捕获人脸数据) |
||||
for (AVMetadataFaceObject *face in metadataObjects) { |
||||
NSLog(@"Face ID:%li",(long)face.faceID); |
||||
} |
||||
//将人脸数据通过代理发送给外部的layer层 |
||||
[self.faceDetectionDelegate didDetectFaces:metadataObjects]; |
||||
} |
||||
``` |
||||
|
||||
\3. 配置相关显示的图层。在layer层的视图中配置图层,我们在人脸四周添加一个矩形是在这个AVCaptureVideoPreviewLayer上进行一个个添加矩形。(因为人脸在识别过程中会出现旋转抖动等,需要进行一些3D转换等操作,后续也会出现此类操作,不在此篇作过多讲解) |
||||
|
||||
```text |
||||
- (void)setupView { |
||||
|
||||
//用来记录人脸图层 |
||||
self.faceLayers = [NSMutableDictionary dictionary]; |
||||
//图层的填充方式: 设置videoGravity 使用AVLayerVideoGravityResizeAspectFill 铺满整个预览层的边界范围 |
||||
self.previewLayer.videoGravity = AVLayerVideoGravityResizeAspectFill; |
||||
//在previewLayer上添加一个透明的图层 |
||||
self.overlayLayer = [CALayer layer]; |
||||
self.overlayLayer.frame = self.bounds; |
||||
//假设你的图层上的图形会发生3D变换, 设置投影方式 |
||||
self.overlayLayer.sublayerTransform = CATransform3DMakePerspective(1000); |
||||
[self.previewLayer addSublayer:self.overlayLayer]; |
||||
} |
||||
static CATransform3D CATransform3DMakePerspective(CGFloat eyePosition) { |
||||
//CATransform3D 图层的旋转,缩放,偏移,歪斜和应用的透 |
||||
//CATransform3DIdentity是单位矩阵,该矩阵没有缩放,旋转,歪斜,透视。该矩阵应用到图层上,就是设置默认值。 |
||||
CATransform3D transform = CATransform3DIdentity; |
||||
//透视效果(就是近大远小),是通过设置m34 m34 = -1.0/D 默认是0.D越小透视效果越明显 |
||||
//D:eyePosition 观察者到投射面的距离 |
||||
transform.m34 = -1.0/eyePosition; |
||||
|
||||
return transform; |
||||
} |
||||
``` |
||||
|
||||
\4. 处理通过代理传递过来的人脸数据 |
||||
|
||||
\1. 将人脸在摄像头中的坐标转化为屏幕坐标 |
||||
|
||||
\2. 定义一个数组,保存所有的人脸数据,用于存放待从屏幕上删除的人脸数据 |
||||
|
||||
\3. 遍历人脸数据 |
||||
|
||||
\1. 通过对比屏幕上的layer(框框)数量来与传递过来的人脸进行对比,判断是否需要移除layer(框框) |
||||
|
||||
\2. 根据人脸数据的ID来从屏幕上的layer(框框)中查找是否已经存在,不存在则需要生成一个layer(框框),并更新屏幕的layer(框框)数组。 |
||||
|
||||
\3. 根据传递过来的人脸数据来设置layer(框框)的位置,注意:当最后一个人脸离开屏幕,此时代理方法不会调用,会导致最后一个layer(框框)仍停留在屏幕上,所以需要处理一下人脸将要离开屏幕就对其进行移除处理。 |
||||
|
||||
\4. 在捕捉过程中,人脸会左右前后摆动(即z、y轴变化),来做不同的处理 |
||||
|
||||
\4. 遍历一下待删除数组,将之与传递过来的人脸数据进行对比,删除多余的人脸数据 |
||||
|
||||
注意:此处省略了一些3D转换的方法 |
||||
|
||||
```text |
||||
- (void)didDetectFaces:(NSArray *)faces { |
||||
//人脸数据位置信息(摄像头坐标系)转换为屏幕坐标系 |
||||
NSArray *transfromedFaces = [self transformedFacesFromFaces:faces]; |
||||
|
||||
//人脸消失, 删除图层 |
||||
|
||||
//需要删除的人脸数据列表 |
||||
NSMutableArray *lostFaces = [self.faceLayers.allValues mutableCopy]; |
||||
|
||||
//遍历每个人脸数据 |
||||
for (AVMetadataFaceObject *face in transfromedFaces) { |
||||
|
||||
//face ID |
||||
NSNumber *faceID = @(face.faceID); |
||||
//face ID存在即不需要删除(从删除列表中移除) |
||||
[lostFaces removeObject:faceID]; |
||||
|
||||
//假如有新的人脸加入 |
||||
CALayer *layer = self.faceLayers[faceID]; |
||||
if (!layer) { |
||||
NSLog(@"新增人脸"); |
||||
layer = [self makeFaceLayer]; |
||||
[self.overlayLayer addSublayer:layer]; |
||||
|
||||
//更新字典 |
||||
self.faceLayers[faceID] = layer; |
||||
} |
||||
|
||||
//根据人脸的bounds设置layer的frame |
||||
layer.frame = face.bounds; |
||||
CGSize size = self.bounds.size; |
||||
//当人脸特别靠近屏幕边缘, 直接当作无法识别此人脸(因为人脸离开屏幕不会走此代理方法, 需要提前做移除) |
||||
if (face.bounds.origin.x < 3 || |
||||
face.bounds.origin.x > size.width - layer.frame.size.width - 3 || |
||||
face.bounds.origin.y < 3 || |
||||
face.bounds.origin.y > size.height - layer.frame.size.height - 3 ) { |
||||
[layer removeFromSuperlayer]; |
||||
[self.faceLayers removeObjectForKey:faceID]; |
||||
} |
||||
|
||||
//设置3D属性(人脸是3D的, 需要根据人脸的3D变化做不同的变化处理) |
||||
layer.transform = CATransform3DIdentity; |
||||
//人脸z轴变化 |
||||
if (face.hasRollAngle) { |
||||
CATransform3D t = [self transformForRollAngle:face.rollAngle]; |
||||
//矩阵相乘 |
||||
layer.transform = CATransform3DConcat(layer.transform, t); |
||||
} |
||||
//人脸y轴变化 |
||||
if (face.hasYawAngle) { |
||||
CATransform3D t = [self transformForYawAngle:face.hasYawAngle]; |
||||
//矩阵相乘 |
||||
layer.transform = CATransform3DConcat(layer.transform, t); |
||||
} |
||||
} |
||||
//处理已经从镜头消失的人脸(人脸消失,图层并没有消失) |
||||
for (NSNumber *faceID in lostFaces) { |
||||
CALayer *layer = self.faceLayers[faceID]; |
||||
[self.faceLayers removeObjectForKey:faceID]; |
||||
[layer removeFromSuperlayer]; |
||||
} |
||||
} |
||||
``` |
||||
|
||||
### **2.1、其他类型数据的识别** |
||||
|
||||
有的同学在设置AVMetadataObjectTypeFace的可能会发现,还有会有一些其他的类型,例如AVMetadataObjectTypeQRCode等,就是从摄像头中捕获二维码数据,它的流程与人脸识别极度相似,甚至要更为简单一些,因为二维码并不像人脸一样需要做一些3D的转换等操作,所以此处不再示例捕捉二维码。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/222418988 |
||||
@ -0,0 +1,107 @@ |
||||
# iOS音视频同步探讨 |
||||
|
||||
## 1.音视频同步的原理 |
||||
|
||||
音视频采集的数据分别来自于麦克风与摄像头,而摄像头与麦克风其实是两个独立的硬件,而音视频同步的原理是相信摄像头与麦克风采集数据是实时的,并在采集到数据时给他们一个时间戳来标明数据所属的时间,而编码封装模块只要不改动音视频时间的相对关系就能保证音频与视频在时间上的对应。如此封装好数据之后,播放端就能够根据音视频的时间戳来播放对应的音视频,从实现音视频同步的效果。 |
||||
|
||||
## 2.时间戳参考标准 |
||||
|
||||
- 取格林威治时间做为对比标准,即音视频时间戳都为采集时间点相对于格林威治标准时间的时间差 |
||||
- 取系统开机时间做为对比标准,即音视频时间戳都是采集时间点相对于手机开机时间的时间差。目前iOS上AVCaptureSession这套API就是参考这个时间标准给的时间戳 |
||||
- 其它时间戳标准 |
||||
|
||||
## 3.基于“开源项目1”的音视频同步探讨 |
||||
|
||||
- 原生某开源框架 |
||||
|
||||
- - 如图: |
||||
|
||||
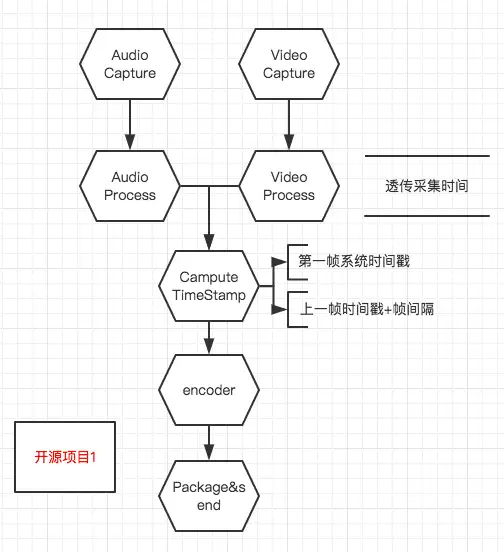 |
||||
|
||||
- - 简介 |
||||
|
||||
- - 音/视频被采集到之后会先经过音/视频处理模块,音/视频在被处理之后才进入计算时间戳的模块 |
||||
- 在第一帧到达时记一个计时起点,然后根据采集的帧间隔对接下来每一帧的时间戳进行计算:frameTimeStamp = lastFrameTimeStamp + frameDuration |
||||
|
||||
- 优点 |
||||
|
||||
- - 能输出**frame duration**稳定的音视频时间戳 |
||||
|
||||
- 风险 |
||||
|
||||
- - 无论是音频还是视频,在手机过热、性能不足等极端情况下有可能出现采集不稳定的情况,比如说预计1s采集30帧,实际只采集到28帧,而音视频的时间戳是通过累加来计算的,这样就有会出现音视频不同步的情况 |
||||
- **Video Process**(人脸检测、滤镜、3D贴纸)有可能无法在一帧时间内处理完当前帧,这样就会出现帧数比预期低的情况,从而出现音视频不同步 |
||||
- 帧间隔涉及到无限小数时,因为计算机的精度有限会引发的时间戳偏移,此偏移会随着帧数的增加而逐渐被放大 |
||||
|
||||
- 基于**开源项目1**的改进方案1 |
||||
|
||||
- - 如图: |
||||
|
||||
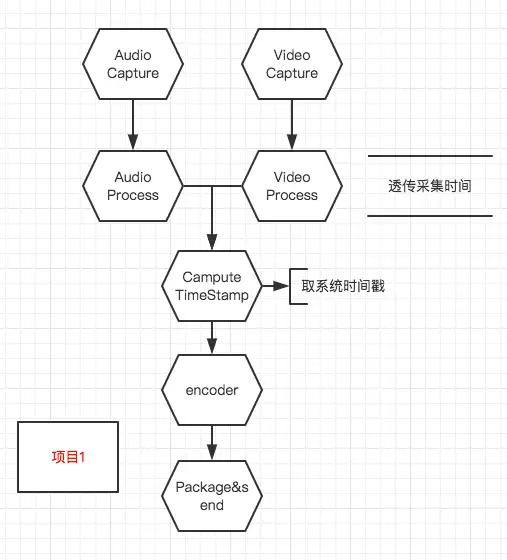 |
||||
|
||||
- 简介 |
||||
|
||||
- - - 音/视频被采集到之后会先经过音/视频处理模块,音/视频在被处理之后才进入计算时间戳的模块 |
||||
- 时间戳的获取方法非常直接——每一帧都在改帧进入时间戳计算模块时获取当前系统时间作为时间戳 |
||||
|
||||
- 优点: |
||||
|
||||
- - APP性能正常的情况下肯定不会出现音视频不同步 |
||||
- 能够实时纠正时间戳,只要APP正常运转,就能立即恢复正确的时间戳 |
||||
|
||||
- 风险: |
||||
|
||||
- - 依赖**Video Process**与**Audio Process**模块处理时长相近,而实际工程中因为人脸检测、贴纸等原因,**Video Process**可能会出现阻塞的情况,从而导致临时性的音视频不同步 |
||||
- 在**Audio Process**与**Video Process**模块处理帧耗时不均匀的情况下会出现音视频时间戳不均匀的问题,能否正常播放依赖于终端 |
||||
|
||||
- 基于**开源项目1**的一个改进方案2 |
||||
|
||||
- - 如图: |
||||
|
||||
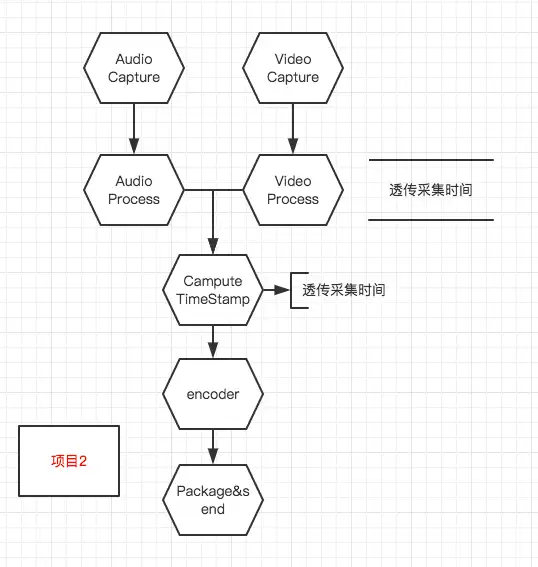 |
||||
|
||||
- 简介 |
||||
|
||||
- - - 音/视频被采集到之后,先获取采集模块提供的音视频时间戳,然后在音/视频处理模块透传采集模块获取到的音/视频时间戳,在时间戳计算模块继续透传采集模块给的时间戳 |
||||
|
||||
- 优点: |
||||
|
||||
- - 除非采集模块给出错误数据,否则音视频都一定是同步的 |
||||
|
||||
- 风险: |
||||
|
||||
- - 可能会出现音视频时间戳不均匀的情况,尤其是在手机过热、性能不足等极端情况下 |
||||
|
||||
- 直播方向更进一步的优化探讨 |
||||
|
||||
- - 大致流程如图: |
||||
|
||||
|
||||
|
||||
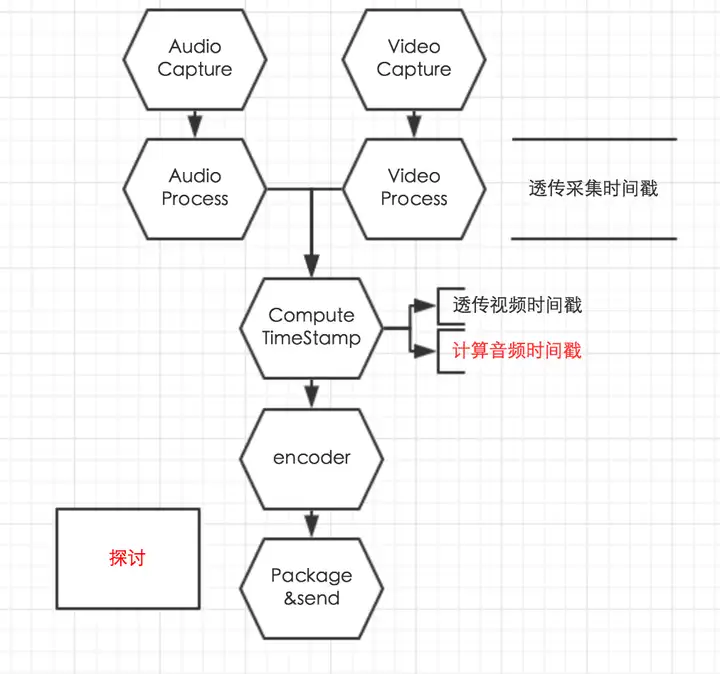 |
||||
|
||||
- 简介 |
||||
|
||||
- - - - 音/视频被采集到之后,先获取采集模块提供的音视频时间戳,然后在音/视频处理模块透传采集模块获取到的音/视频时间戳 |
||||
- 在时间戳计算模块透传视频时间戳,并根据下文中提到的方法计算音频时间戳 |
||||
|
||||
- 音频时间戳计算方法 |
||||
|
||||
- - 实时计算时间戳:当前时间戳=起始时间戳+帧数*帧采样数/采样率 |
||||
- 如果时间戳偏移量超出阈值,纠正时间戳 |
||||
- 纠正频率达到超出阈值,直接透传采集时间戳 |
||||
|
||||
- 优点: |
||||
|
||||
- - 能够提供一个稳定的音频时间戳,可以兼容帧间隔小幅抖动造成的音频时间戳不均匀 |
||||
- 兼容性能不足时导致实际采集帧数低于帧率 |
||||
|
||||
- 风险 |
||||
|
||||
- - 纠正时间戳时可能会造成声音卡顿的感觉 |
||||
|
||||
- 总结 |
||||
|
||||
- - 具体方案最好是针对实际应用场景有选择性的做优化,比如说,在可以控制播放器策略的情况,可以考虑根据自研播放器特性做时间戳处理。而如果播放器不可控,则尽量通过策略保障帧间隔稳定。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/28557179 |
||||
@ -0,0 +1,260 @@ |
||||
# iOS音视频开发-了解编码及视频 |
||||
|
||||
## 1. 视频H264编码 |
||||
|
||||
### 1.1 为何编码? |
||||
|
||||
从存储角度和网络传输以及通用性 3个角度,压缩已经成了不可或缺的动作.压缩编码最基本的指标,就是压缩比. 压缩比通常都是小于1(如果等于或者大于1,是不是就失去了编码的意义了.编码的目的就是为了压缩数据体量). |
||||
|
||||
### 1.2 何为编码? |
||||
|
||||
编码就是按照一定的格式记录采样和量化后的数据. |
||||
|
||||
#### 1.2.1编码中软编码和硬编码的区别? |
||||
|
||||
- 硬编码: 使用非CPU进行编码,例如使用GPU芯片处理 |
||||
- 软编码: 使用CPU来进行编码计算. |
||||
|
||||
#### 1.2.2 软编码与硬编码的区分? |
||||
|
||||
- 软编码: 实现直接、简单,参数调整方便,升级易,但CPU负载重,性能较硬编码低,低码率下质量通常比硬编码要好一点。 |
||||
- 硬编码:性能高,低码率下通常质量低于硬编码器,但部分产品在GPU硬件平台移植了优秀的软编码算法(如X264)的,质量基本等同于软编码。 |
||||
- 硬编码,就是使用GPU计算,获取数据结果,优点速度快,效率高.\ |
||||
- 软编码,就是通过CPU来计算,获取数据结果. |
||||
|
||||
#### 1.2.3 压缩算法 |
||||
|
||||
**压缩算法分为2种,有损压缩与无损压缩.** |
||||
|
||||
- 无损压缩:解压后的数据可以完全复原,在常用的压缩格式中,无损压缩使用频次较低 |
||||
- 有损压缩:解压后数据不能完全复原,会丢失一部分信息.压缩比越小,丢失的信息就会越多.信号还原的失真就会越大. |
||||
|
||||
**需要根据不同的场景(考虑因素包括存储设备,传输网络环境,播放设备等)选用不同的压缩编码算法.** |
||||
|
||||
### 1.3 VideoToolBox 硬编码 |
||||
|
||||
VideoToolbox 是一套纯C语言API。其中包含了很多C语言函数 |
||||
|
||||
VideoToolBox实际上属于低级框架,它是可以直接访问硬件编码器和解码器.它存在于视频压缩和解压缩以及存储在像素缓存区中的数据转换提供服务. |
||||
|
||||
**硬编码的优点:提高性能、增加效率、延长电量的使用** |
||||
|
||||
## 2.了解视频 |
||||
|
||||
 |
||||
|
||||
### 2.1视频的构成: |
||||
|
||||
- 图像 |
||||
- 音频 |
||||
- 元信息 |
||||
|
||||
**图像:** 视频内容本身就是一帧一帧的图片构成.人眼只要1秒钟连续播放16张以上的图片,就会认为这是一段连贯的视频.这种物理现象叫视觉暂留. |
||||
|
||||
**音频:** 视频一定是由音频+图像内容构成的.所以音频在视频中是单独的一个部分.针对这一块我们需要单独编码的. |
||||
|
||||
**元信息:** 元信息其实就是描述信息的信息.用于描述信息的结构\语义\用途\用法等.比如视频元信息就包含了视频的具体信息,比如编码格式,分辨率等等. |
||||
|
||||
### 2.2视频中的编码格式 |
||||
|
||||
- **视频编码格式** |
||||
|
||||
- - H264编码的优势: |
||||
|
||||
- - 低码率 |
||||
- 高质量的图像 |
||||
- 容错能力强 |
||||
- 网络适应性强 |
||||
|
||||
- **总结:** H264最大的优势,具有很高的数据压缩比率,在同等图像质量下,H264的压缩比是MPEG-2的2倍以上,MPEG-4的1.5~2倍. |
||||
|
||||
- **举例:** 原始文件的大小如果为88GB,采用MPEG-2压缩标准压缩后变成3.5GB,压缩比为25∶1,而采用H.264压缩标准压缩后变为879MB,从88GB到879MB,H.264的压缩比达到惊人的102∶1 |
||||
|
||||
- **音频编码格式:** |
||||
|
||||
- - AAC是目前比较热门的有损压缩编码技术,并且衍生了LC-AAC,HE-AAC,HE-AAC v2 三种主要编码格式. |
||||
|
||||
- - LC-AAC 是比较传统的AAC,主要应用于中高码率的场景编码(>= 80Kbit/s) |
||||
- HE-AAC 主要应用于低码率场景的编码(<= 48Kbit/s) |
||||
|
||||
- **优势**:在小于128Kbit/s的码率下表现优异,并且多用于视频中的音频编码 |
||||
|
||||
- **适合场景**:于128Kbit/s以下的音频编码,多用于视频中的音频轨的编码 |
||||
|
||||
### 2.3 容器(视频封装格式) |
||||
|
||||
**封装格式:** 就是将已经编码压缩好的视频数据 和音频数据按照一定的格式放到一个文件中.这个文件可以称为容器. 当然可以理解为这只是一个外壳. |
||||
|
||||
通常我们不仅仅只存放音频数据和视频数据,还会存放 一下视频同步的元数据.例如字幕.这多种数据会不同的程序来处理,但是它们在传输和存储的时候,这多种数据都是被绑定在一起的. |
||||
|
||||
- **常见的视频容器格式**: |
||||
|
||||
- - AVI: 是当时为对抗quicktime格式(mov)而推出的,只能支持固定CBR恒定定比特率编码的声音文件 |
||||
- MOV:是Quicktime封装 |
||||
- WMV:微软推出的,作为市场竞争 |
||||
- mkv:万能封装器,有良好的兼容和跨平台性、纠错性,可带外挂字幕 |
||||
- flv: 这种封装方式可以很好的保护原始地址,不容易被下载到,目前一些视频分享网站都采用这种封装方式 |
||||
- MP4:主要应用于mpeg4的封装,主要在手机上使用。 |
||||
|
||||
## 3.视频压缩的可能性 |
||||
|
||||
视频压缩,该从那几个方向去进行数据的压缩了? 实际上压缩的本质都是从冗余信息开始出发压缩的. 而视频数据之间是有极强的相关性.也就是这样会产生大量的冗余信息.这样的冗余包括空间上的冗余信息和时间上的冗余信息. |
||||
|
||||
- **使用帧间编码技术可以去除时间上的冗余信息,具体包括如下** |
||||
|
||||
- - **运动补偿**: 运动补偿是通过先前的局部图形来预测,补偿当前的局部图像.它是减少帧序列冗余信息很有效的方法. |
||||
- **运动表示**: 不同区域的图像需要使用不同的运动矢量来描述运动信息 |
||||
- **运动估计**: 运动估计就是从视频序列中抽取运动信息的一整套技术. |
||||
|
||||
### 3.1 编码概念 |
||||
|
||||
**IPB帧** |
||||
视频压缩中,每帧代表着一副静止的图像.而进行实际压缩时,会采用各种算法以减少数据的容量.其实IPB帧是最常用的一种方式: |
||||
|
||||
- **I帧**:**关键帧,采用帧内压缩技术**.帧内编码帧(intra picture),I帧通常是每个GOP(MPEG所使用的一种视频压缩技术)的第一帧.经过适度的压缩.作为随机访问的参考点,可以当做静态图像.I帧可以看做一个图像经过压缩后的产物.I帧压缩可以得到6:1的压缩比而不会产生任何可察觉的模糊现象.I帧压缩去除了视频空间的冗余信息. |
||||
- **P帧**:**向前参考帧.压缩时只参考前一个帧.属于帧间压缩技术**. 前后预测编码帧(predictive-frame),通过将图像序列中前面已编码帧的时间冗余信息充分去除来压缩传输数据量的编码图像. |
||||
- **B帧**:**双向参考帧,压缩时即参考前一帧也参考后一帧.帧间压缩技术.** 双向预测编码帧(bi-directional interpolated prediction frame),既要考虑源图像序列前面已编码帧,又要顾及源图像序列后面的已编码帧之间的时间冗余信息,来压缩传输数据量的编码图像. |
||||
|
||||
**读者角度解读** |
||||
|
||||
- **I帧**,自身可以通过视频解码算法解压成一张单独的完整的视频画面.所以I帧去掉的是视频帧在空间维度上的冗余信息. |
||||
- **P帧**,需要参考前面的一个I帧或P帧解码成一个完整的视频画面 |
||||
- **B帧**,需要参考前面的一个I帧或者P帧以及后面的一个P帧来生成一个完整的视频画面. |
||||
- **所以,P和B帧去掉的视频帧在时间上维度上的冗余信息**. |
||||
|
||||
### 3.2 解码中PTS 与 DTS |
||||
|
||||
**DTS(Decoding Time Stamp)** ,主要用于视频的解码; |
||||
**PTS(Presentation Time Stamp)** ,主要用于解码节点进行视频的同步和输出. |
||||
|
||||
在没有B帧的情况下,DTS和PST的输出顺序是一样的.因为B帧会打乱了解码和显示顺序.所以一旦存在B帧,PTS和DTS势必会不同.实际上在大多数编解码标准中,编码顺序和输入顺序并不一致.于是需要PTS和DST这2种不同的时间戳. |
||||
|
||||
### 3.3 GOP概念 |
||||
|
||||
**两个I帧之间形成的一组图片,就是GOP(Group of Picture).** |
||||
通常在编码器设置参数时,必须会设置gop_size的值.其实就是代表2个I帧之间的帧数目. 在一个GOP组中容量最大的就是I帧.所以相对而言,gop_size设置的越大,整个视频画面质量就会越好.但是解码端必须从接收的第一个I帧开始才可以正确解码出原始图像.否则无法正确解码. 如果在一秒钟内,有30帧.这30帧可以画成一组.如果摄像机或者镜头它一分钟之内它都没有发生大的变化.那也可以把这一分钟内所有的帧画做一组. |
||||
|
||||
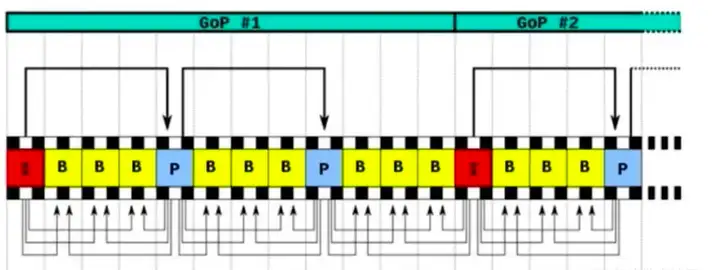 |
||||
|
||||
**一组帧**就是一个I帧到下一个I帧.这一组的数据.包括B帧/P帧. |
||||
|
||||
### 3.3 SPS/PPS |
||||
|
||||
SPS/PPS实际上就是存储GOP的参数. |
||||
|
||||
**SPS: (Sequence Parameter Set,序列参数集)存放帧数,参考帧数目,解码图像尺寸,帧场编码模式选择标识等**. |
||||
|
||||
- 一组帧的参数集. |
||||
|
||||
**PPS:(Picture Parameter Set,图像参数集).存放熵编码模式选择标识,片组数目,初始量化参数和去方块滤波系数调整标识等.(与图像相关的信息)** |
||||
|
||||
在一组帧之前我们首先收到的是SPS/PPS数据.如果没有这组参数的话,我们是无法解码. |
||||
|
||||
如果我们在解码时发生错误,首先要检查是否有SPS/PPS.如果没有,是因为对端没有发送过来还是因为对端在发送过程中丢失了. |
||||
|
||||
SPS/PPS数据,我们也把其归类到I帧.这2组数据是绝对不能丢的. |
||||
|
||||
## 4. 视频花屏/卡顿原因 |
||||
|
||||
我们在观看视频时,会遇到花屏或者卡顿现象.那这个与我们刚刚所讲的GOF就息息相关了. |
||||
|
||||
- 如果GOP分组中的P帧丢失就会造成解码端的图像发生错误. |
||||
- 为了避免花屏问题的发生,一般如果发现P帧或者I帧丢失.就不显示本GOP内的所有帧.只到下一个I帧来后重新刷新图像. |
||||
- 当这时因为没有刷新屏幕.丢包的这一组帧全部扔掉了.图像就会卡在哪里不动.这就是卡顿的原因. |
||||
|
||||
**所以总结起来,花屏是因为你丢了P帧或者I帧.导致解码错误. 而卡顿是因为为了怕花屏,将整组错误的GOP数据扔掉了.直达下一组正确的GOP再重新刷屏.而这中间的时间差,就是我们所感受的卡顿.** |
||||
|
||||
## 5.颜色模型 |
||||
|
||||
我们开发场景中使用最多的应该是 RGB 模型 |
||||
|
||||
 |
||||
|
||||
在 RGB 模型中每种颜色需要 3 个数字,分别表示 R、G、B,比如 (255, 0, 0) 表示红色,通常一个数字占用 1 字节,那么表示一种颜色需要 24 bits。那么有没有更高效的颜色模型能够用更少的 bit 来表示颜色呢? |
||||
|
||||
现在我们假设我们定义一个**「亮度(Luminance)」**的概念来表示颜色的亮度,那它就可以用含 R、G、B 的表达式表示为: |
||||
|
||||
```text |
||||
Y = kr*R + kg*G + kb*B |
||||
``` |
||||
|
||||
Y 即「亮度」,kr、kg、kb 即 R、G、B 的权重值。 |
||||
|
||||
这时,我们可以定义一个**「色度(Chrominance)」**的概念来表示颜色的差异: |
||||
|
||||
```text |
||||
Cr = R – Y |
||||
Cg = G – Y |
||||
Cb = B – Y |
||||
``` |
||||
|
||||
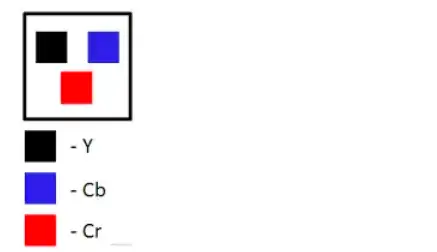
Cr、Cg、Cb 分别表示在 R、G、B 上的色度分量。上述模型就是 **YCbCr** 颜色模型基本原理。 |
||||
|
||||
**YCbCr** 是属于 **YUV** 家族的一员,是在计算机系统中应用最为广泛的颜色模型,就比如在本文所讲的视频领域。***在 YUV 中 Y 表示的是「亮度」,也就是灰阶值,U 和 V 则是表示「色度」。\*** |
||||
|
||||
**YUV 的关键是在于它的亮度信号 Y 和色度信号 U、V 是分离的。那就是说即使只有 Y 信号分量而没有 U、V 分量,我们仍然可以表示出图像,只不过图像是黑白灰度图像**。在YCbCr 中 Y 是指亮度分量,Cb 指蓝色色度分量,而 Cr 指红色色度分量。 |
||||
|
||||
现在我们从 ITU-R BT.601-7 标准中拿到推荐的相关系数,就可以得到 YCbCr 与 RGB 相互转换的公式 |
||||
|
||||
```text |
||||
Y = 0.299R + 0.587G + 0.114B |
||||
Cb = 0.564(B - Y) |
||||
Cr = 0.713(R - Y) |
||||
R = Y + 1.402Cr |
||||
G = Y - 0.344Cb - 0.714Cr |
||||
B = Y + 1.772Cb |
||||
``` |
||||
|
||||
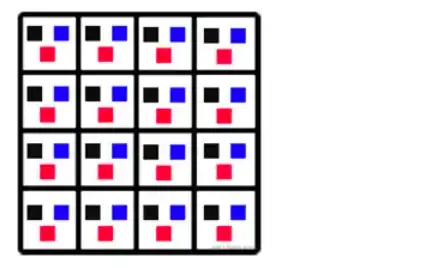
这样对于 **YCbCr** 这个颜色模型我们就有个初步认识了,但是我们会发现,这里 **YCbCr** 也仍然用了 3 个数字来表示颜色啊,有节省 **bit** 吗?为了回答这个问题,我们来结合视频中的图像和图像中的像素表示来说明 |
||||
|
||||
- 假设图片有如下像素组成 |
||||
|
||||
 |
||||
|
||||
一副图片就是一个像素阵列.每个像素的 3 个分量的信息是完整的,**YCbCr 4:4:4**。 |
||||
|
||||
 |
||||
|
||||
下图中,对于每个像素点都保留「亮度」值,但是省略每行中偶素位像素点的「色度」值,从而节省了 bit。**YCbCr4:2:2** |
||||
|
||||
 |
||||
|
||||
上图,做了更多的省略,但是对图片质量的影响却不会太大.**YCbCr4:2:0** |
||||
|
||||
 |
||||
|
||||
## 6. 音频编码 |
||||
|
||||
常用压缩编码格式 |
||||
|
||||
WAV编码 |
||||
|
||||
WAV编码的一种实现方式(其实它有非常多实现方式,但都是不会进行压缩操作).就是在源PCM数据格式的前面加上44个字节.分别用来描述PCM的采样率,声道数,数据格式等信息. |
||||
|
||||
- 特点:音质非常好,大量软件都支持其播放 |
||||
- 适合场合:多媒体开发的中间文件,保存音乐和音效素材 |
||||
|
||||
MP3编码 |
||||
|
||||
MP3编码具有不错的压缩比,而且听感也接近于WAV文件,当然在不同的环境下,应该调整合适的参数来达到更好的效果. |
||||
|
||||
- 特点:音质在128Kbit/s以上表现不错,压缩比比较高.大量软件和硬件都支持.兼容性高. |
||||
- 适合场合:高比特率下对兼容性有要求的音乐欣赏. |
||||
|
||||
AAC编码 |
||||
|
||||
AAC是目前比较热门的有损压缩编码技术,并且衍生了LC-AAC,HE-AAC,HE-AAC v2 三种主要编码格式. |
||||
|
||||
- LC-AAC 是比较传统的AAC,主要应用于中高码率的场景编码(>= 80Kbit/s) |
||||
- HE-AAC 主要应用于低码率场景的编码(<= 48Kbit/s) |
||||
- 特点:在小于128Kbit/s的码率下表现优异,并且多用于视频中的音频编码 |
||||
- 适合场景:于128Kbit/s以下的音频编码,多用于视频中的音频轨的编码 |
||||
|
||||
Ogg编码 |
||||
|
||||
Ogg编码是一种非常有潜力的编码,在各种码率下都有比较优秀的表现.尤其在低码率场景下.Ogg除了音质好之外,Ogg的编码算法也是非常出色.可以用更小的码率达到更好的音质.128Kbit/s的Ogg比192Kbit/s甚至更高码率的MP3更优质.但目前由软件还是硬件支持问题,都没法达到与MP3的使用广度. |
||||
|
||||
- 特点:可以用比MP3更小的码率实现比MP3更好的音质,高中低码率下均有良好的表现,兼容不够好,流媒体特性不支持. |
||||
- 适合场景:语言聊天的音频消息场景 |
||||
|
||||
原文地址:[iOS音视频开发-了解编码及视频 - 资料 - 我爱音视频网 - 构建全国最权威的音视频技术交流分享论坛]( |
||||
@ -0,0 +1,288 @@ |
||||
# iOS音视频开发——视频采集 |
||||
|
||||
## 1.认识 AVCapture 系列 |
||||
|
||||
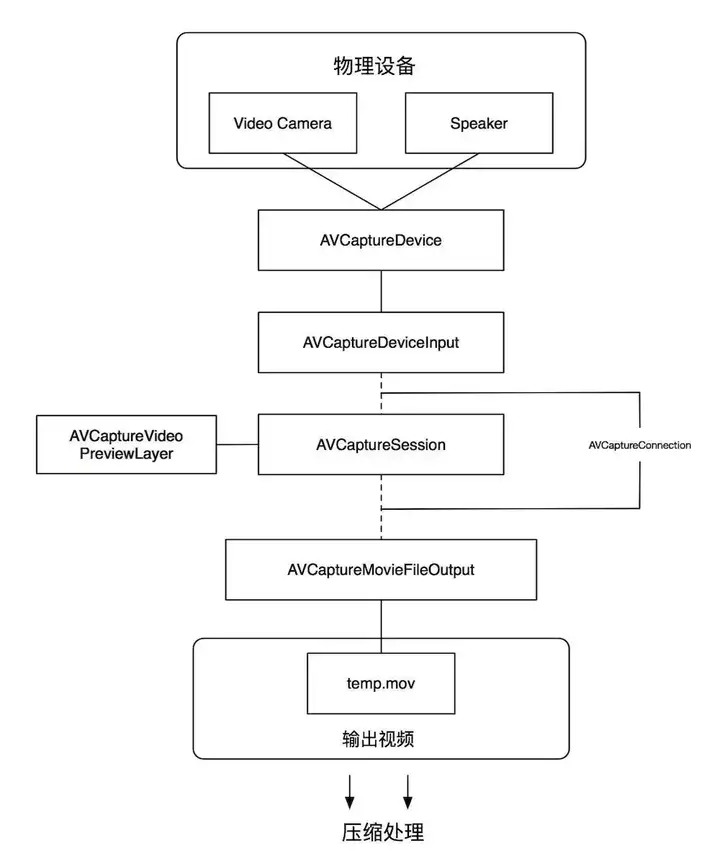
AVCapture 系列是 AVFoundation 框架为我们提供的用于管理输入设备、采集、输出、预览等一系列接口,其工作原理如下: |
||||
|
||||
 |
||||
|
||||
\1. AVCaptureDevice: 信号采集硬件设备(摄像头、麦克风、屏幕等) |
||||
`AVCaptureDevice` 代表硬件设备,并且为 `AVCaptureSession` 提供 input,要想使用 `AVCaptureDevice`,应该先将设备支持的 `device` 枚举出来, 根据摄像头的位置( 前置或者后置摄像头 )获取需要用的那个摄像头, 再使用; |
||||
如果想要对 `AVCaptureDevice` 对象的一些属性进行设置,应该先调用 `lockForConfiguration:` 方法, 设置结束后,调用 `unlockForConfiguration` 方法; |
||||
|
||||
```text |
||||
[self.device lockForConfiguration:&error]; |
||||
// 设置 *** |
||||
[self.device unlockForConfiguration]; |
||||
``` |
||||
|
||||
## 2. AVCaptureInput: 输入数据管理 |
||||
|
||||
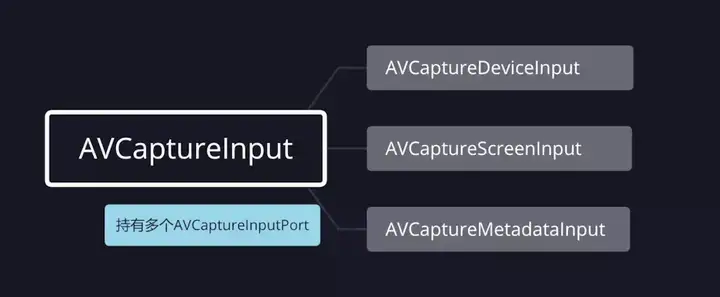
AVCaptureInput 继承自 `NSObject`,是向 `AVCaptureSession` 提供输入数据的对象的抽象超类; |
||||
要将 `AVCaptureInput` 对象与会话 `AVCaptureSession` 关联,需要 `AVCaptureSession`实例调用 `-addInput:` 方法。 |
||||
由于 `AVCaptureInput` 是个抽象类,无法直接使用,所以我们一般使用它的子类类管理输入数据。我们常用的 `AVCaptureInput` 的子类有三个: |
||||
|
||||
 |
||||
|
||||
`AVCaptureDeviceInput`:用于从 `AVCaptureDevice` 对象捕获数据; |
||||
`AVCaptureScreenInput`:从 macOS 屏幕上录制的一种捕获输入; |
||||
`AVCaptureMetadataInput`:它为 `AVCaptureSession` 提供 `AVMetadataItems`。 |
||||
|
||||
## 3. AVCaptureOutput:输出数据管理 |
||||
|
||||
AVCaptureOutput 继承自 `NSObject`,是输出数据管理,该对象将会被添加到会话`AVCaptureSession`中,用于接收会话`AVCaptureSession`各类输出数据; `AVCaptureOutput`提供了一个抽象接口,用于将捕获输出数据(如文件和视频预览)连接到捕获会话`AVCaptureSession`的实例,捕获输出可以有多个由`AVCaptureConnection`对象表示的连接,一个连接对应于它从捕获输入(`AVCaptureInput`的实例)接收的每个媒体流,捕获输出在首次创建时没有任何连接,当向捕获会话添加输出时,将创建连接,将该会话的输入的媒体数据映射到其输出,调用`AVCaptureSession`的`-addOutput:`方法将`AVCaptureOutput`与`AVCaptureSession`关联。 |
||||
`AVCaptureOutput` 是个抽象类,我们必须使用它的子类,常用的 `AVCaptureOutput`的子类如下所示: |
||||
|
||||
 |
||||
|
||||
`AVCaptureAudioDataOutput`:一种捕获输出,用于记录音频,并在录制音频时提供对音频样本缓冲区的访问; |
||||
`AVCaptureAudioPreviewOutput` :一种捕获输出,与一个核心音频输出设备相关联、可用于播放由捕获会话捕获的音频; |
||||
`AVCaptureDepthDataOutput` :在兼容的摄像机设备上记录场景深度信息的捕获输出; |
||||
`AVCaptureMetadataOutput` :用于处理捕获会话 `AVCaptureSession` 产生的定时元数据的捕获输出; |
||||
`AVCaptureStillImageOutput`:在macOS中捕捉静止照片的捕获输出。该类在 iOS 10.0 中被弃用,并且不支持新的相机捕获功能,例如原始图像输出和实时照片,在 iOS 10.0 或更高版本中,使用 `AVCapturePhotoOutput` 类代替; |
||||
`AVCapturePhotoOutput` :静态照片、动态照片和其他摄影工作流的捕获输出; |
||||
`AVCaptureVideoDataOutput` :记录视频并提供对视频帧进行处理的捕获输出; |
||||
`AVCaptureFileOutput`:用于捕获输出的抽象超类,可将捕获数据记录到文件中; |
||||
`AVCaptureMovieFileOutput` :继承自 `AVCaptureFileOutput`,将视频和音频记录到 QuickTime 电影文件的捕获输出; |
||||
`AVCaptureAudioFileOutput` :继承自 `AVCaptureFileOutput`,记录音频并将录制的音频保存到文件的捕获输出。 |
||||
|
||||
## 4. AVCaptureSession: |
||||
|
||||
用来管理采集数据和输出数据,它负责协调从哪里采集数据,输出到哪里,它是整个Capture的核心,类似于RunLoop,它不断的从输入源获取数据,然后分发给各个输出源 |
||||
AVCaptureSession 继承自`NSObject`,是`AVFoundation`的核心类,用于管理捕获对象`AVCaptureInput`的视频和音频的输入,协调捕获的输出`AVCaptureOutput` |
||||
|
||||
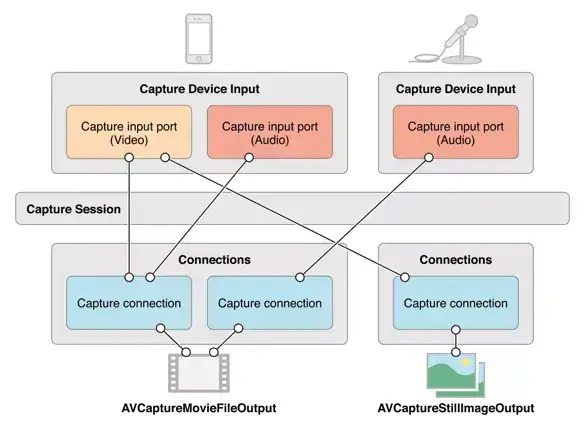 |
||||
|
||||
## 5. AVCaptureConnection: |
||||
|
||||
用于 `AVCaptureSession` 来建立和维护 `AVCaptureInput` 和 `AVCaptureOutput` 之间的连接 |
||||
AVCaptureConnection 是 `Session` 和 `Output` 中间的控制节点,每个 `Output` 与 `Session` 建立连接后,都会分配一个默认的 `AVCpatureConnection`。 |
||||
|
||||
|
||||
|
||||
## 6. AVCapturePreviewLayer: |
||||
|
||||
预览层,`AVCaptureSession` 的一个属性,继承自 `CALayer`,提供摄像头的预览功能,照片以及视频就是通过把 `AVCapturePreviewLayer` 添加到 `UIView` 的 `layer` 上来显示 |
||||
|
||||
开始视频采集 |
||||
1、创建并初始化输入`AVCaptureInput`: `AVCaptureDeviceInput` 和输出`AVCaptureOutput`: `AVCaptureVideoDataOutput`; |
||||
2、创建并初始化 `AVCaptureSession`,把 `AVCaptureInput` 和 `AVCaptureOutput` 添加到 `AVCaptureSession` 中; |
||||
3、调用 `AVCaptureSession` 的 `startRunning` 开启采集 |
||||
初始化输入 |
||||
通过 `AVCaptureDevice` 的 `devicesWithMediaType:` 方法获取摄像头,iPhone 都是有前后摄像头的,这里获取到的是一个设备的数组,要从数组里面拿到我们想要的前摄像头或后摄像头,然后将 `AVCaptureDevice` 转化为 `AVCaptureDeviceInput`,添加到 `AVCaptureSession`中 |
||||
|
||||
```text |
||||
/************************** 设置输入设备 *************************/ |
||||
// --- 获取所有摄像头 --- |
||||
NSArray *cameras = [AVCaptureDevice devicesWithMediaType:AVMediaTypeVideo]; |
||||
// --- 获取当前方向摄像头 --- |
||||
NSArray *captureDeviceArray = [cameras filteredArrayUsingPredicate:[NSPredicate predicateWithFormat:@"position == %d", _capturerParam.devicePosition]]; |
||||
|
||||
if (captureDeviceArray.count == 0) { |
||||
return nil; |
||||
} |
||||
|
||||
// --- 转化为输入设备 --- |
||||
AVCaptureDevice *camera = captureDeviceArray.firstObject; |
||||
self.captureDeviceInput = [AVCaptureDeviceInput deviceInputWithDevice:camera |
||||
error:&error]; |
||||
|
||||
``` |
||||
|
||||
设置视频采集参数 |
||||
|
||||
```text |
||||
@implementation VideoCapturerParam |
||||
|
||||
- (instancetype)init { |
||||
self = [super init]; |
||||
if (self) { |
||||
_devicePosition = AVCaptureDevicePositionFront; // 摄像头位置,默认为前置摄像头 |
||||
_sessionPreset = AVCaptureSessionPreset1280x720; // 视频分辨率 默认 AVCaptureSessionPreset1280x720 |
||||
_frameRate = 15; // 帧 单位为 帧/秒,默认为15帧/秒 |
||||
_videoOrientation = AVCaptureVideoOrientationPortrait; // 摄像头方向 默认为当前手机屏幕方向 |
||||
|
||||
switch ([UIDevice currentDevice].orientation) { |
||||
case UIDeviceOrientationPortrait: |
||||
case UIDeviceOrientationPortraitUpsideDown: |
||||
_videoOrientation = AVCaptureVideoOrientationPortrait; |
||||
break; |
||||
|
||||
case UIDeviceOrientationLandscapeRight: |
||||
_videoOrientation = AVCaptureVideoOrientationLandscapeRight; |
||||
break; |
||||
|
||||
case UIDeviceOrientationLandscapeLeft: |
||||
_videoOrientation = AVCaptureVideoOrientationLandscapeLeft; |
||||
break; |
||||
|
||||
default: |
||||
break; |
||||
} |
||||
} |
||||
|
||||
return self; |
||||
} |
||||
``` |
||||
|
||||
初始化输出 |
||||
初始化视频输出 `AVCaptureVideoDataOutput`,并设置视频数据格式,设置采集数据回调线程,这里视频输出格式选的是 kCVPixelFormatType_420YpCbCr8BiPlanarFullRange,YUV 数据格式 |
||||
|
||||
```text |
||||
/************************** 设置输出设备 *************************/ |
||||
// --- 设置视频输出 --- |
||||
self.captureVideoDataOutput = [[AVCaptureVideoDataOutput alloc] init]; |
||||
|
||||
NSDictionary *videoSetting = [NSDictionary dictionaryWithObjectsAndKeys:[NSNumber numberWithInt:kCVPixelFormatType_420YpCbCr8BiPlanarVideoRange], kCVPixelBufferPixelFormatTypeKey, nil]; // kCVPixelFormatType_420YpCbCr8BiPlanarVideoRange 表示输出的视频格式为NV12 |
||||
[self.captureVideoDataOutput setVideoSettings:videoSetting]; |
||||
|
||||
// --- 设置输出串行队列和数据回调 --- |
||||
dispatch_queue_t outputQueue = dispatch_queue_create("VideoCaptureOutputQueue", DISPATCH_QUEUE_SERIAL); |
||||
// --- 设置代理 --- |
||||
[self.captureVideoDataOutput setSampleBufferDelegate:self queue:outputQueue]; |
||||
// --- 丢弃延迟的帧 --- |
||||
self.captureVideoDataOutput.alwaysDiscardsLateVideoFrames = YES; |
||||
``` |
||||
|
||||
**初始化 AVCaptureSession 并设置输入输出** |
||||
1、初始化 `AVCaptureSession`,把上面的输入和输出加进来,在添加输入和输出到 `AVCaptureSession` 先查询一下 `AVCaptureSession` 是否支持添加该输入或输出端口; |
||||
2、设置视频分辨率及图像质量(AVCaptureSessionPreset),设置之前同样需要先查询一下 `AVCaptureSession` 是否支持这个分辨率; |
||||
3、如果在已经开启采集的情况下需要修改分辨率或输入输出,需要用 `beginConfiguration` 和`commitConfiguration` 把修改的代码包围起来。在调用 `beginConfiguration` 后,可以配置分辨率、输入输出等,直到调用 `commitConfiguration` 了才会被应用; |
||||
4、`AVCaptureSession` 管理了采集过程中的状态,当开始采集、停止采集、出现错误等都会发起通知,我们可以监听通知来获取 `AVCaptureSession` 的状态,也可以调用其属性来获取当前 `AVCaptureSession` 的状态, `AVCaptureSession` 相关的通知都是在主线程的。 |
||||
|
||||
前置摄像头采集到的画面是翻转的,若要解决画面翻转问题,需要设置 `AVCaptureConnection` 的 `videoMirrored` 为 YES。 |
||||
|
||||
```text |
||||
/************************** 初始化会话 *************************/ |
||||
self.captureSession = [[AVCaptureSession alloc] init]; |
||||
self.captureSession.usesApplicationAudioSession = NO; |
||||
|
||||
// --- 添加输入设备到会话 --- |
||||
if ([self.captureSession canAddInput:self.captureDeviceInput]) { |
||||
[self.captureSession addInput:self.captureDeviceInput]; |
||||
} |
||||
else { |
||||
NSLog(@"VideoCapture:: Add captureVideoDataInput Faild!"); |
||||
return nil; |
||||
} |
||||
|
||||
// --- 添加输出设备到会话 --- |
||||
if ([self.captureSession canAddOutput:self.captureVideoDataOutput]) { |
||||
[self.captureSession addOutput:self.captureVideoDataOutput]; |
||||
} |
||||
else { |
||||
NSLog(@"VideoCapture:: Add captureVideoDataOutput Faild!"); |
||||
return nil; |
||||
} |
||||
|
||||
// --- 设置分辨率 --- |
||||
if ([self.captureSession canSetSessionPreset:self.capturerParam.sessionPreset]) { |
||||
self.captureSession.sessionPreset = self.capturerParam.sessionPreset; |
||||
} |
||||
|
||||
/************************** 初始化连接 *************************/ |
||||
self.captureConnection = [self.captureVideoDataOutput connectionWithMediaType:AVMediaTypeVideo]; |
||||
|
||||
// --- 设置摄像头镜像,不设置的话前置摄像头采集出来的图像是反转的 --- |
||||
if (self.capturerParam.devicePosition == AVCaptureDevicePositionFront && self.captureConnection.supportsVideoMirroring) { // supportsVideoMirroring 视频是否支持镜像 |
||||
self.captureConnection.videoMirrored = YES; |
||||
} |
||||
|
||||
self.captureConnection.videoOrientation = self.capturerParam.videoOrientation; |
||||
|
||||
self.videoPreviewLayer = [AVCaptureVideoPreviewLayer layerWithSession:self.captureSession]; |
||||
self.videoPreviewLayer.connection.videoOrientation = self.capturerParam.videoOrientation; |
||||
self.videoPreviewLayer.videoGravity = AVLayerVideoGravityResizeAspectFill; |
||||
``` |
||||
|
||||
采集视频 / 回调 |
||||
|
||||
```text |
||||
/** |
||||
* 开始采集 |
||||
*/ |
||||
- (NSError *)startCpture { |
||||
if (self.isCapturing) { |
||||
return [NSError errorWithDomain:@"VideoCapture:: startCapture faild: is capturing" code:1 userInfo:nil]; |
||||
} |
||||
|
||||
// --- 摄像头权限判断 --- |
||||
AVAuthorizationStatus videoAuthStatus = [AVCaptureDevice authorizationStatusForMediaType:AVMediaTypeVideo]; |
||||
|
||||
if (videoAuthStatus != AVAuthorizationStatusAuthorized) { |
||||
return [NSError errorWithDomain:@"VideoCapture:: Camera Authorizate faild!" code:1 userInfo:nil]; |
||||
} |
||||
|
||||
[self.captureSession startRunning]; |
||||
self.isCapturing = YES; |
||||
|
||||
kLOGt(@"开始采集视频"); |
||||
|
||||
return nil; |
||||
} |
||||
|
||||
|
||||
/** |
||||
* 停止采集 |
||||
*/ |
||||
- (NSError *)stopCapture { |
||||
if (!self.isCapturing) { |
||||
return [NSError errorWithDomain:@"VideoCapture:: stop capture faild! is not capturing!" code:1 userInfo:nil]; |
||||
} |
||||
|
||||
[self.captureSession stopRunning]; |
||||
self.isCapturing = NO; |
||||
|
||||
kLOGt(@"停止采集视频"); |
||||
|
||||
return nil; |
||||
} |
||||
|
||||
#pragma mark ————— AVCaptureVideoDataOutputSampleBufferDelegate ————— |
||||
/** |
||||
* 摄像头采集数据回调 |
||||
@prama output 输出设备 |
||||
@prama sampleBuffer 帧缓存数据,描述当前帧信息 |
||||
@prama connection 连接 |
||||
*/ |
||||
- (void)captureOutput:(AVCaptureOutput *)output didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection { |
||||
if ([self.delagate respondsToSelector:@selector(videoCaptureOutputDataCallback:)]) { |
||||
[self.delagate videoCaptureOutputDataCallback:sampleBuffer]; |
||||
} |
||||
} |
||||
``` |
||||
|
||||
## 7.调用 / 获取数据 |
||||
|
||||
调用很简单,初始化视频采集参数 `VideoCapturerParam` 和 视频采集器 `VideoVapturer` , 设置预览图层 `videoPreviewLayer` , 调用 `startCpture` 就可以开始采集了,然后实现数据采集回调的代理方法 `videoCaptureOutputDataCallback` 获取数据 |
||||
|
||||
```text |
||||
// --- 初始化视频采集参数 --- |
||||
VideoCapturerParam *param = [[VideoCapturerParam alloc] init]; |
||||
|
||||
// --- 初始化视频采集器 --- |
||||
self.videoCapture = [[VideoVapturer alloc] initWithCaptureParam:param error:nil]; |
||||
self.videoCapture.delagate = self; |
||||
|
||||
// --- 开始采集 --- |
||||
[self.videoCapture startCpture]; |
||||
|
||||
|
||||
// --- 初始化预览View --- |
||||
self.recordLayer = self.videoCapture.videoPreviewLayer; |
||||
self.recordLayer.frame = CGRectMake(0, 0, CGRectGetWidth(self.view.bounds), CGRectGetHeight(self.view.bounds)); |
||||
[self.view.layer addSublayer:self.recordLayer]; |
||||
``` |
||||
|
||||
|
||||
|
||||
```text |
||||
#pragma mark ————— VideoCapturerDelegate ————— 视频采集回调 |
||||
- (void)videoCaptureOutputDataCallback:(CMSampleBufferRef)sampleBuffer { |
||||
NSLog(@"%@ sampleBuffer : %@ ", kLOGt(@"视频采集回调"), sampleBuffer); |
||||
} |
||||
``` |
||||
|
||||
至此,我们就完成了视频的采集,在采集前和过程中,我们可能会对采集参数、摄像头方向、帧率等进行修改。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/485646912 |
||||
@ -0,0 +1,228 @@ |
||||
# iOS高级视频渲染 |
||||
|
||||
## 1.前言 |
||||
|
||||
今天为大家介绍一下 iOS 下 WebRTC是如何渲染视频的。在iOS中有两种加速渲染视频的方法。一种是使用OpenGL;另一种是使用 Metal。 |
||||
|
||||
OpenGL的好处是跨平台,推出时间比较长,因此比较稳定。兼容性也比较好。而Metal是iOS最近才推出的技术,理论上来说比OpenGL ES效率更高。 |
||||
|
||||
WebRTC中这两种渲染方式都支持。它首先会判断当前iOS系统是否支持Metal,如果支持的话,优先使用Metal。如果不支持的话,就使用 OpenGL ES。 |
||||
|
||||
我们今天介绍的是 OpenGL ES的方案。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
### 1.1创建 OpenGL 上下文 |
||||
|
||||
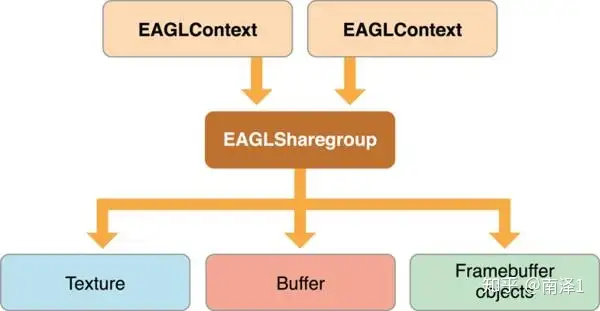
在iOS中使用OpenGL ES做视频渲染时,首先要创建EAGLContext对象。这是因为,EAGLContext管理着 OpengGL ES 渲染上下文。该上下文中,包括了状态信息,渲染命令以及OpenGL ES绘制资源(如纹理和renderbuffers)。为了执行OpenGL ES命令,你需要将创建的EAGLContext设置为当前渲染上下文。 |
||||
|
||||
EAGLContext并不直接管理绘制资源,它通过与上下文相关的EAGLSharegroup对象来管理。当创建EAGLContext时,你可以选择创建一个新的sharegroup或与之前创建的EAGLContext共享EAGLSharegroup。 |
||||
|
||||
EAGLContext与EAGLSharegroup的关系如下图所示: |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
WebRTC中并没有使用共享EAGLSharegroup的情况,所以对于这种情况我们这里就不做特别讲解了。有兴趣的同学可以在网上查找相关资料。 |
||||
|
||||
目前,OpenGL ES有3个版本,主要使用版本2和版本3 。所以我们在创建时要对其作判断。首先看是否支持版本3,如果不支持我们就使用版本2。 |
||||
|
||||
代码如下: |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
创建完上下文后,我们还要将它设置为当前上下文,这样它才能真正起作用。 |
||||
|
||||
代码如下: |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
> 需要注意的是,由于应用切换到后台后,上下文就发生了切换。所以当它切换到前台时,也要做上面那个判断。 |
||||
|
||||
OpenGL ES上下文创建好后,下面我们看一下如何创建View。 |
||||
|
||||
### 1.2创建 OpenGL View |
||||
|
||||
在iOS中,有两种展示层,一种是 GLKView,另一种是 CAEAGLLayer。WebRTC中使用GLKView进行展示。CAEAGLLayer暂不做介绍。 |
||||
|
||||
GLKit框架提供了View和View Controller类以减少建立和维护绘制 OpenGL ES 内容的代码。GLKView类用于管理展示部分;GLKViewController类用于管理绘制的内容。它们都是继承自UIKit。GLKView的好处是,开发人员可以将自己的精力聚焦在OpenGL ES渲染的工作上。 |
||||
|
||||
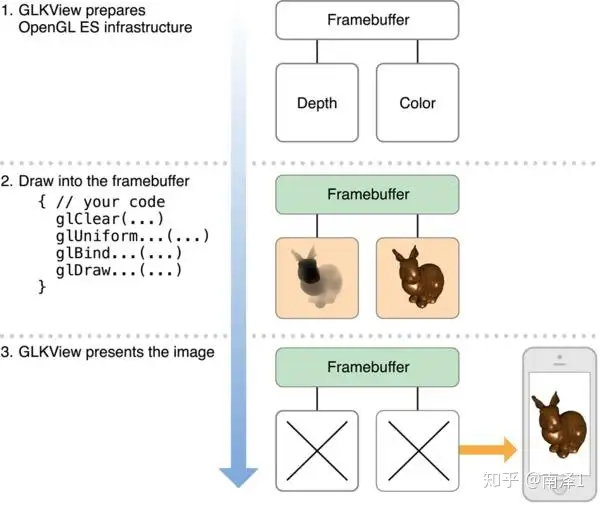
GLKView展示的基本流程如下: |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
如上图所示,绘制 OpenGL ES 内容有三步: |
||||
|
||||
|
||||
|
||||
- 准备 OpenGL ES环境; |
||||
- 发送绘制命令; |
||||
- 展示渲染内容。 |
||||
|
||||
GLKView类自己实现了第一步和第三步。第二步由开发人员来完成,也就是要实现drawRect函数。GLKView之所以能为OpenGL ES 提供简单的绘制接口,是因为它管理了OpenGL ES 渲染过程的标准部分: |
||||
|
||||
在调用绘制方法之前: |
||||
|
||||
使用 EAGLContext 作为当前上下文。 |
||||
|
||||
根据size, 缩放因子和绘制属性,创建 FBO 和 renderbuffer。 |
||||
|
||||
绑定 FBO,作为绘制命令的当前目的地。 |
||||
|
||||
匹配 OpenGL ES viewport与 framebuffer size 。 |
||||
|
||||
在绘制方法返回之后: |
||||
|
||||
解决多采样 buffers(如果开启了多采样)。 |
||||
|
||||
当内容不在需要时,丢掉 renderbuffers。 |
||||
|
||||
展示renderbuffer内容。 |
||||
|
||||
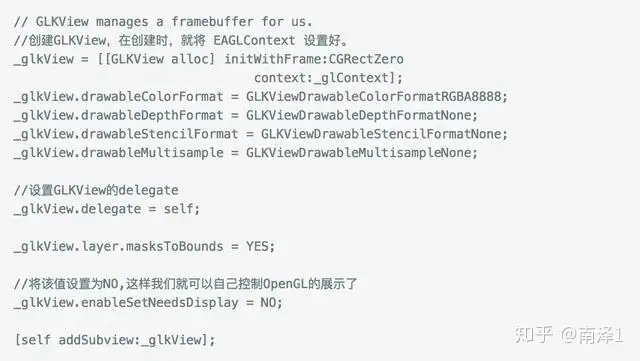
使用GLKView有两种方法,一种是实现一个类,直接继承自GLKView,并实现drawRect方法。另一种是实现GLKView的代理,也就是GLKViewDelegate,并实现drawInRect方法。 |
||||
|
||||
在WebRTC中,使用的是第二种方法。RTCEAGLVideoView 是GLKView的包裹类,并且继承自GLKViewDelegate。 |
||||
|
||||
首先,创建GLKView. |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
创建好GLKView后,需要将glkView.delegate设置为RTCEAGLVideoView,这样就可以将绘制工作交由RTCEAGLVideoView来完成了。另外, glkView.enableSetNeedsDisplay 设置为 NO,由我们自己来控制何时进行绘制。 |
||||
|
||||
然后,实现drawInRect方法。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
上面的代码就是通过Shader来绘制NV12的YUV数据到View中。这段代码的基本意思是将一个解码后的视频帧分解成Y数据纹理及UV数据纹理。然后调用Shader程序将纹理转成rgb数据,最终渲染到View中。 |
||||
|
||||
## 2.Shader程序 |
||||
|
||||
OpenGL ES 有两种 Shader。一种是顶点(Vetex)Shader; 另一种是片元(fragment )Shader。 |
||||
|
||||
Vetex Shader: 用于绘制顶点。 |
||||
|
||||
Fragment Shader:用于绘制像素点。 |
||||
|
||||
Vetex Shader |
||||
|
||||
Vetex Shader用于绘制图形的顶点。我们都知道,无论是2D还是3D图形,它们都是由顶点构成的。 |
||||
|
||||
在OpenGL ES中,有三种基本图元,分别是点,线,三角形。由它们再构成更复杂的图形。而点、线、三角形又都是由点组成的。 |
||||
|
||||
视频是在一个矩形里显示,所以我们要通过基本图元构建一个矩形。理论上,距形可以通过点、线绘制出来,但这样做的话,OpenGL ES就要绘制四次。而通过三角形绘制只需要两次,所以使用三角形执行速度更快。 下面的代码就是 WebRTC 中的Vetex Shader程序。该程序的作用是每个顶点执行一次,将用户输入的顶点输出到 gl_Position中,并将顶点的纹理作标点转作为 Fragment Shader 的输入。 |
||||
|
||||
1.OpenGL坐标原点是屏幕的中心。纹理坐标的原点是左下角。 |
||||
|
||||
2.gl_Position是Shader的内部变量,存放一个项点的坐标。 |
||||
|
||||
|
||||
|
||||
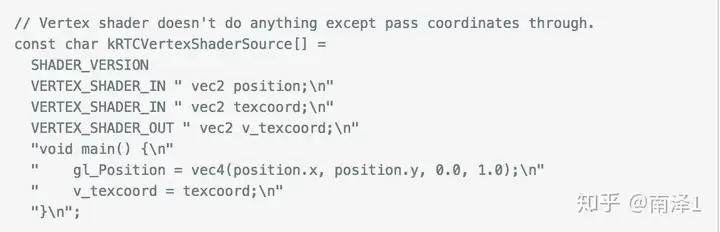 |
||||
|
||||
|
||||
|
||||
OpenGL ES Shader语法请见我的另一篇文章着色器 |
||||
|
||||
### 2.1fragment Shader |
||||
|
||||
fragment Shader程序是对片元着色,每个片元执行一次。片元与像素差不多。可以简单的把片元理解为像素。 |
||||
|
||||
下面的代码是WebRTC中的 fragment |
||||
|
||||
> YUV有多种格式,可以参见我的另一篇文章YUV。 |
||||
|
||||
在代码中,使用FRAGMENT_SHADER_TEXTURE命令,也就是OpenGL ES中的 texture2D 函数,分别从 Y 数据纹理中取出 y值,从 UV 数据纹理中取出 uv值,然后通过公式计算出每个像素(实际是片元)的 rgb值。 |
||||
|
||||
|
||||
|
||||
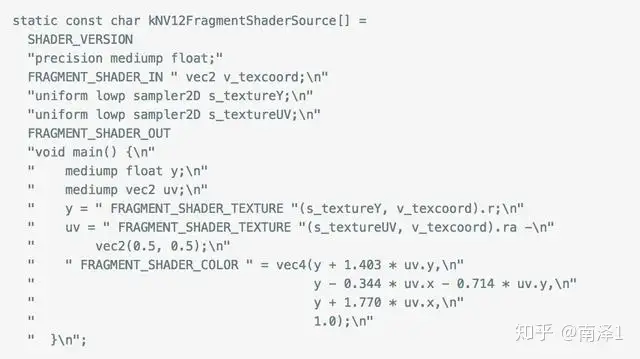 |
||||
|
||||
|
||||
|
||||
有了顶点数据和片元的RGB值后,就可以调用OpenGL ES的 draw 方法进行视频的绘制了。 |
||||
|
||||
Shader的编译、链接与使用 上面介绍了 WebRTC下 Vetex Shader 和 Fragment Shader程序。要想让程序运行起来,还要额外做一些工作。 |
||||
|
||||
OpenGL ES的 shader程序与C程序差不多。想像一下C程序,要想让一个C程序运行起来,要有以下几个步骤: |
||||
|
||||
- 写好程序代码 |
||||
- 编译 |
||||
- 链接 |
||||
- 执行 |
||||
|
||||
Shader程序的运行也是如此。我们看看 WebRTC是如何做的。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
它首先创建一个 Shader, 然后将上面的 Shader 程序与 Shader 绑定。之后编译 Shader。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
编译成功后,创建 program 对象。 将之前创建的 Shader 与program绑定到一起。之后做链接工作。一切准备就绪后,就可以使用Shader程序绘制视频了。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
### 2.2WebRTC中视频渲染相关文件 |
||||
|
||||
RTCEAGLVideoView.m/h:创建 EAGLContext及OpenGL ES View,并将视频数据显示出来。 |
||||
|
||||
RTCShader.mm/h:OpenGL ES Shader 程序的创建,编译与链接相关的代码。 |
||||
|
||||
RTCDefaultShader.mm/h: Shader 程序,绘制相关的代码。 |
||||
|
||||
RTCNV12TextureCache.mm/h: 用于生成 YUV NV12 相关纹理的代码。 |
||||
|
||||
RTCI420TexutreCache.mm/h: 用于生成 I420 相关纹理的代码。 |
||||
|
||||
## 3.小结 |
||||
|
||||
本文对 WebRTC 中 OpenGL ES 渲染做了介绍。通过本篇文章大家可以了解到WebRTC是如何将视频渲染出来的。包括: |
||||
|
||||
上下文的创建与初始化。 |
||||
|
||||
GLKView的创建。 |
||||
|
||||
绘制方法的实现。 |
||||
|
||||
Shader代码的分析。 |
||||
|
||||
Shader的编译与执行。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/146950864 |
||||
@ -0,0 +1,246 @@ |
||||
# 【OpenGL入门】iOS 图像渲染原理 |
||||
|
||||
- CPU(Central Processing Unit):现代计算机的三大核心部分之一,作为整个系统的运算和控制单元。CPU 内部的流水线结构使其拥有一定程度的并行计算能力。 |
||||
- GPU(Graphics Processing Unit):一种可进行绘图运算工作的专用微处理器。GPU 能够生成 2D/3D 的图形图像和视频,从而能够支持基于窗口的操作系统、图形用户界面、视频游戏、可视化图像应用和视频播放。GPU 具有非常强的并行计算能力。 |
||||
|
||||
使用 GPU 渲染图形的根本原因就是速度问题。GPU 优秀的并行计算能力使其能够快速将图形结果计算出来并在屏幕的所有像素中进行显示。 |
||||
|
||||
**屏幕图像的显示原理** |
||||
|
||||
介绍屏幕图像显示的原理,需要先从 CRT 显示器原理说起,如下图所示。CRT 的电子枪从上到下逐行扫描,扫描完成后显示器就呈现一帧画面。然后电子枪回到初始位置进行下一次扫描。为了同步显示器的显示过程和系统的显示控制器,显示器会用硬件时钟产生一系列的定时信号。当电子枪换行进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync;而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。虽然现在的显示器基本都是液晶显示屏了,但其原理基本一致。 |
||||
|
||||
 |
||||
|
||||
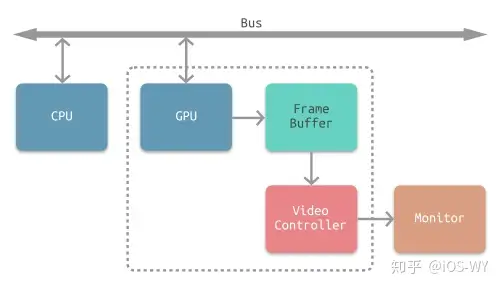
下图所示为常见的 CPU、GPU、显示器工作方式。CPU 计算好显示内容提交至 GPU,GPU 渲染完成后将渲染结果存入帧缓冲区,显示控制器会按照 `VSync` 信号逐帧读取帧缓冲区的数据,经过数据转换后最终由显示器进行显示。 |
||||
|
||||
 |
||||
|
||||
**双缓冲机制** |
||||
|
||||
所以,显示一个画面需要两步完成: |
||||
|
||||
- CPU把需要显示的画面数据计算出来 |
||||
- 显示器把这些数据显示出来 |
||||
|
||||
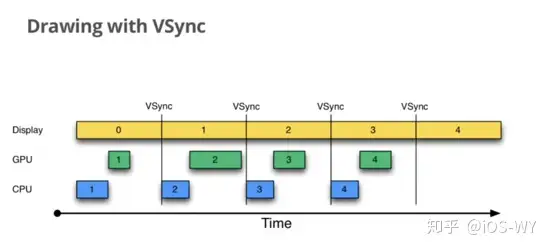
这两步工作都需要时间,并且可以并行执行,因为具体执行这两个过程的硬件是相互独立的( `CPU/显卡` 和 `显示控制器` )。但是这两个工作的耗时是不同的。 CPU 以及显卡每秒能计算出的画面数量是根据硬件性能决定的。 但是显示器每秒刷新频率是固定的(一般是 `60hz` ,所以每隔16.667ms就会刷新一次)。 |
||||
|
||||
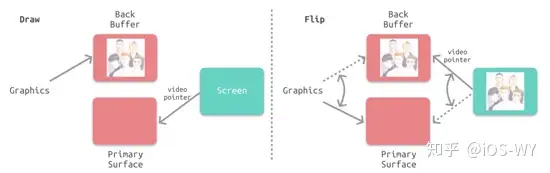
由于存在两边速率不统一的问题,所以引入了 `帧缓冲区(FrameBuffer)` 的概念。 |
||||
|
||||
最简单的情况下,帧缓冲区只有一个。此时,帧缓冲区的读取和刷新都都会有比较大的效率问题。为了解决效率问题,GPU 通常会引入两个缓冲区,即 `双缓冲机制` 。在这种情况下,GPU 会预先渲染一帧放入一个缓冲区中,用于显示控制器的读取。当下一帧渲染完毕后,GPU 会直接把显示控制器的指针指向第二个缓冲器。 |
||||
|
||||
根据苹果的官方文档描述,iOS 设备会始终使用 `Vsync + Double Buffering` (垂直同步+双缓冲) 的策略。 |
||||
|
||||
 |
||||
|
||||
**屏幕撕裂** |
||||
|
||||
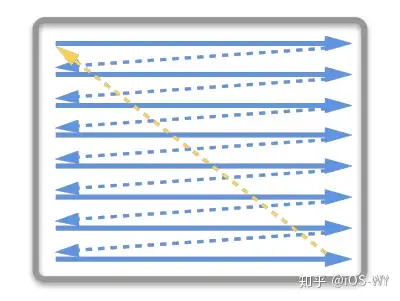
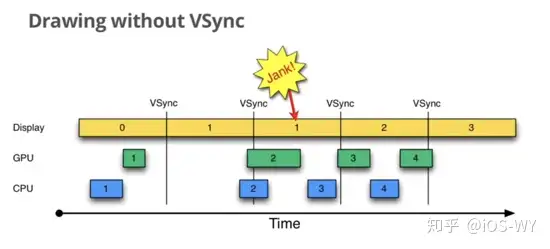
双缓冲虽然能解决效率问题,但会引入一个新的问题。当显示控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,显示控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象,如下图: |
||||
|
||||
 |
||||
|
||||
为了解决这个问题,GPU 通常有一个机制叫做 `垂直同步` (简写也是 `V-Sync` ),当开启 `垂直同步` 后,GPU 会等待显示器的 `VSync` 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。 |
||||
|
||||
 |
||||
|
||||
 |
||||
|
||||
**掉帧** |
||||
|
||||
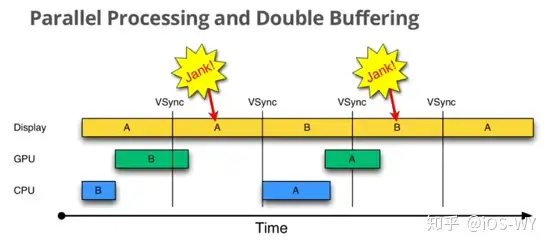
开启了 `垂直同步` 后,理想状况下 CPU 和 GPU 可以在16ms内处理完每一帧的渲染。但是如果显卡的帧率小于屏幕的刷新率,CPU 和 GPU 处理完一帧的渲染的时间超过了16ms,就会发生掉帧的情况。那一帧会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。 |
||||
|
||||
此时显示控制器占用一个 Buffer ,GPU 占用一个 Buffer 。两个Buffer都被占用,导致 CPU 空闲下来浪费了资源,因为垂直同步的原因,只有到了 `VSync` 信号的时间点, CPU 才能触发绘制工作。 |
||||
|
||||
 |
||||
|
||||
**三缓冲机制** |
||||
|
||||
在Android4.1系统开始,引入了 `三缓冲+垂直同步` 的机制。由于多加了一个 Buffer,实现了 CPU 跟 GPU 并行,便可以做到了只在开始掉一帧,后续却不掉帧, `双缓冲` 充分利用16ms做到低延时, `三缓冲` 保障了其稳定性。 |
||||
|
||||
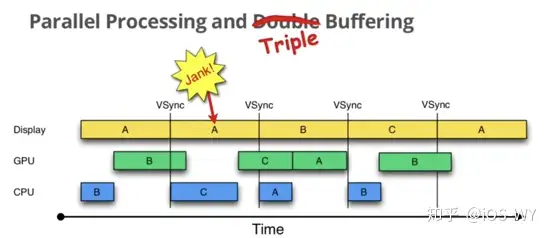 |
||||
|
||||
**iOS的渲染框架** |
||||
|
||||
iOS App 的图形渲染使用了 `Core Graphics` 、 `Core Animation` 、 `Core Image` 等框架来绘制可视化内容,这些软件框架相互之间也有着依赖关系。这些框架都需要通过 `OpenGL` 来调用 GPU 进行绘制,最终将内容显示到屏幕之上。 |
||||
|
||||
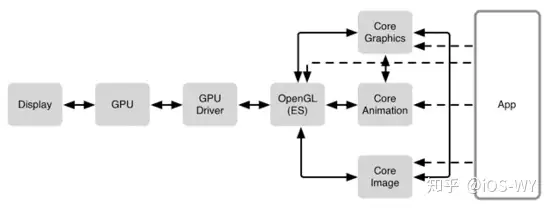 |
||||
|
||||
**UIKit** |
||||
|
||||
`UIKit` 是 iOS 开发者最常用的框架,可以通过设置 `UIKit` 组件的布局以及相关属性来绘制界面。 |
||||
|
||||
事实上, `UIKit` 自身并不具备在屏幕成像的能力,其主要负责对用户操作事件的响应( `UIView` 继承自 `UIResponder` ),事件响应的传递大体是经过逐层的 `视图树` 遍历实现的。 |
||||
|
||||
**Core Animation** |
||||
|
||||
`Core Animation` 源自于 `Layer Kit` ,动画只是 `Core Animation` 特性的冰山一角。 |
||||
|
||||
`Core Animation` 是一个复合引擎,其职责是 尽可能快地组合屏幕上不同的可视内容,这些可视内容可被分解成独立的图层(即 `CALayer` ),这些图层会被存储在一个叫做 `图层树` 的体系之中。从本质上而言, `CALayer` 是用户所能在屏幕上看见的一切的基础。 |
||||
|
||||
**Core Graphics** |
||||
|
||||
`Core Graphics` 基于 `Quartz` 高级绘图引擎,主要用于运行时绘制图像。开发者可以使用此框架来处理基于路径的绘图,转换,颜色管理,离屏渲染,图案,渐变和阴影,图像数据管理,图像创建和图像遮罩以及 PDF 文档创建,显示和分析。 |
||||
|
||||
当开发者需要在 `运行时创建图像` 时,可以使用 `Core Graphics` 去绘制。与之相对的是 `运行前创建图像` ,例如用 Photoshop 提前做好图片素材直接导入应用。相比之下,我们更需要 `Core Graphics` 去在运行时实时计算、绘制一系列图像帧来实现动画。 |
||||
|
||||
**Core Image** |
||||
|
||||
`Core Image` 与 `Core Graphics` 恰恰相反, `Core Graphics` 用于在 `运行时创建图像` ,而 `Core Image` 是用来处理 `运行前创建的图像` 的。 `Core Image` 框架拥有一系列现成的图像过滤器,能对已存在的图像进行高效的处理。 |
||||
|
||||
大部分情况下, `Core Image` 会在 GPU 中完成工作,但如果 GPU 忙,会使用 CPU 进行处理。 |
||||
|
||||
**OpenGL ES** |
||||
|
||||
`OpenGL ES(OpenGL for Embedded Systems,简称 GLES)` ,是 `OpenGL` 的子集。 `OpenGL` 是一套第三方标准,函数的内部实现由对应的 GPU 厂商开发实现。 |
||||
|
||||
**Metal** |
||||
|
||||
`Metal` 类似于 `OpenGL ES` ,也是一套第三方标准,具体实现由苹果实现。大多数开发者都没有直接使用过 `Metal` ,但其实所有开发者都在间接地使用 `Metal` 。 `Core Animation` 、 `Core Image` 、 `SceneKit` 、 `SpriteKit` 等等渲染框架都是构建于 `Metal` 之上的。 |
||||
|
||||
当在真机上调试 `OpenGL` 程序时,控制台会打印出启用 `Metal` 的日志。根据这一点可以猜测, `Apple` 已经实现了一套机制将 `OpenGL` 命令无缝桥接到 `Metal` 上,由 `Metal` 担任真正于硬件交互的工作。 |
||||
|
||||
**UIView 与 CALayer** |
||||
|
||||
`CALayer` 是用户所能在屏幕上看见的一切的基础,用来存放 `位图(Bitmap)` 。 `UIKit` 中的每一个 UI 视图控件( `UIView` )其实内部都有一个关联的 `CALayer` ,即 `backing layer` 。 |
||||
|
||||
由于这种一一对应的关系,视图( `UIView` )层级拥有 `视图树` 的树形结构,对应 `CALayer` 层级也拥有 `图层树` 的树形结构。 |
||||
|
||||
视图( `UIView` )的职责是 `创建并管理` 图层,以确保当子视图在层级关系中 `添加或被移除` 时,其关联的图层在图层树中也有相同的操作,即保证视图树和图层树在结构上的一致性。 |
||||
|
||||
那么为什么 iOS 要基于 UIView 和 CALayer 提供两个平行的层级关系呢? |
||||
|
||||
其原因在于要做 职责分离,这样也能避免很多重复代码。在 `iOS` 和 `Mac OS X` 两个平台上,事件和用户交互有很多地方的不同,基于多点触控的用户界面和基于鼠标键盘的交互有着本质的区别,这就是为什么 `iOS` 有 `UIKit` 和 `UIView` ,对应 `Mac OS X` 有 `AppKit` 和 `NSView` 的原因。它们在功能上很相似,但是在实现上有着显著的区别。 |
||||
|
||||
**CALayer** |
||||
|
||||
在 `CALayer.h` 中, `CALayer` 有这样一个属性 `contents` |
||||
|
||||
```text |
||||
/** Layer content properties and methods. **/ |
||||
|
||||
/* An object providing the contents of the layer, typically a CGImageRef, |
||||
* but may be something else. (For example, NSImage objects are |
||||
* supported on Mac OS X 10.6 and later.) Default value is nil. |
||||
* Animatable. */ |
||||
|
||||
@property(nullable, strong) id contents; |
||||
复制代码 |
||||
``` |
||||
|
||||
`contents` 提供了 layer 的内容,是一个指针类型,在 `iOS` 中的类型就是 `CGImageRef` (在 `OS X` 中还可以是 `NSImage` )。 `CALayer` 中的 `contents` 属性保存了由设备渲染流水线渲染好的位图 `bitmap` (通常也被称为 `backing store` ),而当设备屏幕进行刷新时,会从 `CALayer` 中读取生成好的 `bitmap` ,进而呈现到屏幕上。 |
||||
|
||||
图形渲染流水线支持从顶点开始进行绘制(在流水线中,顶点会被处理生成 `纹理` ),也支持直接使用 `纹理(图片)` 进行渲染。相应地,在实际开发中,绘制界面也有两种方式:一种是 `手动绘制` ;另一种是 `使用图片` 。 |
||||
|
||||
- 使用图片: **contents image** |
||||
- 手动绘制: **custom drawing** |
||||
|
||||
Contents Image `Contents Image` 是指通过 `CALayer` 的 `contents` 属性来配置图片。然而, `contents` 属性的类型为 `id` 。在这种情况下,可以给 `contents` 属性赋予任何值,app 仍可以编译通过。但是在实践中,如果 `content` 的值不是 `CGImage` ,得到的图层将是空白的。 |
||||
|
||||
本质上, `contents` 属性指向的一块缓存区域,称为 `backing store` ,可以存放 `bitmap` 数据。 |
||||
|
||||
Custom Drawing `Custom Drawing` 是指使用 `Core Graphics` 直接绘制 `寄宿图` 。实际开发中,一般通过继承 `UIView` 并实现 `-drawRect:` 方法来自定义绘制。 |
||||
|
||||
虽然 `-drawRect:` 是一个 `UIView` 方法,但事实上都是底层的 `CALayer` 完成了重绘工作并保存了产生的图片。下图所示为 `-drawRect:` 绘制定义 `寄宿图` 的基本原理。 |
||||
|
||||
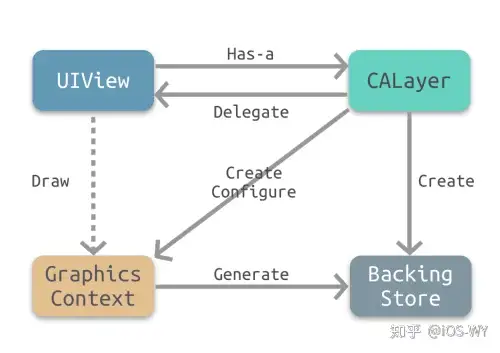 |
||||
|
||||
- `UIView` 有一个关联图层,即 `CALayer` 。 |
||||
- `CALayer` 有一个可选的 `delegate` 属性,实现了 `CALayerDelegate` 协议。 `UIView` 作为 `CALayer` 的代理实现了 `CALayerDelegae` 协议。 |
||||
- 当需要重绘时,即调用 `-drawRect:` , `CALayer` 请求其代理给予一个寄宿图来显示。 |
||||
- `CALayer` 首先会尝试调用 `-displayLayer:` 方法,此时代理可以直接设置 `contents` 属性。 |
||||
|
||||
```text |
||||
- (void)displayLayer:(CALayer *)layer; |
||||
复制代码 |
||||
``` |
||||
|
||||
- 如果代理没有实现 `-displayLayer:` 方法, `CALayer` 则会尝试调用 `-drawLayer:inContext:` 方法。在调用该方法前, `CALayer` 会创建一个空的寄宿图(尺寸由 `bounds` 和 `contentScale` 决定)和一个 `Core Graphics` 的绘制上下文,为绘制寄宿图做准备,作为 `context` 参数传入。 |
||||
|
||||
```text |
||||
- (void)drawLayer:(CALayer *)layer inContext:(CGContextRef)ctx; |
||||
复制代码 |
||||
``` |
||||
|
||||
- 最后,由 `Core Graphics` 绘制生成的寄宿图会存入 `backing store` 。 |
||||
|
||||
**UIView** |
||||
|
||||
`UIView` 是 app 中的基本组成结构,定义了一些统一的规范。它会负责内容的渲染以及,处理交互事件。 |
||||
|
||||
- Drawing and animation:绘制与动画 |
||||
- Layout and subview management:布局与子 view 的管理 |
||||
- Event handling:点击事件处理 |
||||
|
||||
`CALayer` 是 `UIView` 的属性之一,负责渲染和动画,提供可视内容的呈现。 `UIView` 提供了对 `CALayer` 部分功能的封装,同时也另外负责了交互事件的处理。 |
||||
|
||||
- 相同的层级结构:我们对 `UIView` 的层级结构非常熟悉,由于每个 `UIView` 都对应 `CALayer` 负责页面的绘制,所以 `CALayer` 也具有相应的层级结构。 |
||||
- 部分效果的设置:因为 `UIView` 只对 `CALayer` 的部分功能进行了封装,而另一部分如圆角、阴影、边框等特效都需要通过调用 layer 属性来设置。 |
||||
- 是否响应点击事件: `CALayer` 不负责点击事件,所以不响应点击事件,而 `UIView` 会响应。 |
||||
- 不同继承关系: `CALayer` 继承自 `NSObject` , `UIView` 由于要负责交互事件,所以继承自 `UIResponder` 。 |
||||
|
||||
**Core Animation** |
||||
|
||||
**Core Animation 流水线** |
||||
|
||||
事实上,app 本身并不负责渲染,渲染则是由一个独立的进程负责,即 Render Server 进程。 |
||||
|
||||
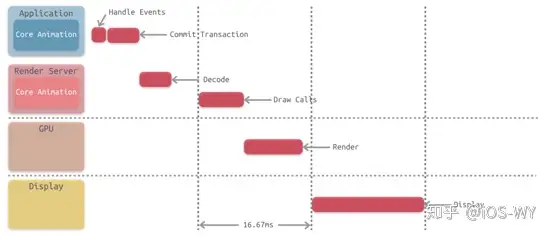 |
||||
|
||||
App 通过 IPC 将渲染任务及相关数据提交给 `Render Server` 。 `Render Server` 处理完数据后,再传递至 GPU。最后由 GPU 调用 iOS 的图像设备进行显示。 |
||||
|
||||
- 首先,由 app 处理事件(Handle Events),如:用户的点击操作,在此过程中 app 可能需要更新 视图树,相应地,图层树 也会被更新。 |
||||
- 其次,app 通过 CPU 完成对显示内容的计算,如:视图的创建、布局计算、图片解码、文本绘制等。在完成对显示内容的计算之后,app 对图层进行打包,并在下一次 `RunLoop` 时将其发送至 `Render Server` ,即完成了一次 `Commit Transaction` 操作。 |
||||
- `Render Server` 主要执行 `Open GL` 、 `Core Graphics` 相关程序,并调用 GPU。 |
||||
- GPU 则在物理层上完成了对图像的渲染。 |
||||
- 最终,GPU 通过 `Frame Buffer` 、 `视频控制器` 等相关部件,将图像显示在屏幕上。 |
||||
|
||||
对上述步骤进行串联,它们执行所消耗的时间远远超过 16.67 ms,因此为了满足对屏幕的 60 FPS 刷新率的支持,需要将这些步骤进行分解,通过流水线的方式进行并行执行,如下图所示。 |
||||
|
||||
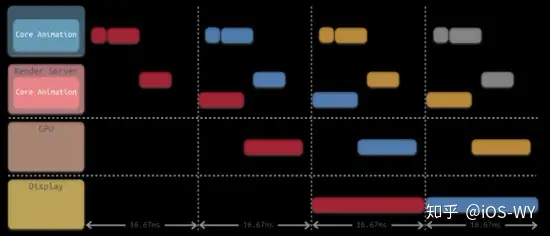 |
||||
|
||||
**图层树** |
||||
|
||||
`CoreAnimation` 作为一个复合引擎,将不同的视图层组合在屏幕中,并且存储在 `图层树` 中,向我们展示了所有屏幕上的一切。 |
||||
|
||||
整个过程其实经历了三个树状结构,才显示到了屏幕上: `模型树-->呈现树-->渲染树` |
||||
|
||||
层级关系树中除了 `视图树` 和 `图层树` ,还有 `呈现树` 和 `渲染树` 。他们各自都有各自的职责。 |
||||
|
||||
- **呈现树** :我们可以通过 `CALayer` 的 `-presentationLayer` 方法来访问对应的呈现树图层。注意呈现图层仅仅当图层首次被提交(就是首次第一次在屏幕上显示)的时候创建,所以在那之前调用 `-presentationLayer` 将会返回nil。 |
||||
|
||||
```text |
||||
- (nullable instancetype)presentationLayer; |
||||
复制代码 |
||||
``` |
||||
|
||||
- **模型树** :在呈现图层上调用 `–modelLayer` 将会返回它正在呈现所依赖的 `CALayer` 。通常在一个图层上调用 `-modelLayer` 会返回 `self` (实际上我们已经创建的原始图层就是一种数据模型)。 |
||||
|
||||
```text |
||||
- (instancetype)modelLayer; |
||||
复制代码 |
||||
``` |
||||
|
||||
通常,我们操作的是模型树 `modelLayer` ,在重绘周期最后,我们会将模型树相关内容(层次结构、图层属性和动画)序列化,通过IPC传递给专门负责屏幕渲染的渲染进程。渲染进程拿到数据并反序列化出树状结构--呈现树。这个呈现图层实际上是模型图层的复制,但是它的属性值代表了在任何指定时刻当前外观效果。换句话说,可以通过呈现图层的值来获取当前屏幕上真正显示出来的值。 |
||||
|
||||
当模型树 `modelLayer` 上带有动画特征时,提交到渲染进程后,渲染进程会根据动画特征,不断修改呈现树 `presentationLayer` 上的图层属性,并同时不断的在屏幕上渲染出来,这样我们就看到了动画。 |
||||
|
||||
如果想让动画的图层响应用户输入,可以使用 `-hitTest:` 方法来判断指定图层是否被触摸,这时候对呈现图层而不是模型图层调用 `-hitTest:` 会显得更有意义,因为呈现图层代表了用户当前看到的图层位置,而不是当前动画结束之后的位置。 |
||||
|
||||
可以理解为 `modelLayer` 负责数据的存储和获取, `presentationLayer` 负责显示。每次屏幕刷新的时候, `presentationLayer` 会与 `modelLayer` 状态同步。 |
||||
|
||||
当 `CAAnimation` 加到layer上之后, `presentationLayer` 每次刷新的时候会去 `CAAnimation` 询问并同步状态, `CAAnimation` 控制 `presentationLayer` 从 `fromValue` 到 `toValue` 来改变值,而动画结束之后, `CAAnimation` 会从layer上被移除,此时屏幕刷新的时候 `presentationLayer` 又会同步 `modelLayer` 的状态, `modelLayer` 没有改变,所以又回到了起点。当然我们可以通过设置,继续影响 `presentationLayer` 的状态。 |
||||
|
||||
**Core Animation 动画** |
||||
|
||||
`Core Animation` 动画,即基于事务的动画,是最常见的动画实现方式。动画执行者是专门负责渲染的渲染进程,操作的是呈现树。我们应该尽量使用 `Core Animation` 来控制动画,因为 `Core Animation` 是充分优化过的: |
||||
|
||||
基于 `Layer` 的绘图过程中, `Core Animation` 通过硬件操作位图(变换、组合等),产生动画的速度比软件操作的方式快很多。 |
||||
|
||||
基于 `View` 的绘图过程中, `view` 被改动时会触发的 `drawRect:` 方法来重新绘制位图,但是这种方式需要CPU在主线程执行,比较耗时。而 `Core Animation` 则尽可能的操作硬件中已缓存的位图,来实现相同的效果,从而减少了资源损耗。 |
||||
|
||||
**非 Core Animation 动画** |
||||
|
||||
非 `CoreA nimation` 动画执行者是当前进程,操作的是模型树。常见的有定时器动画和手势动画。定时器动画是在定时周期触发时修改模型树的图层属性;手势动画是手势事件触发时修改模型树的图层属性。两者都能达到视图随着时间不断变化的效果,即实现了动画。 |
||||
|
||||
非 `Core Animation` 动画动画过程中实际上不断改动的是模型树,而呈现树仅仅成了模型树的复制品,状态与模型树保持一致。整个过程中,主要是CPU在主线程不断调整图层属性、布局计算、提交数据,没有充分利用到 `Core Animation` 强大的动画控制功能。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/307909741 |
||||
@ -0,0 +1,145 @@ |
||||
# 关于iOS离屏渲染的深入研究 |
||||
|
||||
在平时的iOS面试中,我们经常会考察有关离屏渲染(Offscreen rendering)的知识点。一般来说,绝大多数人都能答出“圆角、mask、阴影会触发离屏渲染”,但是也仅止于此。如果再问得深入哪怕一点点,比如: |
||||
|
||||
- 离屏渲染是在哪一步进行的?为什么? |
||||
- 设置cornerRadius一定会触发离屏渲染吗? |
||||
|
||||
90%的候选人都没法非常确定地说出答案。作为一个客户端工程师,把控渲染性能是最关键、最独到的技术要点之一,如果仅仅了解表面知识,到了实际应用时往往会失之毫厘谬以千里,无法得到预期的效果。 |
||||
|
||||
iOS渲染架构 |
||||
|
||||
在WWDC的Advanced Graphics and Animations for iOS Apps(WWDC14 419,关于UIKit和Core Animation基础的session在早年的WWDC中比较多)中有这样一张图: |
||||
|
||||
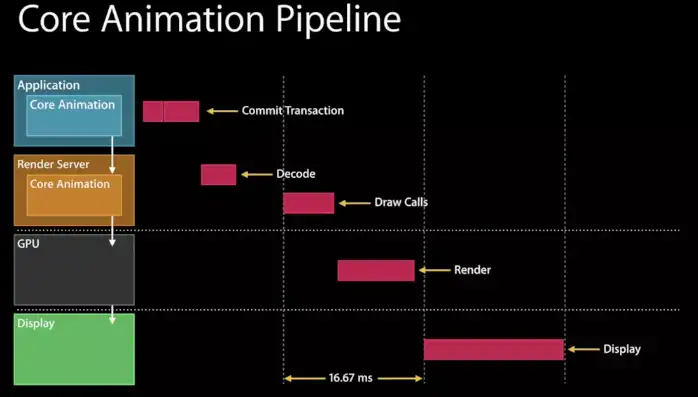 |
||||
|
||||
我们可以看到,在Application这一层中主要是CPU在操作,而到了Render Server这一层,CoreAnimation会将具体操作转换成发送给GPU的draw calls(以前是call OpenGL ES,现在慢慢转到了Metal),显然CPU和GPU双方同处于一个流水线中,协作完成整个渲染工作。 |
||||
|
||||
离屏渲染的定义 |
||||
|
||||
如果要在显示屏上显示内容,我们至少需要一块与屏幕像素数据量一样大的frame buffer,作为像素数据存储区域,而这也是GPU存储渲染结果的地方。如果有时因为面临一些限制,无法把渲染结果直接写入frame buffer,而是先暂存在另外的内存区域,之后再写入frame buffer,那么这个过程被称之为离屏渲染。 |
||||
|
||||
 |
||||
|
||||
渲染结果先经过了离屏buffer,再到frame buffer |
||||
|
||||
CPU”离屏渲染“ |
||||
|
||||
大家知道,如果我们在UIView中实现了drawRect方法,就算它的函数体内部实际没有代码,系统也会为这个view申请一块内存区域,等待CoreGraphics可能的绘画操作。 |
||||
|
||||
对于类似这种“新开一块CGContext来画图“的操作,有很多文章和视频也称之为“离屏渲染”(因为像素数据是暂时存入了CGContext,而不是直接到了frame buffer)。进一步来说,其实所有CPU进行的光栅化操作(如文字渲染、图片解码),都无法直接绘制到由GPU掌管的frame buffer,只能暂时先放在另一块内存之中,说起来都属于“离屏渲染”。 |
||||
|
||||
自然我们会认为,因为CPU不擅长做这件事,所以我们需要尽量避免它,就误以为这就是需要避免离屏渲染的原因。但是[根据苹果工程师的说法](https://link.zhihu.com/?target=https%3A//lobste.rs/s/ckm4uw/performance_minded_take_on_ios_design%23c_itdkfh),CPU渲染并非真正意义上的离屏渲染。另一个证据是,如果你的view实现了drawRect,此时打开Xcode调试的“Color offscreen rendered yellow”开关,你会发现这片区域不会被标记为黄色,说明Xcode并不认为这属于离屏渲染。 |
||||
|
||||
其实通过CPU渲染就是俗称的“软件渲染”,而**真正的离屏渲染发生在GPU**。 |
||||
|
||||
GPU离屏渲染 |
||||
|
||||
在上面的渲染流水线示意图中我们可以看到,主要的渲染操作都是由CoreAnimation的Render Server模块,通过调用显卡驱动所提供的OpenGL/Metal接口来执行的。通常对于每一层layer,Render Server会遵循“[画家算法](https://link.zhihu.com/?target=https%3A//en.wikipedia.org/wiki/Painter%27s_algorithm)”,按次序输出到frame buffer,后一层覆盖前一层,就能得到最终的显示结果(值得一提的是,与一般桌面架构不同,在iOS中,设备主存和GPU的显存[共享物理内存](https://link.zhihu.com/?target=https%3A//apple.stackexchange.com/questions/54977/how-much-gpu-memory-do-iphones-and-ipads-have),这样可以省去一些数据传输开销)。 |
||||
|
||||
 |
||||
|
||||
”画家算法“,把每一层依次输出到画布 |
||||
|
||||
然而有些场景并没有那么简单。作为“画家”的GPU虽然可以一层一层往画布上进行输出,但是无法在某一层渲染完成之后,再回过头来擦除/改变其中的某个部分——因为在这一层之前的若干层layer像素数据,已经在渲染中被永久覆盖了。这就意味着,**对于每一层layer,要么能找到一种通过单次遍历就能完成渲染的算法,要么就不得不另开一块内存,借助这个临时中转区域来完成一些更复杂的、多次的修改/剪裁操作**。 |
||||
|
||||
如果要绘制一个带有圆角并剪切圆角以外内容的容器,就会触发离屏渲染。我的猜想是(如果读者中有图形学专家希望能指正): |
||||
|
||||
- 将一个layer的内容裁剪成圆角,可能不存在一次遍历就能完成的方法 |
||||
- 容器的子layer因为父容器有圆角,那么也会需要被裁剪,而这时它们还在渲染队列中排队,尚未被组合到一块画布上,自然也无法统一裁剪 |
||||
|
||||
此时我们就不得不开辟一块独立于frame buffer的空白内存,先把容器以及其所有子layer依次画好,然后把四个角“剪”成圆形,再把结果画到frame buffer中。这就是GPU的离屏渲染。 |
||||
|
||||
常见离屏渲染场景分析 |
||||
|
||||
- cornerRadius+clipsToBounds,原因就如同上面提到的,不得已只能另开一块内存来操作。而如果只是设置cornerRadius(如不需要剪切内容,只需要一个带圆角的边框),或者只是需要裁掉矩形区域以外的内容(虽然也是剪切,但是稍微想一下就可以发现,对于纯矩形而言,实现这个算法似乎并不需要另开内存),并不会触发离屏渲染。关于剪切圆角的性能优化,根据场景不同有几个方案可供选择,非常推荐阅读[AsyncDisplayKit中的一篇文档](https://link.zhihu.com/?target=https%3A//texturegroup.org/docs/corner-rounding.html)。 |
||||
|
||||
 |
||||
|
||||
ASDK中对于如何选择圆角渲染策略的流程图,非常实用 |
||||
|
||||
- shadow,其原因在于,虽然layer本身是一块矩形区域,但是阴影默认是作用在其中”非透明区域“的,而且需要显示在所有layer内容的下方,因此根据画家算法必须被渲染在先。但矛盾在于**此时阴影的本体(layer和其子layer)都还没有被组合到一起,怎么可能在第一步就画出只有完成最后一步之后才能知道的形状呢**?这样一来又只能另外申请一块内存,把本体内容都先画好,再根据渲染结果的形状,添加阴影到frame buffer,最后把内容画上去(这只是我的猜测,实际情况可能更复杂)。不过如果我们能够预先告诉CoreAnimation(通过shadowPath属性)阴影的几何形状,那么阴影当然可以先被独立渲染出来,不需要依赖layer本体,也就不再需要离屏渲染了。 |
||||
|
||||
 |
||||
|
||||
阴影会作用在所有子layer所组成的形状上,那就只能等全部子layer画完才能得到 |
||||
|
||||
- group opacity,其实从名字就可以猜到,alpha并不是分别应用在每一层之上,而是只有到整个layer树画完之后,再统一加上alpha,最后和底下其他layer的像素进行组合。显然也无法通过一次遍历就得到最终结果。将一对蓝色和红色layer叠在一起,然后在父layer上设置opacity=0.5,并复制一份在旁边作对比。左边关闭group opacity,右边保持默认(从iOS7开始,如果没有显式指定,group opacity会默认打开),然后打开offscreen rendering的调试,我们会发现右边的那一组确实是离屏渲染了。 |
||||
|
||||
 |
||||
|
||||
同样的两个view,右边打开group opacity(默认行为)的被标记为Offscreen rendering |
||||
|
||||
- mask,我们知道mask是应用在layer和其所有子layer的组合之上的,而且可能带有透明度,那么其实和group opacity的原理类似,不得不在离屏渲染中完成。 |
||||
|
||||
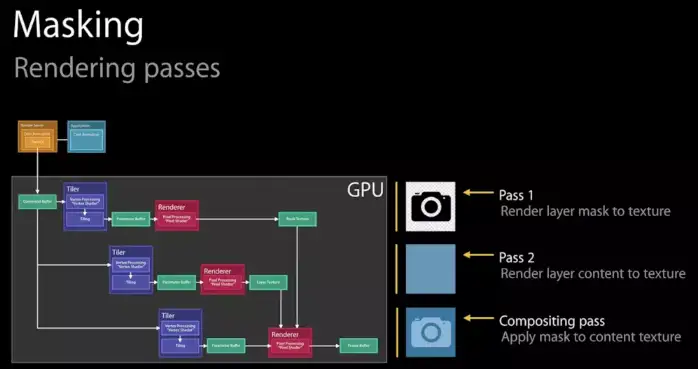 |
||||
|
||||
WWDC中苹果的解释,mask需要遍历至少三次 |
||||
|
||||
- UIBlurEffect,同样无法通过一次遍历完成,其原理在WWDC中提到: |
||||
|
||||
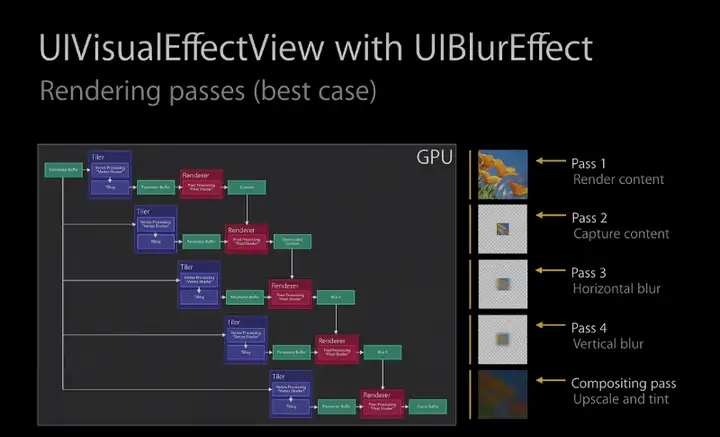 |
||||
|
||||
- 其他还有一些,类似allowsEdgeAntialiasing等等也可能会触发离屏渲染,原理也都是类似:如果你无法仅仅使用frame buffer来画出最终结果,那就只能另开一块内存空间来储存中间结果。这些原理并不神秘。 |
||||
|
||||
GPU离屏渲染的性能影响 |
||||
|
||||
GPU的操作是高度流水线化的。本来所有计算工作都在有条不紊地正在向frame buffer输出,此时突然收到指令,需要输出到另一块内存,那么流水线中正在进行的一切都不得不被丢弃,切换到只能服务于我们当前的“切圆角”操作。等到完成以后再次清空,再回到向frame buffer输出的正常流程。 |
||||
|
||||
在tableView或者collectionView中,滚动的每一帧变化都会触发每个cell的重新绘制,因此一旦存在离屏渲染,上面提到的上下文切换就会每秒发生60次,并且很可能每一帧有几十张的图片要求这么做,对于GPU的性能冲击可想而知(GPU非常擅长大规模并行计算,但是我想频繁的上下文切换显然不在其设计考量之中) |
||||
|
||||
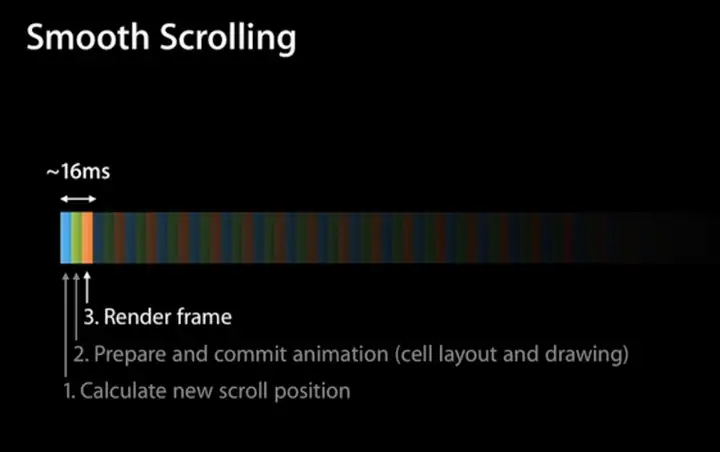 |
||||
|
||||
每16ms就需要根据当前滚动位置渲染整个tableView,是个不小的性能挑战 |
||||
|
||||
善用离屏渲染 |
||||
|
||||
尽管离屏渲染开销很大,但是当我们无法避免它的时候,可以想办法把性能影响降到最低。优化思路也很简单:既然已经花了不少精力把图片裁出了圆角,如果我能把结果缓存下来,那么下一帧渲染就可以复用这个成果,不需要再重新画一遍了。 |
||||
|
||||
CALayer为这个方案提供了对应的解法:shouldRasterize。一旦被设置为true,Render Server就会强制把layer的渲染结果(包括其子layer,以及圆角、阴影、group opacity等等)保存在一块内存中,这样一来在下一帧仍然可以被复用,而不会再次触发离屏渲染。有几个需要注意的点: |
||||
|
||||
- shouldRasterize的主旨在于**降低性能损失,但总是至少会触发一次离屏渲染**。如果你的layer本来并不复杂,也没有圆角阴影等等,打开这个开关反而会增加一次不必要的离屏渲染 |
||||
- 离屏渲染缓存有空间上限,最多不超过屏幕总像素的2.5倍大小 |
||||
- 一旦缓存超过100ms没有被使用,会自动被丢弃 |
||||
- layer的内容(包括子layer)必须是静态的,因为一旦发生变化(如resize,动画),之前辛苦处理得到的缓存就失效了。如果这件事频繁发生,我们就又回到了“每一帧都需要离屏渲染”的情景,而这正是开发者需要极力避免的。针对这种情况,Xcode提供了“Color Hits Green and Misses Red”的选项,帮助我们查看缓存的使用是否符合预期 |
||||
- 其实除了解决多次离屏渲染的开销,shouldRasterize在另一个场景中也可以使用:如果layer的子结构非常复杂,渲染一次所需时间较长,同样可以打开这个开关,把layer绘制到一块缓存,然后在接下来复用这个结果,这样就不需要每次都重新绘制整个layer树了 |
||||
|
||||
什么时候需要CPU渲染 |
||||
|
||||
渲染性能的调优,其实始终是在做一件事:**平衡CPU和GPU的负载,让他们尽量做各自最擅长的工作**。 |
||||
|
||||
 |
||||
|
||||
平衡CPU和GPU的负载 |
||||
|
||||
绝大多数情况下,得益于GPU针对图形处理的优化,我们都会倾向于让GPU来完成渲染任务,而给CPU留出足够时间处理各种各样复杂的App逻辑。为此Core Animation做了大量的工作,尽量把渲染工作转换成适合GPU处理的形式(也就是所谓的硬件加速,如layer composition,设置backgroundColor等等)。 |
||||
|
||||
但是对于一些情况,如文字(CoreText使用CoreGraphics渲染)和图片(ImageIO)渲染,由于GPU并不擅长做这些工作,不得不先由CPU来处理好以后,再把结果作为texture传给GPU。除此以外,有时候也会遇到GPU实在忙不过来的情况,而CPU相对空闲(GPU瓶颈),这时可以让CPU分担一部分工作,提高整体效率。 |
||||
|
||||
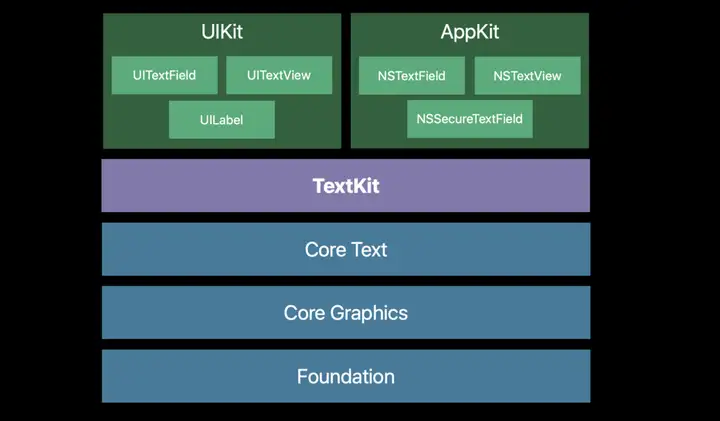 |
||||
|
||||
来自WWDC18 session 221,可以看到Core Text基于Core Graphics |
||||
|
||||
一个典型的例子是,我们经常会使用CoreGraphics给图片加上圆角(将图片中圆角以外的部分渲染成透明)。整个过程全部是由CPU完成的。这样一来既然我们已经得到了想要的效果,就不需要再另外给图片容器设置cornerRadius。另一个好处是,我们可以灵活地控制裁剪和缓存的时机,巧妙避开CPU和GPU最繁忙的时段,达到平滑性能波动的目的。 |
||||
|
||||
这里有几个需要注意的点: |
||||
|
||||
- 渲染不是CPU的强项,调用CoreGraphics会消耗其相当一部分计算时间,并且我们也不愿意因此阻塞用户操作,因此一般来说CPU渲染都在后台线程完成(这也是AsyncDisplayKit的主要思想),然后再回到主线程上,把渲染结果传回CoreAnimation。这样一来,多线程间数据同步会增加一定的复杂度 |
||||
- 同样因为CPU渲染速度不够快,因此只适合渲染静态的元素,如文字、图片(想象一下没有硬件加速的视频解码,性能惨不忍睹) |
||||
- 作为渲染结果的bitmap数据量较大(形式上一般为解码后的UIImage),消耗内存较多,所以应该在使用完及时释放,并在需要的时候重新生成,否则很容易导致OOM |
||||
- 如果你选择使用CPU来做渲染,那么就没有理由再触发GPU的离屏渲染了,否则会同时存在两块内容相同的内存,而且CPU和GPU都会比较辛苦 |
||||
- 一定要使用Instruments的不同工具来测试性能,而不是仅凭猜测来做决定 |
||||
|
||||
即刻的优化 |
||||
|
||||
由于在iOS10之后,系统的设计风格慢慢从扁平化转变成圆角卡片,即刻的设计风格也随之发生变化,加入了大量圆角与阴影效果,如果在处理上稍有不慎,就很容易触发离屏渲染。为此我们采取了以下一些措施: |
||||
|
||||
- 即刻大量应用AsyncDisplayKit(Texture)作为主要渲染框架,对于文字和图片的异步渲染操作交由框架来处理。关于这方面可以看我[之前的一些介绍](https://link.zhihu.com/?target=https%3A//medium.com/jike-engineering/asyncdisplaykit%E4%BB%8B%E7%BB%8D-%E4%B8%80-6b871d29e005) |
||||
- 对于图片的圆角,统一采用“precomposite”的策略,也就是不经由容器来做剪切,而是预先使用CoreGraphics为图片裁剪圆角 |
||||
- 对于视频的圆角,由于实时剪切非常消耗性能,我们会创建四个白色弧形的layer盖住四个角,从视觉上制造圆角的效果 |
||||
- 对于view的圆形边框,如果没有backgroundColor,可以放心使用cornerRadius来做 |
||||
- 对于所有的阴影,使用shadowPath来规避离屏渲染 |
||||
- 对于特殊形状的view,使用layer mask并打开shouldRasterize来对渲染结果进行缓存 |
||||
- 对于模糊效果,不采用系统提供的UIVisualEffect,而是另外实现模糊效果(CIGaussianBlur),并手动管理渲染结果 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/72653360 |
||||
@ -0,0 +1,341 @@ |
||||
# 资深程序员的Metal入门教程总结 |
||||
|
||||
## 1、Metal |
||||
|
||||
Metal 是一个和 OpenGL ES 类似的面向底层的图形编程接口,可以直接操作GPU;支持iOS和OS X,提供图形渲染和通用计算能力。(不支持模拟器) |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
图片来源 [https://www.invasivecode.com/weblog/metal-image-processing](https://link.zhihu.com/?target=https%3A//www.invasivecode.com/weblog/metal-image-processing) |
||||
|
||||
MTLDevice 对象代表GPU,通常使用MTLCreateSystemDefaultDevice获取默认的GPU; MTLCommandQueue由device创建,用于创建和组织MTLCommandBuffer,保证指令(MTLCommandBuffer)有序地发送到GPU;MTLCommandBuffer会提供一些encoder,包括编码绘制指令的MTLRenderCommandEncoder、编码计算指令的MTLComputeCommandEncoder、编码缓存纹理拷贝指令的MTLBlitCommandEncoder。对于一个commandBuffer,只有调用encoder的结束操作,才能进行下一个encoder的创建,同时可以设置执行完指令的回调。 每一帧都会产生一个MTLCommandBuffer对象,用于填放指令; GPUs的类型很多,每一种都有各自的接收和执行指令方式,在MTLCommandEncoder把指令进行封装后,MTLCommandBuffer再做聚合到一次提交里。 MTLRenderPassDescriptor 是一个轻量级的临时对象,里面存放较多属性配置,供MTLCommandBuffer创建MTLRenderCommandEncoder对象用。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
MTLRenderPassDescriptor 用来更方便创建MTLRenderCommandEncoder,由MetalKit的view设置属性,并且在每帧刷新时都会提供新的MTLRenderPassDescriptor;MTLRenderCommandEncoder在创建的时候,会隐式的调用一次clear的命令。 最后再调用present和commit接口。 |
||||
|
||||
Metal的viewport是3D的区域,包括宽高和近/远平面。 |
||||
|
||||
深度缓冲最大值为1,最小值为0,如下面这两个都不会显示。 |
||||
|
||||
```js |
||||
// clipSpacePosition为深度缓冲 |
||||
out.clipSpacePosition = vector_float4(0.0, 0.0, -0.1, 1.0); |
||||
out.clipSpacePosition = vector_float4(0.0, 0.0, 1.1, 1.0); |
||||
``` |
||||
|
||||
### 1.1渲染管道 |
||||
|
||||
Metal把输入、处理、输出的管道看成是对指定数据的渲染指令,比如输入顶点数据,输出渲染后纹理。 MTLRenderPipelineState 表示渲染管道,最主要的三个过程:顶点处理、光栅化、片元处理: |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
转换几何形状数据为帧缓存中的颜色像素,叫做点阵化(rasterizing),也叫光栅化。其实就是根据顶点的数据,检测像素中心是否在三角形内,确定具体哪些像素需要渲染。 对开发者而言,顶点处理和片元处理是可编程的,光栅化是固定的(不可见)。 顶点函数在每个顶点被绘制时都会调用,比如说绘制一个三角形,会调用三次顶点函数。顶点处理函数返回的对象里,必须有带[[position]]描述符的属性,表面这个属性是用来计算下一步的光栅化;返回值没有描述符的部分,则会进行插值处理。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
插值处理 |
||||
|
||||
像素处理是针对每一个要渲染的像素进行处理,返回值通常是4个浮点数,表示RGBA的颜色。 |
||||
|
||||
在编译的时候,Xcode会单独编译.metal的文件,但不会进行链接;需要在app运行时,手动进行链接。 在包里,可以看到default.metallib,这是对metal shader的编译结果。 |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
MTLFunction可以用来创建MTLRenderPipelineState对象,MTLRenderPipelineState代表的是图形渲染的管道; 在调用device的newRenderPipelineStateWithDescriptor:error接口时,会进行顶点、像素函数的链接,形成一个图像处理管道; MTLRenderPipelineDescriptor包括名称、顶点处理函数、片元处理函数、输出颜色格式。 |
||||
|
||||
`setVertexBytes:length:atIndex:`这接口的长度限制是4k(4096bytes),对于超过的场景应该使用MTLBuffer。MTLBuffer是GPU能够直接读取的内存,用来存储大量的数据;(常用于顶点数据) `newBufferWithLength:options:`方法用来创建MTLBuffer,参数是大小和访问方式;MTLResourceStorageModeShared是默认的访问方式。 |
||||
|
||||
### 1.2纹理 |
||||
|
||||
Metal要求所有的纹理都要符合MTLPixelFormat上面的某一种格式,每个格式都代表对图像数据的不同描述方式。 例如MTLPixelFormatBGRA8Unorm格式,内存布局如下: |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
每个像素有32位,分别代表BRGA。 MTLTextureDescriptor 用来设置纹理属性,例如纹理大小和像素格式。 MTLBuffer用于存储顶点数据,MTLTexture则用于存储纹理数据;MTLTexture在创建之后,需要调用`replaceRegion:mipmapLevel:withBytes:bytesPerRow:`填充纹理数据;因为图像数据一般按行进行存储,所以需要每行的像素大小。 |
||||
|
||||
[[texture(index)]] 用来描述纹理参数,比如说 `samplingShader(RasterizerData in [[stage_in]], texture2d<half> colorTexture [[ texture(AAPLTextureIndexBaseColor) ]])` 在读取纹理的时候,需要两个参数,一个是sampler和texture coordinate,前者是采样器,后者是纹理坐标。 读取纹理其实就把对应纹理坐标的像素颜色读取出来。 纹理坐标默认是(0,0)到(1,1),如下: |
||||
|
||||
|
||||
|
||||
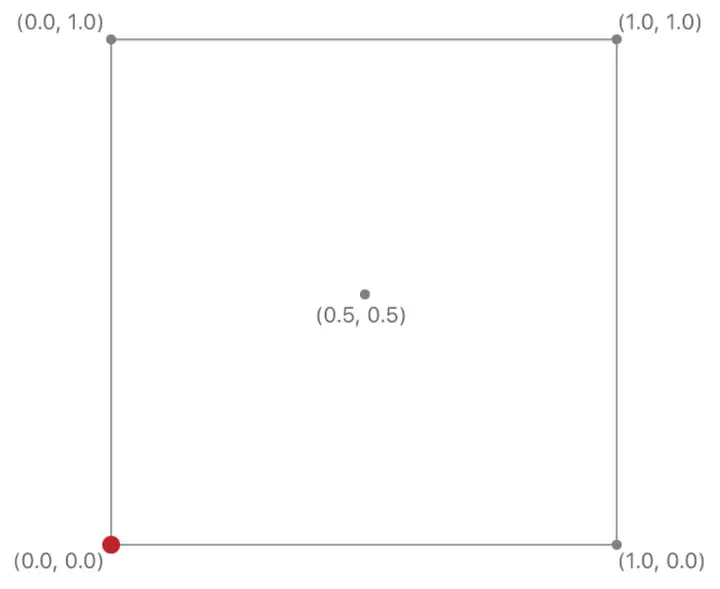 |
||||
|
||||
|
||||
|
||||
有时候,纹理的坐标会超过1,采样器会根据事前设置的mag_filter::参数进行计算。 |
||||
|
||||
### 1.3通用计算 |
||||
|
||||
通用图形计算是general-purpose GPU,简称GPGPU。 GPU可以用于加密、机器学习、金融等,图形绘制和图形计算并不是互斥的,Metal可以同时使用计算管道进行图形计算,并且用渲染管道进行渲染。 |
||||
|
||||
计算管道只有一个步骤,就是kernel function(内核函数),内核函数直接读取并写入资源,不像渲染管道需要经过多个步骤; MTLComputePipelineState 代表一个计算处理管道,只需要一个内核函数就可以创建,相比之下,渲染管道需要顶点和片元两个处理函数; |
||||
|
||||
每次内核函数执行,都会有一个唯一的gid值; 内核函数的执行次数需要事先指定,这个次数由格子大小决定。 |
||||
|
||||
threadgroup 指的是设定的处理单元,这个值要根据具体的设备进行区别,但必须是足够小的,能让GPU执行; threadgroupCount 是需要处理的次数,一般来说threadgroupCount*threadgroup=需要处理的大小。 |
||||
|
||||
### 1.4性能相关 |
||||
|
||||
临时对象(创建和销毁是廉价的,它们的创建方法都返回 autoreleased对象) 1.Command Buffers 2.Command Encoders 代码中不需要持有。 |
||||
|
||||
高消耗对象(在性能相关的代码里应该尽量重用它,避免反复创建) 1.Command Queues 2.Buffers 3.Textures 5.Compute States 6.Render Pipeline States 代码中需长期持有。 |
||||
|
||||
Metal常用的四种数据类型:half、float、short(ushort)、int(uint)。 GPU的寄存器是16位,half是性能消耗最低的数据类型;float需要两次读取、消耗两倍的寄存器空间、两倍的带宽、两倍的电量。 为了提升性能,half和float之间的转换由硬件来完成,不占用任何开销。 同时,Metal自带的函数都是经过优化的。 在float和half数据类型混合的计算中,为了保持精度会自动将half转成float来处理,所以如果想用half节省开销的话,要避免和float混用。 Metal同样不擅长处理control flow,应该尽可能使用使用三元表达式,取代简单的if判断。 |
||||
|
||||
> 此部分参考自[WWDC](https://link.zhihu.com/?target=https%3A//developer.apple.com/videos/play/wwdc2016/606) |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
常见的图形渲染管道 |
||||
|
||||
## 2、Metal Shader Language** |
||||
|
||||
Metal Shader Language的使用场景有两个,分别是图形渲染和通用计算;基于C++ 14,运行在GPU上,GPU的特点:带宽大,并行处理,内存小,对条件语句处理较慢(等待时间长)。 Metal着色语言使用clang和 LLVM,支持重载函数,但不支持图形渲染和通用计算入口函数的重载、递归函数调用、new和delete操作符、虚函数、异常处理、函数指针等,也不能用C++ 11的标准库。 |
||||
|
||||
### 2.1基本函数 |
||||
|
||||
shader有三个基本函数: |
||||
|
||||
- 顶点函数(vertex),对每个顶点进行处理,生成数据并输出到绘制管线; |
||||
- 像素函数(fragment),对光栅化后的每个像素点进行处理,生成数据并输出到绘制管线; |
||||
- 通用计算函数(kernel),是并行计算的函数,其返回值类型必须为void; |
||||
|
||||
顶点函数相关的修饰符: |
||||
|
||||
- [[vertex_id]] vertex_id是顶点shader每次处理的index,用于定位当前的顶点 |
||||
- [[instance_id]] instance_id是单个实例多次渲染时,用于表明当前索引; |
||||
- [[clip_distance]],float 或者 float[n], n必须是编译时常量; |
||||
- [[point_size]],float; |
||||
- [[position]],float4; |
||||
|
||||
如果一个顶点函数的返回值不是void,那么返回值必须包含顶点位置; 如果返回值是float4,默认表示位置,可以不带[[ position ]]修饰符; 如果一个顶点函数的返回值是结构体,那么结构体必须包含“[[ position ]]”修饰的变量。 |
||||
|
||||
像素函数相关的修饰符: |
||||
|
||||
- [[color(m)]] float或half等,m必须是编译时常量,表示输入值从一个颜色attachment中读取,m用于指定从哪个颜色attachment中读取; |
||||
- [[front_facing]] bool,如果像素所属片元是正面则为true; |
||||
- [[point_coord]] float2,表示点图元的位置,取值范围是0.0到1.0; |
||||
- [[position]] float4,表示像素对应的窗口相对坐标(x, y, z, 1/w); |
||||
- [[sample_id]] uint,The sample number of the sample currently being processed. |
||||
- [[sample_mask]] uint,The set of samples covered by the primitive generating the fragmentduring multisample rasterization. |
||||
|
||||
以上都是输入相关的描述符。**像素函数的返回值是单个像素的输出,包括一个或是多个渲染结果颜色值,一个深度值,还有一个sample遮罩**,对应的输出描述符是[[color(m)]] floatn、[[depth(depth_qualifier)]] float、[[sample_mask]] uint。 |
||||
|
||||
```js |
||||
struct LYFragmentOutput { |
||||
// color attachment 0 |
||||
float4 color_float [[color(0)]];// color attachment 1 |
||||
int4 color_int4 [[color(1)]];// color attachment 2 |
||||
uint4 color_uint4 [[color(2)]];}; |
||||
fragment LYFragmentOutput fragment_shader( ... ) { ... }; |
||||
``` |
||||
|
||||
需要注意,颜色attachment的参数设置要和像素函数的输入和输出的数据类型匹配。 |
||||
|
||||
> Metal支持一个功能,叫做前置深度测试(early depth testing),允许在像素着色器运行之前运行深度测试。如果一个像素被覆盖,则会放弃渲染。使用方式是在fragment关键字前面加上[[early_fragment_tests]]: `[[early_fragment_tests]] fragment float4 samplingShader(..)` 使用前置深度测试的要求是不能在fragment shader对深度进行写操作。 深度测试还不熟悉的,可以看[LearnOpenGL关于深度测试的介绍](https://link.zhihu.com/?target=https%3A//learnopengl-cn.readthedocs.io/zh/latest/04%20Advanced%20OpenGL/01%20Depth%20testing/)。 |
||||
|
||||
### 2.2参数的地址空间选择 |
||||
|
||||
Metal种的内存访问主要有两种方式:Device模式和Constant模式,由代码中显式指定。 Device模式是比较通用的访问模式,使用限制比较少,而Constant模式是为了多次读取而设计的快速访问只读模式,通过Constant内存模式访问的参数的数据的字节数量是固定的,特点总结为: |
||||
|
||||
- Device支持读写,并且没有size的限制; |
||||
- Constant是只读,并且限定大小; |
||||
|
||||
如何选择Device和Constant模式? 先看数据size是否会变化,再看访问的频率高低,只有那些固定size且经常访问的部分适合使用constant模式,其他的均用Device。 |
||||
|
||||
```js |
||||
// Metal关键函数用到的指针参数要用地址空间修饰符(device, threadgroup, or constant) 如下 |
||||
vertex RasterizerData // 返回给片元着色器的结构体 |
||||
vertexShader(uint vertexID [[ vertex_id ]], // vertex_id是顶点shader每次处理的index,用于定位当前的顶点 |
||||
constant LYVertex *vertexArray [[ buffer(0) ]]); // buffer表明是缓存数据,0是索引 |
||||
``` |
||||
|
||||
|
||||
|
||||
 |
||||
|
||||
|
||||
|
||||
地址空间的修饰符共有四个,device、threadgroup、constant、thread。 顶点函数(vertex)、像素函数(fragment)、通用计算函数(kernel)的指针或引用参数,都必须带有地址空间修饰符号。 对于顶点函数(vertex)和像素函数(fragment),其指针或引用参数必须定义在device或是constant地址空间; 对于通用计算函数(kernel),其指针或引用参数必须定义在device或是threadgroup或是constant地址空间; `void tranforms(device int *source_data, threadgroup int *dest_data, constant float *param_data) {/*...*/};` 如上使用了三种地址空间修饰符,因为有threadgroup修饰符,tranforms函数只能被通用计算函数调用。 |
||||
|
||||
**constant地址空间**用于从设备内存池分配存储的缓存对象,是只读的。constant地址空间的指针或引用可以做函数的参数,向声明为常量的变量赋值会产生编译错误,声明常量但是没有赋予初始值也会产生编译错误。 **在shader中,函数之外的变量(相当于全局变量),其地址空间必须是constant。** |
||||
|
||||
**device地址空间**用于从设备内存池分配出来的缓存对象,可读也可写。一个缓存对象可以被声明成一个标量、向量或是用户自定义结构体的指针或是引用。缓存对象使用的内存实际大小,应该在CPU侧调用时就确定。 **纹理对象总是在device地址空间分配内存**,所以纹理类型可以省略修饰符。 |
||||
|
||||
**threadgroup地址空间**用于通用计算函数变量的内存分配,变量被一个线程组的所有的线程共享,threadgroup地址空间分配的变量不能用于图形绘制函数。 |
||||
|
||||
**thread地址空间**用于每个线程内部的内存分配,被thread修饰的变量在其他线程无法访问,在图形绘制或是通用计算函数内声明的变量是thread地址空间分配。 如下一段代码,包括device、threadgroup、thread的使用: |
||||
|
||||
```js |
||||
typedef struct |
||||
{ |
||||
half3 kRec709Luma; // position的修饰符表示这个是顶点 |
||||
|
||||
} TransParam; |
||||
|
||||
kernel void |
||||
sobelKernel(texture2d<half, access::read> sourceTexture [[texture(LYFragmentTextureIndexTextureSource)]], |
||||
texture2d<half, access::write> destTexture [[texture(LYFragmentTextureIndexTextureDest)]], |
||||
uint2 grid [[thread_position_in_grid]], |
||||
device TransParam *param [[buffer(0)]], // param.kRec709Luma = half3(0.2126, 0.7152, 0.0722); // 把rgba转成亮度值 |
||||
threadgroup float3 *localBuffer [[threadgroup(0)]]) // threadgroup地址空间,这里并没有使用到; |
||||
{ |
||||
// 边界保护 |
||||
if(grid.x <= destTexture.get_width() && grid.y <= destTexture.get_height()) |
||||
{ |
||||
thread half4 color = sourceTexture.read(grid); // 初始颜色 |
||||
thread half gray = dot(color.rgb, half3(param->kRec709Luma)); // 转换成亮度 |
||||
destTexture.write(half4(gray, gray, gray, 1.0), grid); // 写回对应纹理 |
||||
} |
||||
} |
||||
``` |
||||
|
||||
### 2.3数据结构 |
||||
|
||||
Metal中常用的数据结构有向量、矩阵、原子数据类型、缓存、纹理、采样器、数组、用户自定义结构体。 |
||||
|
||||
half 是16bit是浮点数 0.5h float 是32bit的浮点数 0.5f size_t 是64bit的无符号整数 通常用于sizeof的返回值 ptrdiff_t 是64bit的有符号整数 通常用于指针的差值 half2、half3、half4、float2、float3、float4等,是向量类型,表达方式为基础类型+向量维数。矩阵类似half4x4、half3x3、float4x4、float3x3。 double、long、long long不支持。 |
||||
|
||||
对于向量的访问,比如说`vec=float4(1.0f, 1.0f, 1.0f, 1.0f)`,其访问方式可以是vec[0]、vec[1],也可以是vec.x、vec.y,也可以是vec.r、vec.g。(.xyzw和.rgba,前者对应三维坐标,后者对应RGB颜色空间) 只取部分、乱序取均可,比如说我们常用到的`color=texture.bgra`。 |
||||
|
||||
> **数据对齐** char3、uchar3的size是4Bytes,而不是3Bytes; 类似的,int是4Bytes,但int3是16而不是12Bytes; 矩阵是由一组向量构成,按照向量的维度对齐;float3x3由3个float3向量构成,那么每个float3的size是16Bytes; **隐式类型转换**(Implicit Type Conversions) 向量到向量或是标量的隐式转换会导致编译错误,比如`int4 i; float4 f = i; // compile error`,无法将一个4维的整形向量转换为4维的浮点向量。 标量到向量的隐式转换,是标量被赋值给向量的每一个分量。 `float4 f = 2.0f; // f = (2.0f, 2.0f, 2.0f, 2.0f)` 标量到矩阵、向量到矩阵的隐式转换,矩阵到矩阵和向量及标量的隐式转换会导致编译错误。 |
||||
|
||||
纹理数据结构不支持指针和引用,纹理数据结构包括精度和access描述符,access修饰符描述纹理如何被访问,有三种描述符:sample、read、write,如下: |
||||
|
||||
```js |
||||
kernel void |
||||
sobelKernel(texture2d<half, access::read> sourceTexture [[texture(LYFragmentTextureIndexTextureSource)]], |
||||
texture2d<half, access::write> destTexture [[texture(LYFragmentTextureIndexTextureDest)]], |
||||
uint2 grid [[thread_position_in_grid]]) |
||||
``` |
||||
|
||||
Sampler是采样器,决定如何对一个纹理进行采样操作。寻址模式,过滤模式,归一化坐标,比较函数。 在Metal程序里初始化的采样器必须使用constexpr修饰符声明。 采样器指针和引用是不支持的,将会导致编译错误。 |
||||
|
||||
```js |
||||
constexpr sampler textureSampler (mag_filter::linear, |
||||
min_filter::linear); // sampler是采样器 |
||||
``` |
||||
|
||||
### 2.4运算符 |
||||
|
||||
- 矩阵相乘有一个操作数是标量,那么这个标量和矩阵中的每一个元素相乘,得到一个和矩阵有相同行列的新矩阵。 |
||||
- 右操作数是一个向量,那么它被看做一个列向量,如果左操作数是一个向量,那么他被看做一个行向量。这个也说明,为什么我们要固定用mvp乘以position(左乘矩阵),而不能position乘以mvp!因为两者的处理结果不一致。 |
||||
|
||||
## 3、Metal和OpenGL ES的差异 |
||||
|
||||
OpenGL的历史已经超过25年。基于当时设计原则,OpenGL不支持多线程,异步操作,还有着臃肿的特性。为了更好利用GPU,苹果设计了Metal。 Metal的目标包括更高效的CPU&GPU交互,减少CPU负载,支持多线程执行,可预测的操作,资源控制和同异步控制;接口与OpenGL类似,但更加切合苹果设计的GPUs。 |
||||
|
||||
|
||||
|
||||
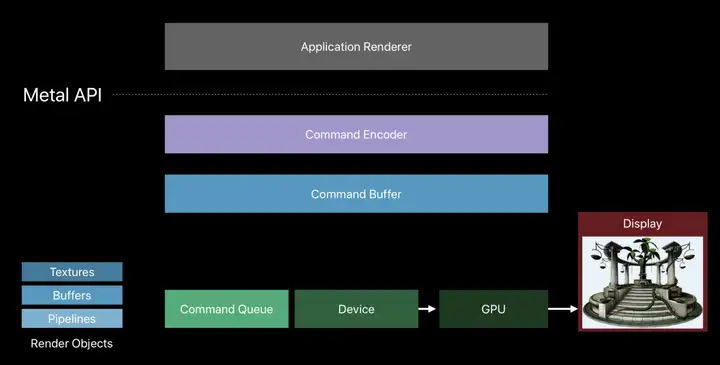 |
||||
|
||||
|
||||
|
||||
Metal的关系图 |
||||
|
||||
Metal的关系图如上,其中的Device是GPU设备的抽象,负责管道相关对象的创建: |
||||
|
||||
|
||||
|
||||
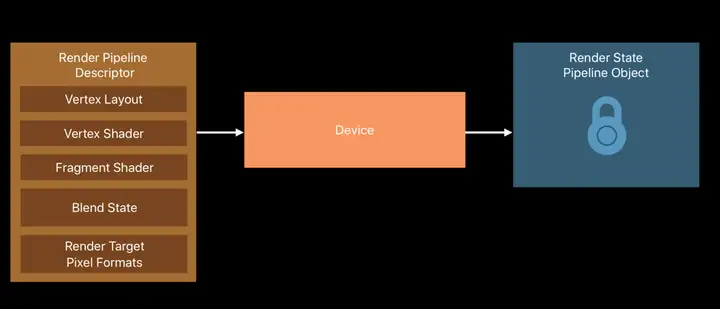 |
||||
|
||||
|
||||
|
||||
Device |
||||
|
||||
### 3.1Metal和OpenGL ES的代码对比 |
||||
|
||||
我们先看一段OpenGL ES的渲染代码,我们可以抽象为Render Targets的设定,Shaders绑定,设置Vertex Buffers、Uniforms和Textures,最后调用Draws指令。 |
||||
|
||||
```js |
||||
glBindFramebuffer(GL_FRAMEBUFFER, myFramebuffer); |
||||
glUseProgram(myProgram); |
||||
glBindBuffer(GL_ARRAY_BUFFER, myVertexBuffer); |
||||
glBindBuffer(GL_UNIFORM_BUFFER, myUniforms); |
||||
glBindTexture(GL_TEXTURE_2D, myColorTexture); |
||||
glDrawArrays(GL_TRIANGLES, 0, numVertices); |
||||
``` |
||||
|
||||
|
||||
|
||||
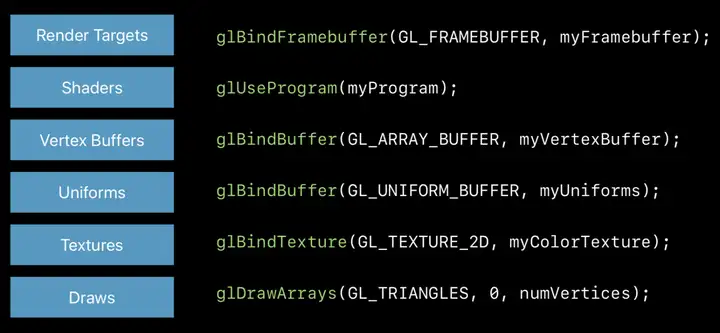 |
||||
|
||||
|
||||
|
||||
再看Metal的渲染代码: Render Targets设定 是创建encoder; Shaders绑定 是设置pipelineState; 设置Vertex Buffers、Uniforms和Textures 是setVertexBuffer和setFragmentBuffer; 调用Draws指令 是drawPrimitives; 最后需要再调用一次endEncoding。 |
||||
|
||||
```js |
||||
encoder = [commandBuffer renderCommandEncoderWithDescriptor:descriptor]; [encoder setPipelineState:myPipeline]; |
||||
[encoder setVertexBuffer:myVertexData offset:0 atIndex:0]; |
||||
[encoder setVertexBuffer:myUniforms offset:0 atIndex:1]; |
||||
[encoder setFragmentBuffer:myUniforms offset:0 atIndex:1]; |
||||
[encoder setFragmentTexture:myColorTexture atIndex:0]; |
||||
[encoder drawPrimitives:MTLPrimitiveTypeTriangle vertexStart:0 vertexCount:numVertices]; |
||||
[encoder endEncoding]; |
||||
``` |
||||
|
||||
|
||||
|
||||
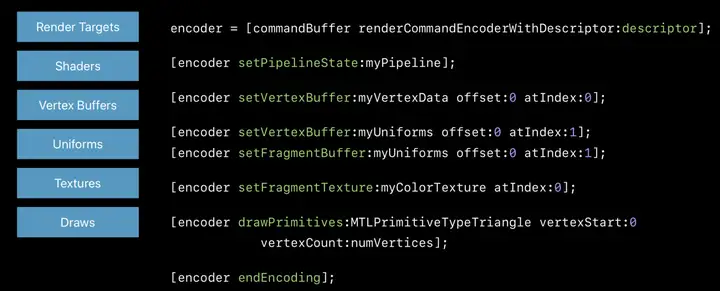 |
||||
|
||||
|
||||
|
||||
### 3.2Metal和OpenGL ES的同异步处理 |
||||
|
||||
如下图,是用OpenGL ES实现一段渲染的代码。CPU在Frame1的回调中写入数据到buffer,之后GPU会从buffer中读取Frame1写入的数据。 |
||||
|
||||
|
||||
|
||||
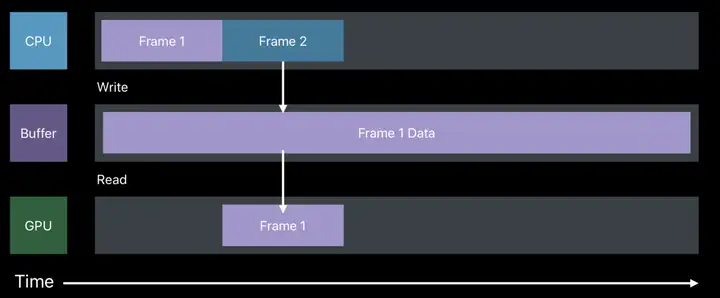 |
||||
|
||||
|
||||
|
||||
但在Frame2 CPU在往Buffer写入数据时,Buffer仍存储着Frame1的数据,且GPU还在使用该buffer,于是Frame2必须等待Frame1渲染完毕,造成阻塞。如下,会产生CPU的wait和GPU的idle。 |
||||
|
||||
|
||||
|
||||
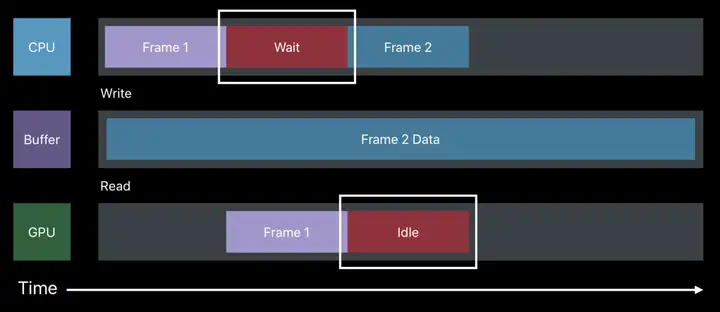 |
||||
|
||||
|
||||
|
||||
Metal的处理方案会更加高效。如下图,Metal会申请三个buffer对应三个Frame,然后根据GPU的渲染回调,实时更新buffer的缓存。 在Frame2的时候,CPU会操作Buffer2,而GPU会读取Buffer1,并行操作以提高效率。 |
||||
|
||||
|
||||
|
||||
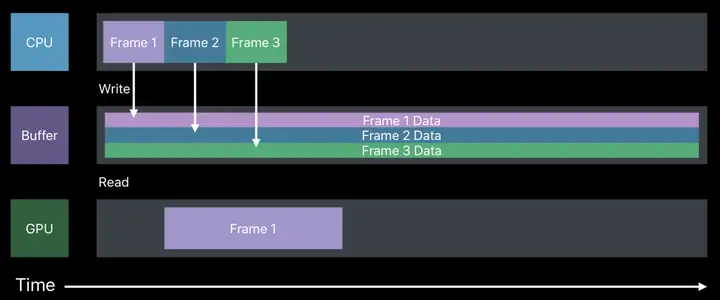 |
||||
|
||||
|
||||
|
||||
## 4.总结 |
||||
|
||||
[Metal系列入门教程](https://link.zhihu.com/?target=https%3A//github.com/loyinglin/LearnMetal)介绍了Metal的图片绘制、三维变换、视频渲染、天空盒、计算管道、Metal与OpenGL ES交互。结合本文的总结,能对Metal产生基本的认知,看懂大部分Metal渲染的代码。 接下来的学习方向是Metal进阶,包括Metal滤镜链的设计与实现、多重colorAttachments渲染、绿幕功能实现、更复杂的通用计算比如MPSImageHistogram,Shader的性能优化等。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/48245068 |
||||
@ -0,0 +1,175 @@ |
||||
# 音视频学习--iOS适配H265实战踩坑记 |
||||
|
||||
## 1.背景介绍 |
||||
|
||||
熟悉webrtc都知道:谷歌的webrtc,默认不支持h265,毕竟涉及到很多专利的事宜,这中间的八卦就暂时不做探究。但是今天拿到一个IPC,该设备会发送H265数据,如下图所示,要做到兼容相关IPC,只能适配H265编解码了。所以最近熬秃了好几把头发就做了一下相关知识的学习,以下是自己的学习笔记,提供大家一个解决问题思路,由于iOS刚接触,同时H265调试经验也欠缺,很多都是一边查找资料,一边学习的,难免有处理不妥当之处,欢迎一起讨论学习,开发大神请绕行。 |
||||
|
||||
 |
||||
|
||||
## 2.补充1H265编码特性 |
||||
|
||||
学习之前先了解一下H265的编码特性,有的放矢才能遇到问题及时排查。H265的经典编码框架如下图: |
||||
|
||||
|
||||
|
||||
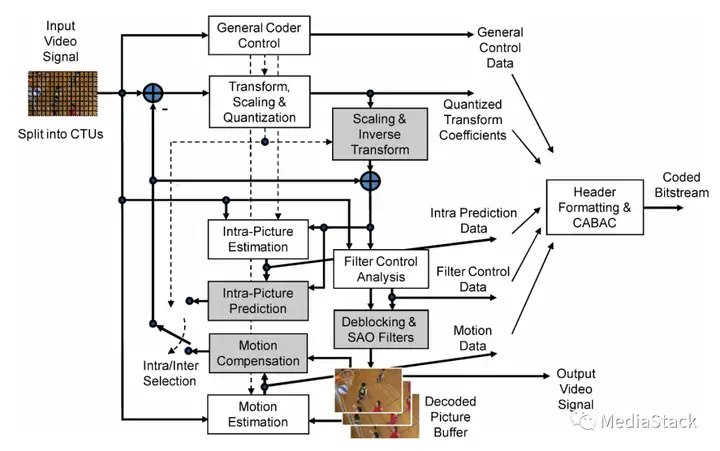 |
||||
|
||||
HEVC 的编码框架是在H26X的基础上逐步发展起来的,主要包括变换、量化、熵编码、帧内预测、帧间预测以及环路滤波等模块。相关内容推荐阅读万帅老师的书《新一代高效视频编码H.265/HEVC:原理、标准与实现》。 |
||||
|
||||
一般提到H265,都难免要和H264对比一番,以下是这次需求端要求适配H265的基本理论依据,如下表格: |
||||
|
||||
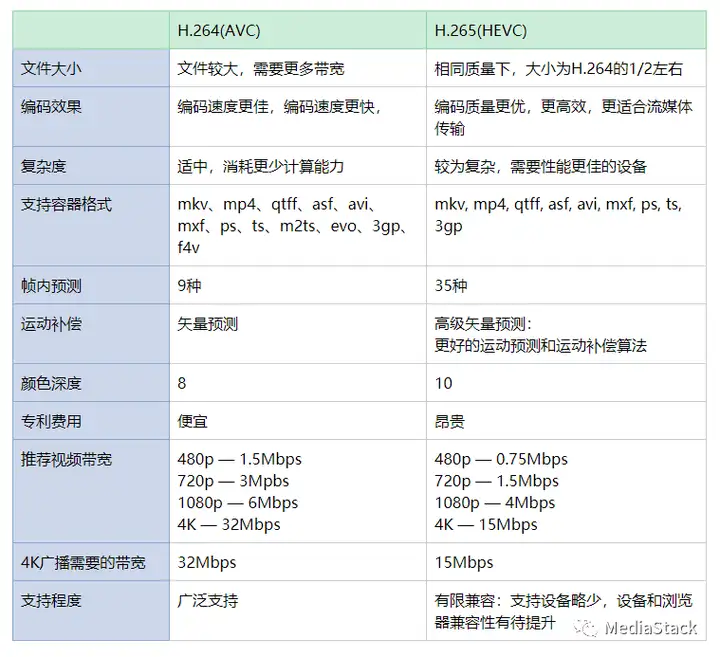 |
||||
|
||||
理论上要直接适配一种编解码格式,肯定要学习相关理论,然后再做对应适配。然而时间紧张,任务繁杂,根本没有足够时间积累。想要有一个全面直观的认识,同时为了验证IPC是否正常,所以首先用VLC进行播放尝试:PC端确认该IPC可以通过 VLC进行监控,这时我们可以通过wireshark抓包,拿到第一手数据进行分析。通过抓包可以看出:1920*1080的视频流除了IDR数据帧大小略大,其他数据都是一个NALU单元就完成封装了,文件大小确实小很多。 |
||||
|
||||
接下来我们依次认识H265的封包和关键信息。 |
||||
|
||||
## 3.H265关键信息 |
||||
|
||||
通过相关抓包,可以看到整理结构如下图,包含了VPS,SPS,PPS, FU分片包,Trail_R的包等。 |
||||
|
||||
 |
||||
|
||||
 |
||||
|
||||
### 3.1VPS结构 |
||||
|
||||
VPS(Video Parameter Set, 视频参数集)依据ITUHEVC的标准文档,VPS的参数结构以及每一个条款的解释,很多大佬已经有写明了,HEVC来说自己还是小萌新在此不再累述,可以参考自己关注的一个大佬的博文: |
||||
|
||||
A//blog.csdn.net/Dillon2015/article/details/104142144) |
||||
|
||||
其抓包中VPS数据参数如下: |
||||
|
||||
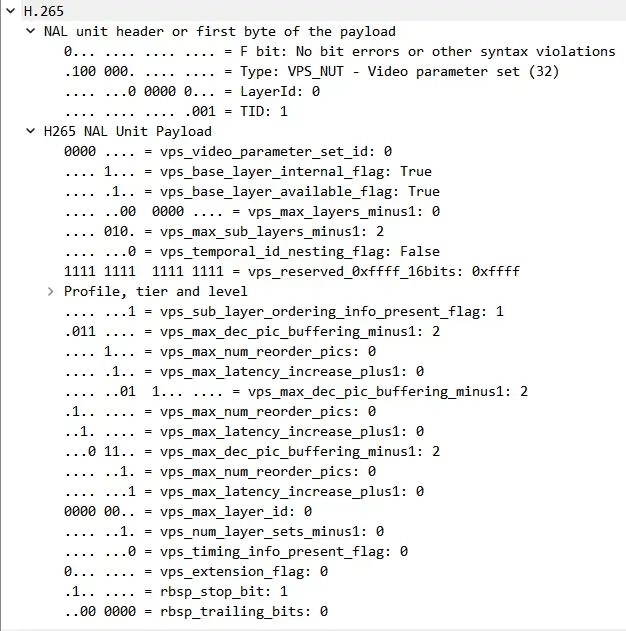 |
||||
|
||||
### 3.2SPS结构 |
||||
|
||||
SPS的内容大致包括解码相关信息,如档次级别、分辨率、某档次中编码工具开关标识和涉及的参数、时域可分级信息等。 |
||||
|
||||
其抓包中SPS数据参数如下: |
||||
|
||||
 |
||||
|
||||
### 3.3PPS结构 |
||||
|
||||
HEVC的图像参数集PPS包含每一帧可能不同的设置信息;其内容大致包括初始图像控制信息,如量化参数(QP,Quantization Parament)、分块信息等。即PPS包含了每一帧图像所用的公共参数,即一帧图像中的所有SS会引用同一个PPS;每张图像的PPS可能不同。详细介绍说明可以参考: |
||||
|
||||
其抓包中PPS数据参数如下: |
||||
|
||||
 |
||||
|
||||
有了这些数据,至少可以解析出来该IPC支持的分辨率,profile,level等基本数据信息,为初始化做准备。 |
||||
|
||||
## 4.H265解封包 |
||||
|
||||
由上面信息可以知道H265的封包格式和H264基本上保持一致,也是通过NALU单元进行分装,不过不太一样的地方是 H265的NALU Header长度是2个字节,而 H264的NALU Header的长度是1个字节,所以解析时候需要进行移位操作,否则读取数据异常,导致包类型无法辨别(在这里踩了一个小坑,印象深刻)。 |
||||
|
||||
H26封包中NALU type主要类型如下图所示。由于不同厂家支持程度不一,本次适配过程中主要关注的几个类型包括:kTrailR(1),kIdrwRadl(1),kVps(1),kSps(1),kPps(1),kFU(1)等。 |
||||
|
||||
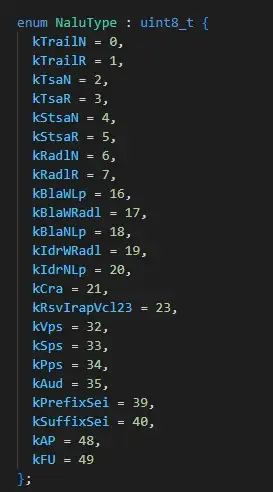 |
||||
|
||||
### 4.1FUNALU |
||||
|
||||
当 NALU 的长度超过 MTU 时, 用于把当前NALU单元封装成多个 RTP 包,HEVC的FU单元的type值为49,具体组织结构如下: |
||||
|
||||
 |
||||
|
||||
FU Nalu相关解析代码如下: |
||||
|
||||
 |
||||
|
||||
### 4.2SingleNALU |
||||
|
||||
单个 NAL 单元数据包只包含一个 NAL 单元,由一个有效载荷头(表示为 PayloadHdr)、一个有条件的16位DONL字段和NAL 单元有效载荷数据。 |
||||
|
||||
 |
||||
|
||||
### 4.3AP NALU |
||||
|
||||
HEVC封包另外一个种封包格式:聚合模式(Aggregation Packets,APs),主要为了减少小型 NAL 单元的打包开销,例如大多数非 VCL NAL 单元,它们的大小通常只有几个字节。AP 将 NAL 单元聚合在一个访问单元内。AP 中要携带的每个 NAL 单元都封装在聚合单元中。聚合在一个 AP 中的 NAL 单元按 NAL 单元解码顺序排列。 |
||||
|
||||
 |
||||
|
||||
AP Nalu和Single Nalu相关代码解析如下: |
||||
|
||||
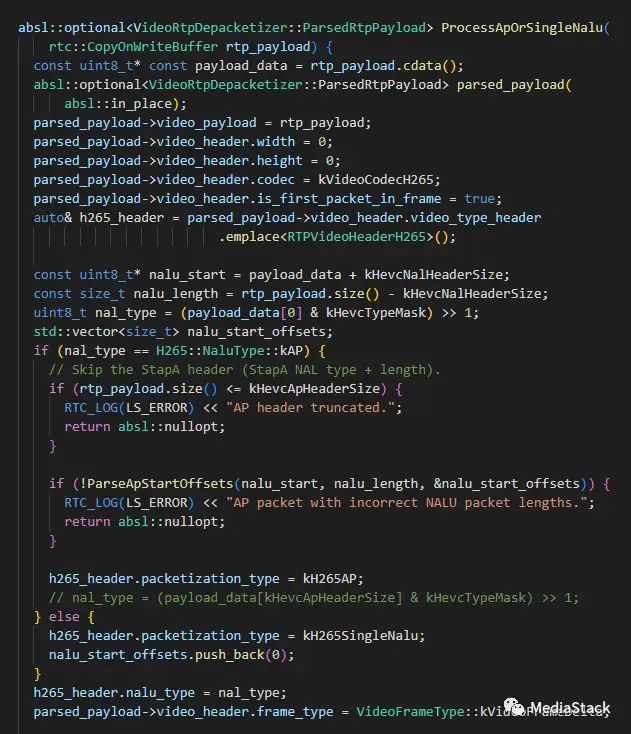 |
||||
|
||||
当接收到每一个HEVC包之后,一次送到Jitterbuffer中,完成数据帧的重新组装和排序,必要时候进行数据矫正和重传操作,这是另外的技术,此处暂不做讨论。 |
||||
|
||||
## 5.H265 VideoToolBox解码 |
||||
|
||||
收到完整数据帧时候,VCM会依据时间戳一次获取相关数据,送解码器,iOS平台就是VideoToolBox解码了。这部分自己是小白,简单说明关键函数,大佬勿喷。 |
||||
|
||||
### 5.1ResetDecompressionSession |
||||
|
||||
ResetDecompressionSession完成解码参数的构建,以及Session的创建。主要注意iOS支持的色彩是有差别的,设置时候需要明确是否支持,比如这次就设置了kCVPixelFormatType_420YpCbCr8BiPlanarFullRange类型。 |
||||
|
||||
同时在reset函数中注册callback函数,用于接收解码完成后的视频帧。 |
||||
|
||||
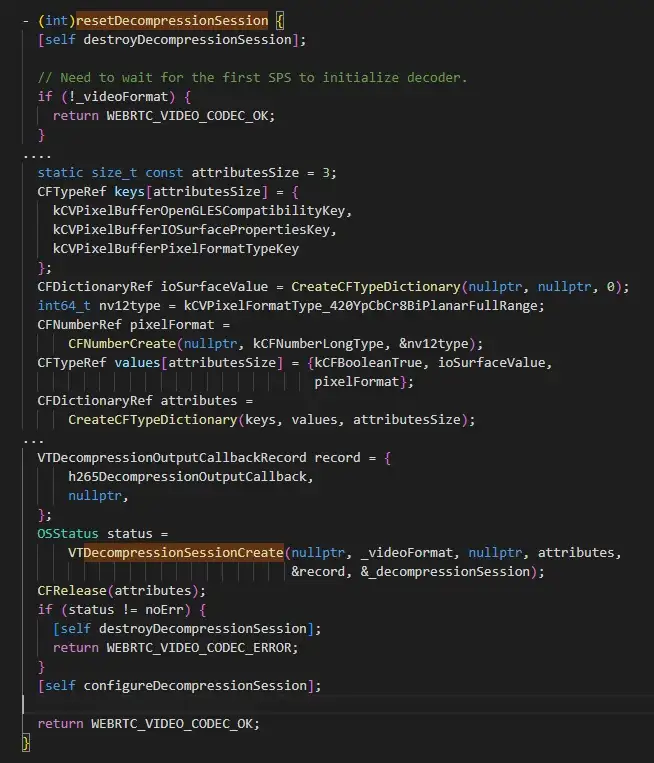 |
||||
|
||||
### 5.2decode |
||||
|
||||
iOS VideoToolBox相关开发说明,可以参考 |
||||
|
||||
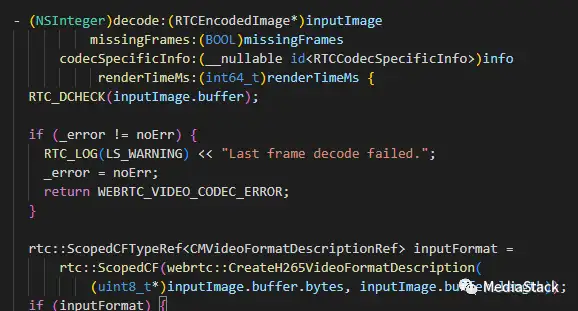 |
||||
|
||||
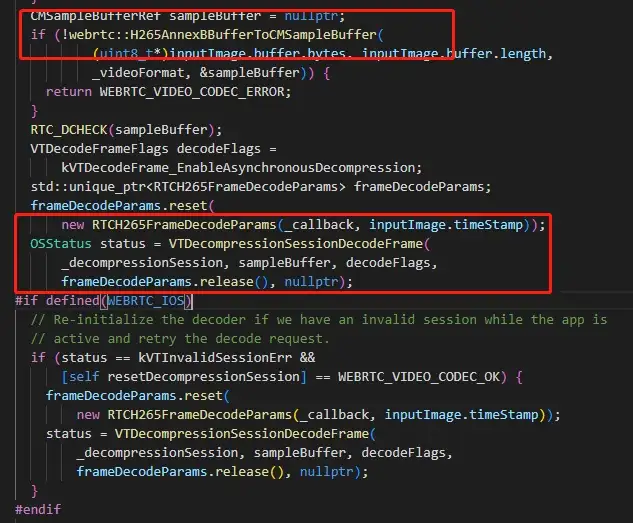 |
||||
|
||||
获取VPS,SPS,PPS相关数据,构建CMVideoFormatDescription相关数据; |
||||
|
||||
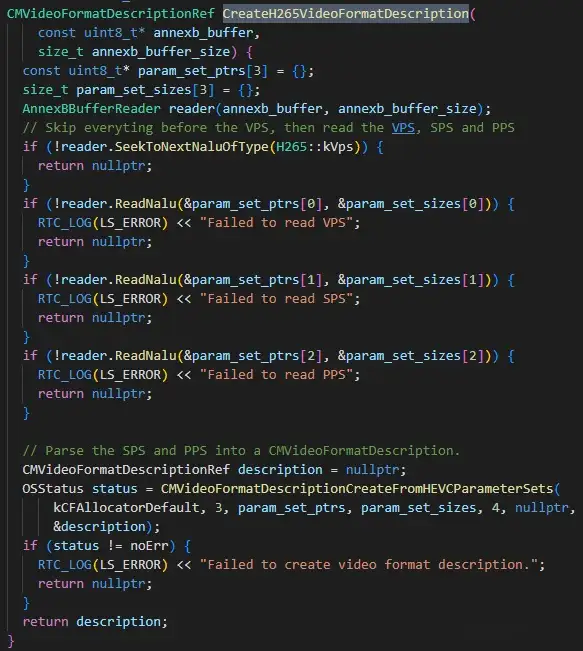 |
||||
|
||||
### 5.3callback |
||||
|
||||
callback函数用于接收H265解码数据,并用于送到显示端进行渲染的。 |
||||
|
||||
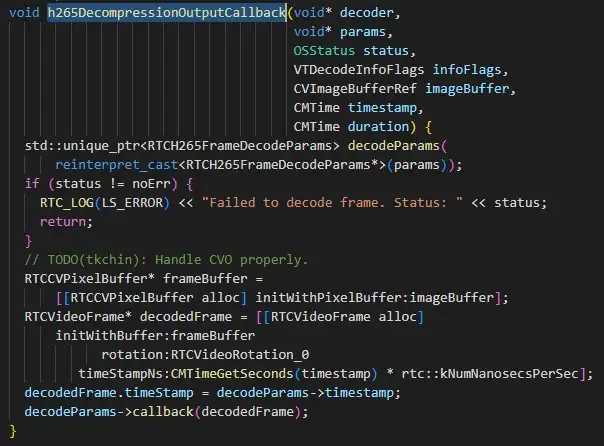 |
||||
|
||||
## 6.补充2 Annexb和AVCC格式转换 |
||||
|
||||
Android的硬解码接口MediaCodec只能接收Annex-B格式的H264数据,而iOS平台的VideoToolBox则相反,只支持AVCC格式。所以要进行一次转换,相关转换规则有大佬做了说明,可以参考 |
||||
|
||||
 |
||||
|
||||
## 7.补充3iOS编解码错误说明 |
||||
|
||||
在调试iOS编解码过程碰到几个CallBack的错误,于是找了一下相关错误代码,常见的错误如下所示: |
||||
|
||||
 |
||||
|
||||
其中一个错误kVTVideoDecoderBadDataErr = -12909,该错误找了很多久,也查了很多资料,一直卡住2天,每天早出晚归,熬最深的夜,加最晚的班,我可怜的头发又少了好几根。RIP. |
||||
|
||||
期间尝试各种办法验证确认: |
||||
|
||||
(1)将所有数据包和数据类型打印; |
||||
|
||||
(2)送解码前数据打印和保存; |
||||
|
||||
(3)反复确认VPS,SPS,PPS数据内容; |
||||
|
||||
(4)确认调用流程; |
||||
|
||||
(5)查找githubdemo。 |
||||
|
||||
最后确认经过多次反复确认代码,验证裸流,比较大小之后,最后发现计算长度时候H265 NAL头计算错误,导致IDR帧无法正确解码,最后找到问题,一行代码解决问题。其实该问题在RFC7798中有说明,只是自己还是按照H264惯性思维处理,这也是基础知识不扎实的根本原因(不过回想一下好像本来也没有这块知识,惭愧,惭愧)。 |
||||
|
||||
 |
||||
|
||||
题外话:排查问题过程很艰辛,最后一行代码处理完成,这是目前工作中很常见的,所以也是自己给新人,或者要入门音视频强调的一点:保持足够投入度,最好是兴趣驱动。《格局》一书中说:主动做事的收益,或许不会在一两天内显现出来但是长期坚持下来,主动做事的人,就能和其他人拉开距离。 |
||||
|
||||
扯远了,最后分享一下排查问题期间也查阅其他人调试过程发现的问题点,在此一起收集一下,方便后来者遇到问题可以快速查阅: |
||||
|
||||
(1)比如,省流模式下解码失败 |
||||
|
||||
该文章提到一种思路:可以借鉴比较成熟的ijkplayer,对比流程和处理细节,查找得到解决办法。 |
||||
|
||||
(2)比如,解码器Session失效问题 |
||||
|
||||
该文章中提到,如果VideoToolBox返回码是 kVTInvalidSessionErr =-12903,也就是说解码器Session异常或者失效了。可以在收到该返回码时调用ResetDecompressionSession操作完成重置,再进行切换时就会正常了。该部分优化已经同步了,防止切换异常;手动狗头,感谢大佬。 |
||||
|
||||
(3)比如,annexB与hvcc转换异常问题 |
||||
|
||||
该Issue中提到,ios硬解h265 NALU失败,看了代码发现在vtbformat_init中对265从annexB=>mp4转换时需要使用ff_isom_write_hvcc,而不能重用264的ff_isom_write_avcc。两者区别还是比较多的,有兴趣的翻阅一下FFMPEG代码自行补充。 |
||||
|
||||
原文https://zhuanlan.zhihu.com/p/589832516 |
||||
Loading…
Reference in new issue