11 KiB
目录
- 前言
- 思维导图
- 源码解析
- 类继承关系
- 类成员变量
- 类成员方法
- 相关静态方法
- StringBuilder 和 StringBuffer
- 对象内存分配
- 常见面试题
- 参考
前言
对于 String,大家可能再常见不过了。我们知道,String 是一个不可变类,也由于它的不可变性,所以在类似拼接、裁剪字符串时,都会产生新的 String 对象。字符串操作不当就可能产生大量临时字符串,这也就引入了 StringBuilder 和 StringBuffer,它们之间的区别就在于是否线程安全。当然,你可能也知道 new String("Omooo") 和 String name = "Omooo" 的区别。
那么你是否知道 JDK9 之后对 String 实现的变化呢?StringBuilder 和 StringBuffer 除了线程安全还有哪些知识点呢?以及对 String 的编译器优化、+ 重载符的底层实现、intern() 方法的版本区别?
思维导图
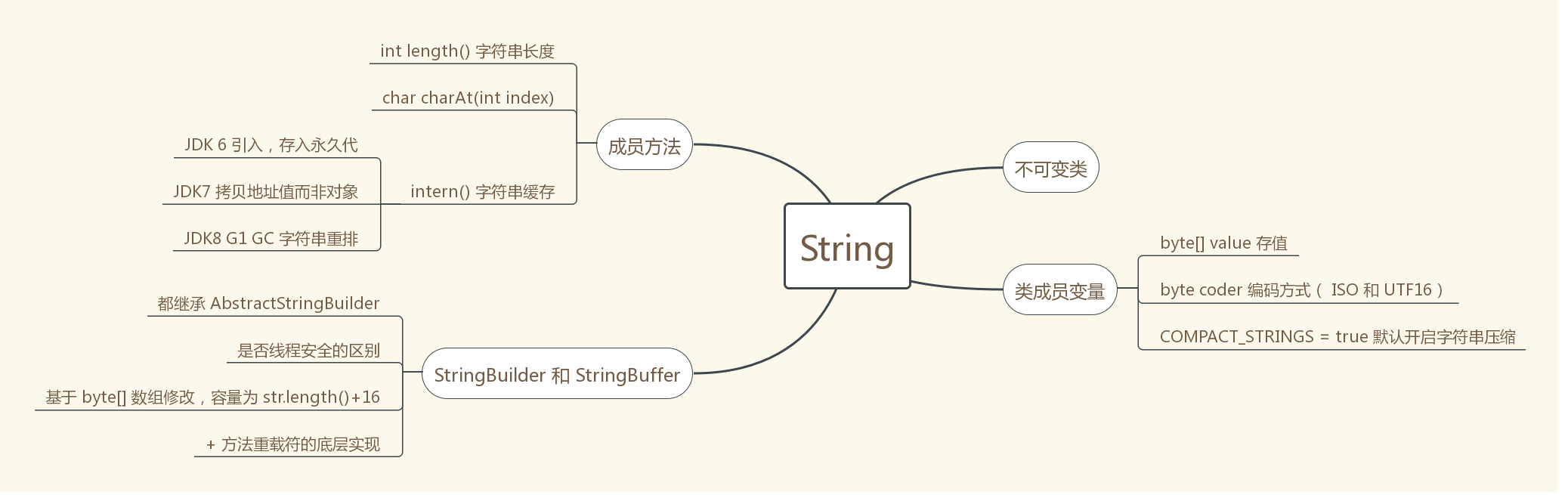
源码解析
类继承关系
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
}
String 类由 final 修饰,是一个不可变类。
类成员变量
// JDK 10
private final byte[] value;
private final byte coder; //采取的编码方式
static final boolean COMPACT_STRINGS;
static {
COMPACT_STRINGS = true; //压缩 String 存储空间
}
@Native static final byte LATIN1 = 0;
@Native static final byte UTF16 = 1;
在 JDK 9 之前,用的是 char 数组来存储 String 的值,之后就用 byte 数组来存储,一个 char 是两个 byte,在存储单个字符时以及拉丁语系的字符时,根本就不需要太宽的 char,所以在之后用了划分粒度更细的 byte 来存储,这也就带来了更小的内存占用和更快的操作速度。
String 支持多种编码,但是如果不指定编码的话,它可能使用两种编码方式,分别是 LATIN1 和 UTF16,LATIN1 其实就是 ISO 编码,属于单字节编码,而 UTF16 为双字节编码。
String 在表示因为字符或者数字时,会可能存在浪费空间的情况,比如在存储 what 字符串时:
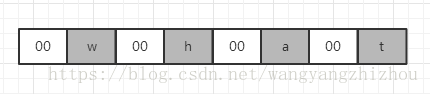
在 java 9 之后就变成了:
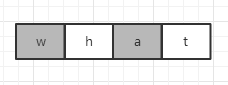
可以看到,压缩之后存储更加紧凑了。默认是开启压缩的,即 COMPACT_STRINGS 默认为 true。
类成员方法
//计算长度
public int length() {
return value.length >> coder();
}
byte coder() {
return COMPACT_STRINGS ? coder : UTF16;
}
//获取指定位置的字符
public char charAt(int index) {
if (isLatin1()) {
return StringLatin1.charAt(value, index);
} else {
return StringUTF16.charAt(value, index);
}
}
//...
既然改变了编码方式,计算长度就需要考虑编码方式了,如果是 UTF16,双字节编码,那就是右移一位即长度为之前的 1/2。同时,也能看出来,默认采用的是单字节编码即 ISO 编码(COMPACT_STRINGS 默认为 true)。
剩下就是 String#intern() 方法:
public native String intern();
intern() 是在 Java6 引入的,目的是提示 JVM 把相应字符串放在常量池缓存起来。在我们创建字符串对象并调用 intern() 方法的时候,如果已经有了缓存的字符串,就会返回缓存里面的实例,否则就将其缓存起来。
在使用 Java6 中并不推荐大量使用 intern() 方法,这是因为被缓存的字符串是存在所谓的 PermGen 里的,也就是永久代,这个空间是有限的,也基本不会被除了 FullGC 之外的垃圾收集照顾到,所以,如果使用不当,OOM 就会光顾。在后续版本中,这个缓存被放置在堆上,这样就极大避免了永久代被占满的问题,甚至永久代在 JDK8 中被 MetaSpace(元数据区)替代了。而且,默认缓存大小也在不断的扩大中。
还有就是在 Java7 中,intern 方法做了些改变,进行拷贝的时候不是拷贝对象,而是拷贝地址值。这里强烈推荐 String类相关面试题很难?不要方,问题不大 这一篇文章。
Intern 是一种显式的重排机制,但是它也有一定的副作用,那就是需要手动调用。我想基本上很少有人用到这个方法,因为我们很难预计字符串的重复情况,反而是一种看视一种冗余的操作。好在,在 JDK8 中,推出了一种新特性,那就是 G1 GC 下的字符串重排,它是通过将相同数据的字符串指向同一份数据来做到的,是 JVM 底层的改变,并不需要 Java 类库做什么修改。
StringBuilder 和 StringBuffer
StringBuffer 是 StringBuilder 的线程安全版本,二者都继承了 AbstractStringBuilder,StringBuffer 在修改字符串操作 (append、replace、substring 等)的时候都加了 synchronized,这里就以 StringBuilder 来分析。
StringBuilder sb = new StringBuilder("Om");
String name = sb.append("o").append("o").append("o").toString();
首先需要明确的就是 StringBuilder 和 StringBuffer 针对字符串的修改都是通过 byte[] 数组的。
既然是通过内部数组来实现的,那么内部数组应该创建多大呢?
public StringBuilder(String str) {
//1.创建一个初始容量+16 的 byte[] 数组
super(str.length() + 16);
//2.把原 byte[] 数组的值拷贝到新数组
append(str);
}
//super(str.length() + 16)调用的 AbstractStringBuilder 的构造方法
AbstractStringBuilder(int capacity) {
if (COMPACT_STRINGS) {
value = new byte[capacity];
coder = LATIN1;
} else {
value = StringUTF16.newBytesFor(capacity);
coder = UTF16;
}
}
所以,当如果已知可能拼接的字符串长度过时,可以这样指定:
StringBuilder sb = new StringBuilder(30);
这就避免了拼接了长度大于十六之后导致数组拷贝的开销,在循环中拼接字符串要特别注意。
还有一种情况,那就是在 for 循环中使用 + 拼接字符串,这也是要极力避免的,因为 + 重载符底层也是通过 StringBuilder 来实现的,实际上这句话也不太准确,因为存在编译器优化的情况。
public class StringTest {
public static void main(String[] args) {
String s = "Name: " + "Omooo";
System.out.println(s);
System.out.println(add("Omooo"));
}
private static String add(String name) {
return "Name: " + name;
}
}
由于字符串的不可变性,所以在编译阶段就能确定 s 的值,所以也就不需要 StringBuilder。对于 add 方法,我们直接看编译后的字节码即可(IDEA -> View -> Show Bytecode):
L0
LINENUMBER 11 L0
NEW java/lang/StringBuilder
DUP
INVOKESPECIAL java/lang/StringBuilder.<init> ()V
LDC "Name: "
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ALOAD 0
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
ARETURN
L1
LOCALVARIABLE name Ljava/lang/String; L0 L1 0
MAXSTACK = 2
MAXLOCALS = 1
可以明显的看出是通过 StringBuilder 来实现的,以上是在 JDK8 环境,对于 JDK8 之后则是:
private static add(Ljava/lang/String;)Ljava/lang/String;
L0
LINENUMBER 12 L0
ALOAD 0
INVOKEDYNAMIC makeConcatWithConstants(Ljava/lang/String;)Ljava/lang/String; [
// handle kind 0x6 : INVOKESTATIC
java/lang/invoke/StringConcatFactory.makeConcatWithConstants(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;
// arguments:
"Name: \u0001"
]
ARETURN
L1
LOCALVARIABLE name Ljava/lang/String; L0 L1 0
MAXSTACK = 1
MAXLOCALS = 1
可以看到是通过 StringConcatFactory.makeConcatWithConstants ,查看源码其实内部也是通过 StringBuilder 来实现的。
对象内存分配
关于内存分配这一块,再次推荐一遍 String类相关面试题很难?不要方,问题不大 这一篇文章。
String 对象创建有两种方式:
-
字面量赋值
String str = "Omooo"这样创建字符串对象,首先会去常量池中找有没有这个字符串,如果有就直接指向,没有就先往常量池中添加再指向。
-
new 创建
String str = new String("Omooo");当然,我们肯定不会这样写。如果这样写了,它会做两件事。
首先在堆上创建该字符串对象,然后去看常量池中是否有该字符串,如果有就算了,没有就往常量池中添加一个。
String 对象的内存分配讲完了,那就看这一道题:
String str1 = new String("str")+new String("01");
str1.intern();
String str2 = "str01";
System.out.println(str2==str1);
输出 true。
在 JDK 1.7 之后,intern 方法做了些改变,进行拷贝的时候不是拷贝对象,而是拷贝地址值。
那么在想想一下两个呢?
String str1 = new String("str")+new String("01");
String str2 = "str01";
str1.intern();
System.out.println(str2==str1);
String str1 = new String("str")+new String("01");
String str2 = "str01";
str1 = str1.intern();
System.out.println(str2==str1);
常见面试题
- String、StringBuilder、StingBuffer 的区别?
- String name = "Omooo" 和 String name = new String("Omoo") 、String name = new String("Omoo") + "o" 的区别以及分别创建了多少个对象?
更新
String 不可变性的理解?
往往一般的回答里只会说道 String 被 final 修饰就完事了。其实有两点:
- String 被 final 修饰,说明 String 类绝不可能被继承了,也就是说任何对 String 的操作方法,都不会被继承覆写
- String 中保存数据的是一个 char 的数组 value,value 也是被 final 修饰的,也就是说 value 一旦被赋值,内存地址是绝对无法被修改的,而且 value 的权限是 private 的,外部绝对访问不到,String 也没有开放出可以对 value 进行赋值的方法,所以说 value 一旦产生,内存地址就根本无法被修改
因为 String 具有不变性,所以 String 的大多数操作方法,就会返回新的 String,如下面这种写法是不对的:
String str = "2333";
// 无法替换,要改成: str = str.replace("2", "3");
str.replace("2", "3")