|
|
|
@ -8,6 +8,11 @@ HTTP/2 协议 |
|
|
|
2. 连接 |
|
|
|
2. 连接 |
|
|
|
3. 帧 |
|
|
|
3. 帧 |
|
|
|
4. 流 |
|
|
|
4. 流 |
|
|
|
|
|
|
|
* 消息 |
|
|
|
|
|
|
|
* 流量控制 |
|
|
|
|
|
|
|
* 优先级 |
|
|
|
|
|
|
|
5. 服务器推送 |
|
|
|
|
|
|
|
6. 首部压缩 |
|
|
|
|
|
|
|
|
|
|
|
### HTTP/2 分层 |
|
|
|
### HTTP/2 分层 |
|
|
|
|
|
|
|
|
|
|
|
@ -95,5 +100,83 @@ HTTP/2 规范对流的定义是:HTTP/2 连接上独立的、双向的帧序列 |
|
|
|
> |
|
|
|
> |
|
|
|
> 需要注意的是,由于 HEADERS 和 CONTINUATION 帧必须是有序的,使用 CONTINUATION 帧会破坏或减损多路复用的益处。CONTINUATION 帧是解决重要场景(大首部)的工具,但只能在必要时使用。 |
|
|
|
> 需要注意的是,由于 HEADERS 和 CONTINUATION 帧必须是有序的,使用 CONTINUATION 帧会破坏或减损多路复用的益处。CONTINUATION 帧是解决重要场景(大首部)的工具,但只能在必要时使用。 |
|
|
|
|
|
|
|
|
|
|
|
### 消息 |
|
|
|
#### 消息 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
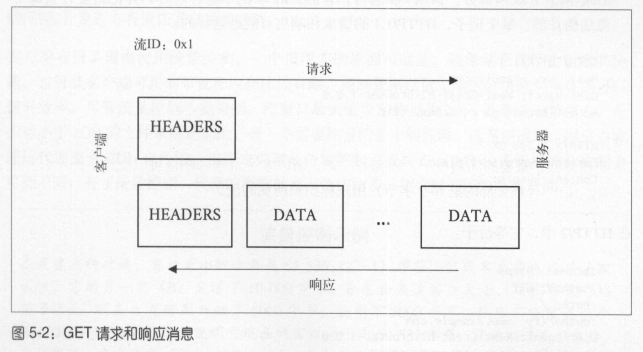
HTTP 消息泛指 HTTP 请求或响应。流是用来传输一对请求/响应消息的。一个消息至少由 HEADERS 帧组成,并且可以另外包含 CONTINUATION 和 DATA 帧,以及其他的 HEADERS 帧。以下是普通 GET 请求的示例流程: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
h1 的请求和响应都分为消息首部和消息体两部分;与之类似,h2 的请求和响应分为 HEADERS 帧和 DATA 帧。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
h1 把消息分为两部分:请求/状态行;首部。h2 取消了这种区分,并把这些行变成了魔法伪首部。举个例子,HTTP/1.1 的请求和响应可能是这样的: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
GET / HTTP/1.1 |
|
|
|
|
|
|
|
Host: www.example.com |
|
|
|
|
|
|
|
User-agent:Next-Great-h2-browser-1.0.0 |
|
|
|
|
|
|
|
Accept-Encoding:compress, gzip |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
HTTP/1.1 200 OK |
|
|
|
|
|
|
|
Content-type: text/plain |
|
|
|
|
|
|
|
Content-length: 2 |
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在 HTTP/2 中,它等价于: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
:scheme: https |
|
|
|
|
|
|
|
:method: GET |
|
|
|
|
|
|
|
:path: / |
|
|
|
|
|
|
|
:authority: www.example.com |
|
|
|
|
|
|
|
User-agent: Next-Great-h2-browser-1.0.0 |
|
|
|
|
|
|
|
Accept-Encoding: compress, gzip |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
:status: 200 |
|
|
|
|
|
|
|
content-type: text/plain |
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意,请求和状态行在这里拆分成了多个首部,即 :scheme、:method、:path 和 :status。同时需要注意,h2 的这种表示方式跟数据传输时不同。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 流量控制 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
h2 的新特性之一是基于流的流量控制。不同于 h1 的世界,只要客户端可以处理,服务端就会尽可能快的发送数据,h2 提供了客户端调整传输速度的能力。(并且,由于在 h2 中,一切几乎都是对称的,服务端也可以调整传输的速度。)WINDOW_UPDATE 帧用来指示流量控制信息。每个帧告诉对方,发送方想要接收多少字节。当一端接收并消费被发送的数据时,它将发出一个 WINDOW_UPDATE 帧以指示其更新后的处理字节的能力。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
客户端有很多理由使用流量控制。一个很现实的原因可能是,确保某个流不会阻塞其他流。也可能客户端可用的带宽和内存比较有限,强制数据以可处理的分块来加载反而可以提升效率。另外一个需要注意的是中间代理。通常情况下,网络内容通过代理或者 CDN 来传输,也许它们就是传输的起点或终点。由于代理两端的吞吐能力可能不同,有了流量控制,代理的两端就可以密切同步,把代理的压力讲到最低。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 优先级 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
流的最后一个重要特性是依赖关系。现代浏览器都经过了精心设计,首先请求网页上最重要的资源,以最优的顺序获取资源,由此来优化页面性能。拿到了 HTML 之后,在渲染页面之前,浏览器通常还需要 CSS 和关键 JavaSript 这样的东西。在没有多路复用的时候,在它可以发出对新对象的请求之前,需要等待前一个响应完成。有了 h2,客户端就可以一次发出所有资源的请求,服务端也可以立即着手处理这些请求。由此带来的问题是,浏览器失去了在 h1 时代默认的资源请求优先级策略。假设服务器同时接收到了 100 个请求,也没有标识哪个更重要,那么它将几乎同时发送每个资源,次要元素就会影响到关键元素的传输。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
h2 通过流的依赖关系来解决这个问题。通过 HEADERS 帧和 PRIORITY 帧,客户端可以明确的和服务端沟通它需要什么,以及它需要这些资源的顺序。这是通过声明依赖关系树和树里的相对权重实现的。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
* 依赖关系为客户端提供了一种能力,通过指明某些对象对另一些对象有依赖,告知服务器这些对象应该优先传输 |
|
|
|
|
|
|
|
* 权重让客户端告诉服务器如果确定具有共同依赖关系的对象的优先级 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 服务端推送 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
提升单个对象性能的最佳方式,就是在它被用到之前就放到浏览器的缓存里面。这正是 HTTP/2 的服务器推送的目的。推送使得服务器能够主动将对象发给客户端,这可能是因为它知道客户端不久将用到该对象。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果服务器决定要推送一个对象(RFC 中称为 “推送响应”),会构造一个 PUST_PROMISE 帧。这个帧有很多重要特性,列举如下: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1. PUSH_PROMISE 帧首部中的流 ID 用来响应相关联的请求。推送的响应一定会对应到客户端已发送的某个请求。如果浏览器请求一个主体 HTML 页面,如果要推送此页面使用的某个 JavaScript 对象,服务器将使用请求对应的流 ID 构造 PUSH_PROMISE 帧。 |
|
|
|
|
|
|
|
2. PUSH_PROMISE 帧的首部块与客户端请求推送对象时发送的首部块是相似的,所以客户端有办法放心检查将要发送的请求。 |
|
|
|
|
|
|
|
3. 被发送的对象必须是确保可缓存的。 |
|
|
|
|
|
|
|
4. :method 首部的值必须确保安全。安全的方法就是幂等的那些方法,这是一种不改变任何状态的好方法。例如,GET 请求被认为是幂等的,因为它通常只能获取对象,而 POST 请求被认为是非幂等的,因为它可能会改变服务器端的状态。 |
|
|
|
|
|
|
|
5. 理想情况下,PUST_PROMISE 帧应该更早发送,应当早于客户端接收到可能承载着推送对象的 DATA 帧。假设服务器要在发送 PUSH_PROMISE 之前发送完整的 HTML,那么客户端可能在接收到 PUSH_PROMISE 之前已经发出了对这个资源的请求。h2 足够健壮,可以优雅的解决这类问题,但还是会有些浪费。 |
|
|
|
|
|
|
|
6. PUSH_PROMISE 帧会指示将要发送的响应所使用的流 ID。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
> 客户端会从 1 开始设置流 ID,之后每新开启一个流,就会增加 2,之后一直使用奇数。服务器开启在 PUSH_PROMISE 中标明的流时,设置的流 ID 从 2 开始,之后一直使用偶数。这种设计避免了客户端和服务器之间的流 ID 冲突,也可以轻松的判断哪些对象是由服务器推送的。0 是保留数字,用户连接级控制消息,不能用于创建新的流。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果客户端对 PUSH_PROMISE 的任何元素不满意,就可以按照拒收原因重置这个流(使用 RST_STREAM),或者发送 PROTOCOL_ERROR(在 GOAWAY 帧中)。常见的情况是缓存中已经有了这个对象。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
根据应用的不同,选择推送哪些资源的逻辑可能非常简单,也可能异常复杂。拿一个简单的 HTML 页面来说,如果服务器接收到一个页面的请求,它需要决定是推送页面上的资源还是等客户端来请求。决策的过程需要考虑到如下方面: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
* 资源已经在浏览器缓存中的概率 |
|
|
|
|
|
|
|
* 从客户端看来,这些资源的优先级 |
|
|
|
|
|
|
|
* 可用的带宽,以及其他类似的会影响客户端接收推送的资源 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果服务器选择正确,那就真的有助于提升页面的整体性能,反之则会损耗页面性能。尽管 SPDY 很早就引入了这个特性,但如今通用的服务器推送解决方案非常少见,原因可能就在这里。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 首部压缩 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一开始我们就知道,首部压缩(HPACK)将会是 HTTP/2 的关键元素之一。HPACK 是种表查找压缩方案,它利用霍夫曼编码获得接近 GZIP 的压缩率。 |
{kind=link}