|
|
|
@ -17,6 +17,17 @@ |
|
|
|
5. 如何优化反射性能开销? |
|
|
|
5. 如何优化反射性能开销? |
|
|
|
6. 参考 |
|
|
|
6. 参考 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 前言 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
本文主要参考 [JVM 是如何实现反射的?](https://time.geekbang.org/column/article/12192),但是这篇文章需要购买才能阅读,有兴趣的可以支持一下原作者。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
但是笔者在测试的过程中发现两个问题: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1. 关闭 Inflation 机制并不会减少反射调用耗时 |
|
|
|
|
|
|
|
2. 增加类型 Profile 默认数量并不会减少反射调用耗时 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可能是我的测试方法有误,有理解的小伙伴可以拉我一把哇~ |
|
|
|
|
|
|
|
|
|
|
|
### 反射的定义以及基本使用 |
|
|
|
### 反射的定义以及基本使用 |
|
|
|
|
|
|
|
|
|
|
|
反射是 Java 语言中一个相当重要的特性,它允许正在运行的 Java 程序观测,甚至是修改程序的动态行为。表现为如下两点: |
|
|
|
反射是 Java 语言中一个相当重要的特性,它允许正在运行的 Java 程序观测,甚至是修改程序的动态行为。表现为如下两点: |
|
|
|
@ -470,13 +481,230 @@ java.lang.Exception: # 17 |
|
|
|
|
|
|
|
|
|
|
|
在默认情况下,方法的反射调用为委派实现,委派给本地实现来进行方法调用。再调用超过 15 次之后,委派实现便会将委派对象切换至动态实现。这个动态实现的字节码是自动生成的,它将直接使用 invoke 指令来调用目标方法。 |
|
|
|
在默认情况下,方法的反射调用为委派实现,委派给本地实现来进行方法调用。再调用超过 15 次之后,委派实现便会将委派对象切换至动态实现。这个动态实现的字节码是自动生成的,它将直接使用 invoke 指令来调用目标方法。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
反射调用的 Inflation 机制是可以通过参数(-Dsun.reflect.noInflation=true)来关闭的,这样一来,在反射调用一开始便会直接生成动态实现,而不会使用委派实现或者本地实现。 |
|
|
|
|
|
|
|
|
|
|
|
### 反射性能开销体现在哪? |
|
|
|
### 反射性能开销体现在哪? |
|
|
|
|
|
|
|
|
|
|
|
在刚才的例子中,我们先后进行了 Class.forName,Class.getMethod 以及 Method.invoke 三个操作。其中,Class.forName 会调用本地方法,Class.getMethod 则会遍历该类的公有方法。如果没有匹配到,它还将遍历父类的公有方法,可想而知,这两个操作都非常耗时。 |
|
|
|
在刚才的例子中,我们先后进行了 Class.forName,Class.getMethod 以及 Method.invoke 三个操作。其中,Class.forName 会调用本地方法,Class.getMethod 则会遍历该类的公有方法。如果没有匹配到,它还将遍历父类的公有方法,可想而知,这两个操作都非常耗时。 |
|
|
|
|
|
|
|
|
|
|
|
值得注意的是,以 getMethod 为代表的查找方法操作,会返回查找得到结果的一份拷贝。因此,我们应当避免在热点代码中使用返回 Method 数组的 getMethods 或者 getDeclaredMethods 方法,以减少不必要的堆空间消耗。 |
|
|
|
值得注意的是,以 getMethod 为代表的查找方法操作,会返回查找得到结果的一份拷贝。因此,我们应当避免在热点代码中使用返回 Method 数组的 getMethods 或者 getDeclaredMethods 方法,以减少不必要的堆空间消耗。 |
|
|
|
|
|
|
|
|
|
|
|
在实践中,我们往往会在应用程序中缓存 Class.forName 和 Class.getMethod 的结果,因此 |
|
|
|
在实践中,我们往往会在应用程序中缓存 Class.forName 和 Class.getMethod 的结果,因此,下面我们就只关注反射调用本身的性能开销。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```java |
|
|
|
|
|
|
|
public class ReflectDemo { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public void doSth(int i) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public static void main(String[] args) throws Exception { |
|
|
|
|
|
|
|
Class<?> clazz = ReflectDemo.class; |
|
|
|
|
|
|
|
Constructor constructor = clazz.getConstructor(); |
|
|
|
|
|
|
|
Object object = constructor.newInstance(); |
|
|
|
|
|
|
|
Method method = clazz.getMethod("doSth", int.class); |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ReflectDemo demo = new ReflectDemo(); |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
long current = System.currentTimeMillis(); |
|
|
|
|
|
|
|
for (int i = 1; i <= 2_000_000_000; i++) { |
|
|
|
|
|
|
|
if (i % 100_000_000 == 0) { |
|
|
|
|
|
|
|
long temp = System.currentTimeMillis(); |
|
|
|
|
|
|
|
System.out.println(temp - current); |
|
|
|
|
|
|
|
current = temp; |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
// 直接调用 |
|
|
|
|
|
|
|
demo.doSth(2333); |
|
|
|
|
|
|
|
// 反射调用 |
|
|
|
|
|
|
|
// method.invoke(object, 2333); |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
取最后五个记录的平均值,作为预热后的峰值性能,一亿次的直接调用耗时为 94ms(macOS + JDK11)然后把 94 作为基准值。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
改为反射调用,传入 2333 作为反射调用的参数,测得的结果约为基准值的 3.2 倍(301ms)。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
除了反射调用外,还额外做了两个操作: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
第一,由于 Method.invoke 是一个变长参数方法,在字节码层面它的最后一个参数会是 Object 数组。Java 编译器会在方法调用处生成一个长度为传入参数数量的 Object 数组,并将传入参数一一存储进该数组中。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
第二,由于 Object 数组不能存储基本类型,Java 编译器会对传入的基本数据类型进行自动装箱。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这两个操作除了带来性能开销外,还可能占用堆内存,使得 GC 更加频繁。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
使用 -Xlog:gc 参数,打印 GC 信息,可以看到在疯狂的 GC: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
// java -Xlog:gc ReflectDemo.java |
|
|
|
|
|
|
|
// ... |
|
|
|
|
|
|
|
[7.671s][info][gc] GC(108) Pause Young (Normal) (G1 Evacuation Pause) 301M->2M(499M) 1.087ms |
|
|
|
|
|
|
|
[7.736s][info][gc] GC(109) Pause Young (Normal) (G1 Evacuation Pause) 301M->2M(499M) 1.132ms |
|
|
|
|
|
|
|
[7.819s][info][gc] GC(110) Pause Young (Normal) (G1 Evacuation Pause) 301M->2M(499M) 1.219ms |
|
|
|
|
|
|
|
[7.891s][info][gc] GC(111) Pause Young (Normal) (G1 Evacuation Pause) 301M->2M(499M) 1.159ms |
|
|
|
|
|
|
|
[7.960s][info][gc] GC(112) Pause Young (Normal) (G1 Evacuation Pause) 301M->2M(499M) 1.172ms |
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
那么,如何消除这部分开销呢? |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关于第二个自动装箱,Java 缓存了 [-128, 127] 中所有整数所对应的 Integer 对象。当需要自动装箱的整数在这个范围之内时,便返回缓存的 Integer,否则需要新建一个 Integer 对象。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
因此,我们可以使用已经缓存的 Integer 对象或者扩大 Integer 对象。以这种方式测得的结果约为基准的 2.4 倍(222ms)。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
现在我们再来看看因变长参数生成的 Object 数组,既然每个反射调用对应的参数个数是固定的,那么我们可以选择在循环外新建一个 Object 数组,设置好参数并直接交给反射调用,代码如下: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```java |
|
|
|
|
|
|
|
public class ReflectDemo { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public void doSth(int i) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public static void main(String[] args) throws Exception { |
|
|
|
|
|
|
|
Class<?> clazz = ReflectDemo.class; |
|
|
|
|
|
|
|
Constructor constructor = clazz.getConstructor(); |
|
|
|
|
|
|
|
Object object = constructor.newInstance(); |
|
|
|
|
|
|
|
Method method = clazz.getMethod("doSth", int.class); |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
// 在循环外构造参数数组 |
|
|
|
|
|
|
|
Object[] arg = new Object[1]; |
|
|
|
|
|
|
|
arg[0] = 2333; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
long current = System.currentTimeMillis(); |
|
|
|
|
|
|
|
for (int i = 1; i <= 2_000_000_000; i++) { |
|
|
|
|
|
|
|
if (i % 100_000_000 == 0) { |
|
|
|
|
|
|
|
long temp = System.currentTimeMillis(); |
|
|
|
|
|
|
|
System.out.println(temp - current); |
|
|
|
|
|
|
|
current = temp; |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
// 反射调用 |
|
|
|
|
|
|
|
method.invoke(object, arg); |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
测试的结果反而更加糟糕了,为基准值的 3.5 倍(331ms)。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
再解决了自动装箱之后查看运行时的 GC 状况时,你会发现这段程序并不会触发 GC。其原因在于,原本的反射调用被内联了,从而使得即时编译器中的逃逸分析将原本新建的 Object 数组判断为不逃逸的对象。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果一个对象不逃逸,那么即时编译器可以选择栈分配甚至是虚拟分配,也就是不占用堆空间。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果在循环外新建数组,即时编译器无法确定这个数组会不会中途被更改,因此无法优化掉访问数组的操作,可谓是得不偿失。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
前面我们提到过,可以关闭反射调用的 Inflation 机制,从而取消委派实现,直接使用动态实现。此外,每次反射调用都会检查目标方法权限,而这个检查同样可以在 Java 代码里关闭,在关闭了这权限检查机制之后,代码如下: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```java |
|
|
|
|
|
|
|
public class ReflectDemo { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public void doSth(int i) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public static void main(String[] args) throws Exception { |
|
|
|
|
|
|
|
Class<?> clazz = ReflectDemo.class; |
|
|
|
|
|
|
|
Constructor constructor = clazz.getConstructor(); |
|
|
|
|
|
|
|
Object object = constructor.newInstance(); |
|
|
|
|
|
|
|
Method method = clazz.getMethod("doSth", int.class); |
|
|
|
|
|
|
|
method.setAccessible(true); // 关闭权限检查 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
long current = System.currentTimeMillis(); |
|
|
|
|
|
|
|
for (int i = 1; i <= 2_000_000_000; i++) { |
|
|
|
|
|
|
|
if (i % 100_000_000 == 0) { |
|
|
|
|
|
|
|
long temp = System.currentTimeMillis(); |
|
|
|
|
|
|
|
System.out.println(temp - current); |
|
|
|
|
|
|
|
current = temp; |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
// 反射调用 |
|
|
|
|
|
|
|
method.invoke(object, 23); |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
测得的结果约为基准值的 2.2 倍(204ms)。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
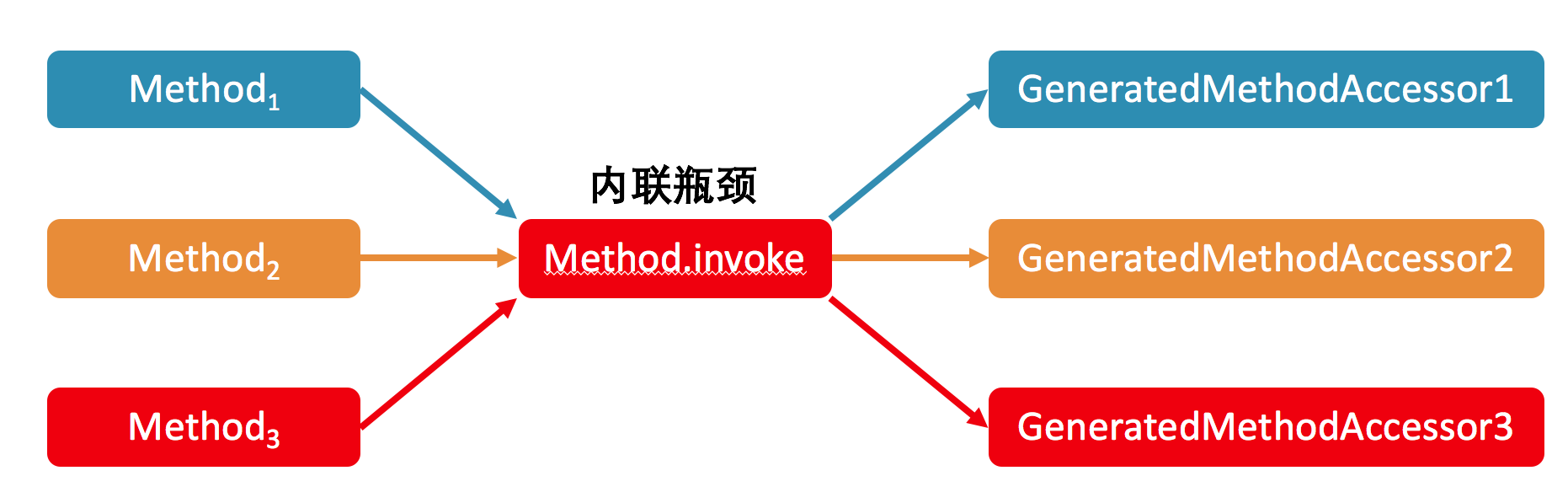
首先,在这个例子中,之所以反射调用能够变得那么快,主要是因为即时编译器中的方法内联。在关闭了 Inflation 的情况下,内联的瓶颈在于 Method.invoke 方法中对 MethodAccessor.invoke 方法的调用。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在生产环境中,我们往往拥有多个不同的反射调用,对应多个 GeneratedMethodAccessor,也就是动态实现。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
由于 Java 虚拟机的关于上述调用点的类型 profile(注:对于 invokevirtual 或者 invokeinterface,Java 虚拟机会记录调用者的具体类型,我们称之为类型 profile)无法同时记录这么多个类,因此可能造成所测试的反射调用没有被内联的情况。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```java |
|
|
|
|
|
|
|
public class ReflectDemo { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public void doSth(int i) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public static void main(String[] args) throws Exception { |
|
|
|
|
|
|
|
Class<?> clazz = ReflectDemo.class; |
|
|
|
|
|
|
|
Constructor constructor = clazz.getConstructor(); |
|
|
|
|
|
|
|
Object object = constructor.newInstance(); |
|
|
|
|
|
|
|
Method method = clazz.getMethod("doSth", int.class); |
|
|
|
|
|
|
|
method.setAccessible(true); // 关闭权限检查 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
polluteProfile(); |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
long current = System.currentTimeMillis(); |
|
|
|
|
|
|
|
for (int i = 1; i <= 2_000_000_000; i++) { |
|
|
|
|
|
|
|
if (i % 100_000_000 == 0) { |
|
|
|
|
|
|
|
long temp = System.currentTimeMillis(); |
|
|
|
|
|
|
|
System.out.println(temp - current); |
|
|
|
|
|
|
|
current = temp; |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
// 反射调用 |
|
|
|
|
|
|
|
method.invoke(object, 23); |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public static void polluteProfile() throws Exception { |
|
|
|
|
|
|
|
Class<?> clazz = ReflectDemo.class; |
|
|
|
|
|
|
|
Constructor constructor = clazz.getConstructor(); |
|
|
|
|
|
|
|
Object object = constructor.newInstance(); |
|
|
|
|
|
|
|
Method method1 = clazz.getMethod("target1", int.class); |
|
|
|
|
|
|
|
Method method2 = clazz.getMethod("target2", int.class); |
|
|
|
|
|
|
|
for (int i = 0; i < 2000; i++) { |
|
|
|
|
|
|
|
method1.invoke(object, 0); |
|
|
|
|
|
|
|
method2.invoke(object, 0); |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public void target1(int i) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public void target2(int i) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这时测试的结果为基准值的 7.2 倍(679ms)。也就是说,只要耽误了 Method.invoke 方法的类型 profile,性能开销便从 2.2 上升到 7.2 倍。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
之所以这么慢,除了没有方法内联之外,另一个原因是逃逸分析不再生效。这个时候便可以在循环外构造参数数组,并直接传递给反射调用,这样子测的结果为基准值的 5.8 倍(548ms)。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
除此之外,我们还可以提高 Java 虚拟机关于每个调用能够记录的类型数目(对应虚拟机参数 -XX:TypeProfileWidth,默认值为 2,这里设置为 8)。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 总结 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
影响反射调用耗时有以下原因: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1. 方法表查找 |
|
|
|
|
|
|
|
2. 构建 Object 数组以及可能存在的自动装拆箱操作 |
|
|
|
|
|
|
|
3. 运行时权限检查 |
|
|
|
|
|
|
|
4. 方法内联/逃逸分析 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 如何优化反射性能开销? |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1. 尽量避免反射调用虚方法 |
|
|
|
|
|
|
|
2. 关闭运行时权限检查 |
|
|
|
|
|
|
|
3. 可能需要增大基本数据类型对应的包装类缓存 |
|
|
|
|
|
|
|
4. 关闭 Inflation 机制 |
|
|
|
|
|
|
|
5. 提高 JVM 关于每个调用能够记录的类型数目 |
|
|
|
|
|
|
|
|
|
|
|
### 参考 |
|
|
|
### 参考 |
|
|
|
|
|
|
|
|
|
|
|
|
{kind=link}