7.8 KiB
目录
- 思维导图
- 概述
- 内部实现
- 确定索引
- put 方法实现
- 扩容机制
- 常见问题
- 参考
思维导图
概述
HashMap 底层数据结构是数组 + 链表 + 红黑树。数组的主要作用是方便快速查找,时间复杂度是 O(1),默认大小是 16,数组的下标索引是通过 key 的 hashcode 计算出来的,数组元素叫做 Node,当多个 key 的 hashcode 一致,但 key 值不相同时,单个 Node 就会转化为链表,链表的查询复杂度是 O(n),当链表的长度大于等于 8 并且数组的大小超过 64 时,链表就会转化为红黑树,红黑树的查询复杂度是 O(log(n)),简单来说,最坏的查询次数相当于红黑树的最大深度。
HashMap 非线程安全,如果需要满足线程安全,可以用 Collections.synchronizedMap 方法使得 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。
内部实现
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//默认桶容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//哈希桶数组
transient Node<K,V>[] table;
//HashMap 中实际存在的键值对数量
transient int size;
//记录 HashMap 内部结构发生变化的次数
transient int modCount;
}
在 HashMap 中,哈希桶数组的长度大小必须是 2 的 n 次方,这是一种非常规的设计,常规来说是把桶的大小设计为素数。相对来说,素数导致冲突的概率要小于非素数。HashTable 初始化桶的大小为 11,就是把桶大小设计为素数的应用。HashMap 采用这种非常规的设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap 定位哈希桶索引位置时,也加入了高位参与运算的过程。
这里存在一个问题,即使负载因子和 Hash 算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响 HashMap 的性能。于是,在 JDK 1.8 版本中,对数据结构作了进一步优化,当链表长度大于等于 8 并且数组长度大于等于 64 时,链表就转换为红黑树(二叉查找树),利用红黑树快速增删改差的特点提高 HashMap 的性能,从 O(n) 到 O(log n)。如果数组长度小于 64,则只会扩容不会树化。
为什么是 8 呢?这个答案在源码中注释又说到。大概意思就是,在链表数据不多的时候,使用链表进行遍历也比较快,只有当链表数据比较多时,才会转化成红黑树,但红黑树的占用空间是链表的 2 倍,考虑到转化时间和空间消耗,所以我们需要定义出转化的边界值。
在考虑设计 8 这个值的时候,我们参考了泊松分布概率函数,由泊松分布得出结论如下:
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
也就是说,当链表长度是 8 的时候,出现的概率是 0.000000006,不到千万分之一,所以说,正常情况下,链表的长度不可能到达 8,而一旦到达了 8,肯定是 hash 算法出了问题。
确定哈希桶数组索引位置
static final int hash(Object key) {
int h;
// >>>无符号右移十六位
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 通过 (n - 1) & hash 计算索引
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {}
//...
}
我们首先想到的就是通过 hash 对数组长度取模得到索引,这样元素的分布相对来说也是比较均匀的,但是模运算的消耗还是比较大的,而采用 (n - 1) & hash,当 n 为 2 的次方时,(n - 1) & hash 等价于取模运算,但是 & 比 % 具有更高的效率。
同时,取 hash 的时候通过 hashCode() 的高十六位和低十六位异或得到,这样做在数组长度比较小的时候也能保证高地位 bit 都能参与到 hash 的计算中,同时不会有太大开销。

put 方法的实现
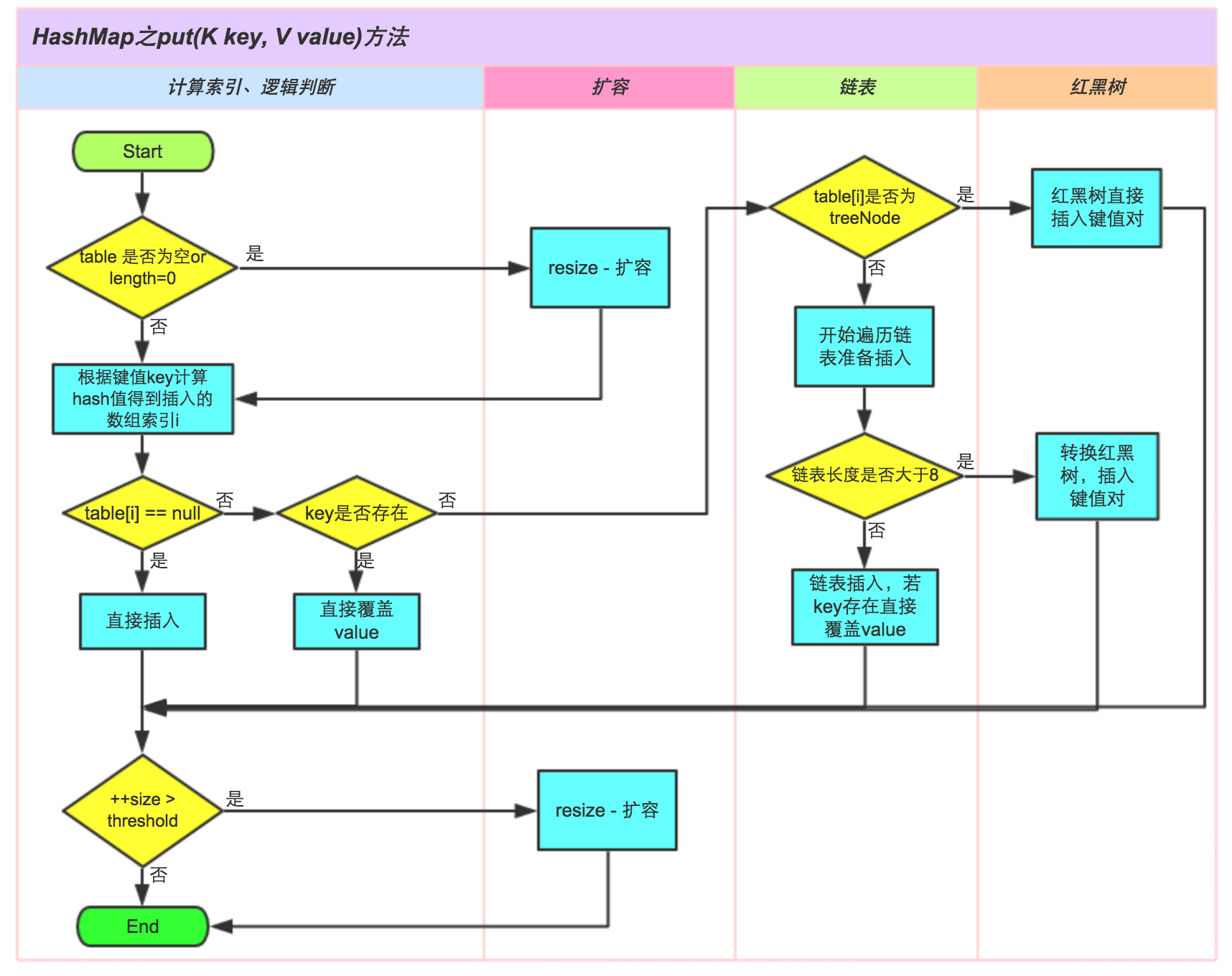
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//1.tab 为空,则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//2.计算下标
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//3.如果存在节点 key,直接覆盖 value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//4.如果是红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//5.链表插入
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度大于八转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//6.如果超过最大容量,则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
扩容机制
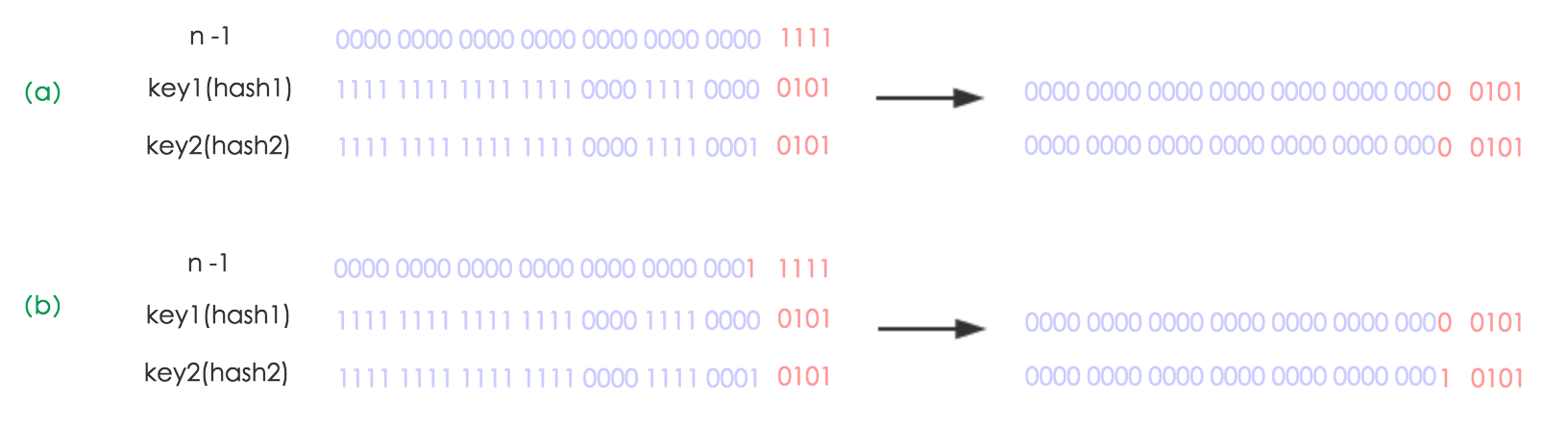
扩容的时候容量翻倍,也就是 x2,这也同时保证了长度依旧是 2 的次方,所以前面基于 (n - 1) & hash 取索引的优化得以保留。既然数组长度改变了,那么肯定的重新计算索引位置呀?这里又有一个优化点,当 n 为 2 次方时,x2 只不过是在高位补个 1,然后在进行与运算时,hash 的低位保持不变,高位是 1 得 1,是 0 得 0,也就是说 hash 高位为 1,索引就变成了原索引再加上旧桶值;高位为 0,索引就和原索引一致。这也就避免重新 (n - 1) & hash 操作获取索引,只需要看 hash 的高位是 1 还是 0 即可。
看当 n = 16 时,hash = 5 的时候,示意图:
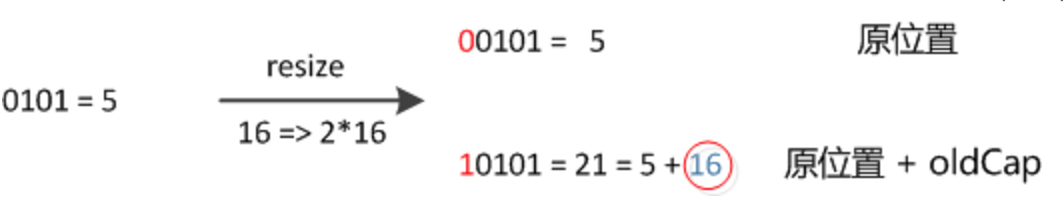
所以,可以把 HashMap 的优化都归功于桶长度为 2 的次方。