You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
283 lines
18 KiB
283 lines
18 KiB
# iOS音视频:OpenGL常用术语介绍
|
|
|
|
## 1、前言
|
|
|
|
【**iOS音视频**】是个系列,里面会记录一些博主在`iOS音视频`方面的学习笔记、踩到的坑,以便温故而知新。
|
|
|
|
> 此系列文章包括但不限于:
|
|
>
|
|
> 1. [iOS音视频:OpenGL常用术语介绍](https://juejin.cn/post/6940900616881307679)
|
|
> 2. ...
|
|
|
|
本文是这个系列的第1篇文章,主要目的是帮助大家快速了解`OpenGL`,下面进入正文。
|
|
|
|
## 2、OpenGL简介
|
|
|
|
### 2.1 OpenGL是什么
|
|
|
|
`OpenGL`(Open Graphics Library,译为 `开放图形库` 或 `开放式图形库`):是用于 **渲染** 2D、3D矢量图形的跨语言、跨平台的应用程序编程接口库。
|
|
|
|
它是一种`图形API库`,它把计算机的资源抽象成一个个`OpenGL对象`,对这些资源的操作抽象成一个个`OpenGL指令`。由于它只提供渲染功能(操作的是`GPU芯片`),与窗口系统、音频、打印、键盘/鼠标或其他输入设备无关,所以具备跨平台性(主要运行在PC端,如Mac OS、Linux、Windows等)。
|
|
|
|
与OpenGL类似的图形API库还有`OpenGL ES`、`Metal`、`DirectX`等,它们之间的主要区别是:
|
|
|
|
- `OpenGL ES`(OpenGL for Embedded Systems):是`OpenGL`的子集,针对手机、PDA和游戏主机等嵌入式设备而设计,去除了许多不必要的、性能较低的API。
|
|
- `Metal`:是苹果公司推出的平台技术,主要运行于苹果各大平台上(macOS、iOS、tvOS)。该技术专为多线程而设计,并提供各种出色工具将所有素材整合在XCode中。经过优化,`Metal`使`CPU`和`GPU`能够协同工作来实现最优性能(它能够为3D图像提高10倍的渲染性能)。
|
|
- `DirectX`:是微软公司创建的多媒体编程接口,由很多API组成(不仅仅是图形API),仅限于Windows平台上使用(目前不支持Windows以外的平台)。按照性质可分为四大部分,分别是显示部分、声音部分、输⼊部分和网络部分。
|
|
|
|
> 由于博主主要从事iOS开发,所以`DirectX`在此系列文章中将不做赘述。
|
|
|
|
### 2.2 OpenGL解决什么问题
|
|
|
|
作为图形API库,`OpenGL`、`OpenGL ES`、`Metal`在任何项目中解决问题的本质就是利用`GPU芯片`来高效渲染图形图像。使用这些图形API库也是iOS开发者唯一接近GPU的方式。
|
|
|
|
因此,图形API库常常被用在下述场景中:
|
|
|
|
- 游戏开发中,对游戏场景的渲染
|
|
- 音视频开发中,对视频解码后的数据渲染,给视频加滤镜处理等
|
|
- 地图开发中,对地图数据的渲染
|
|
- 动画中,实现动画的绘制
|
|
- 航空航天、医疗行业等等
|
|
|
|
### 2.3 关于选择的问题
|
|
|
|
苹果于`WWDC 2014`上提出`Metal`,但直到`WWDC 2018`年,苹果才完成系统内部从`OpenGL ES`到`Metal`的过渡,同时宣布在苹果设备上(`macOS Mojave`、`iOS 12`、`tvOS 12`)弃用`OpenGL/OpenGL ES/OpenCL`。从事图形API工作的开发者需要从自身角度考虑由哪个入门,可以从下面几方面综合考虑:
|
|
|
|
- `OpenGL/OpenGL ES`具备跨平台性,而`Metal`仅限于苹果平台。
|
|
- 苹果自己的系统从`OpenGL/OpenGL ES`迁移到`Metal`花费了大量时间(4年左右),针对的是苹果内部系统底层API依赖,`OpenGL/OpenGL ES`由此变成了第三方图形API库。
|
|
- 目前大多数`OpenGL/OpenGL ES`项目组很庞大(如百度地图、高德地图、大部分音视频项目组),未完成往`Metal`的迁移工作。此时仅仅会`Metal`是不够的。
|
|
|
|
**所谓艺多不压身,沿着 `OpenGL` -> `OpenGL ES` -> `Metal` 的路线全部掌握也不失为一种选择。**
|
|
|
|
## 3、 OpenGL常用术语介绍
|
|
|
|
### 3.1 OpenGL状态机
|
|
|
|
状态机是理论上的一种机器,它描述了一个对象在其生命周期内所经历的各种状态,状态间的转变,发生转变的原因、条件及转变中所执行的活动。或者说,状态机是一种行为,说明对象在其生命周期中响应事件所经历的状态序列以及对那些状态事件的响应。因此具有以下特点:
|
|
|
|
- 有记忆功能,能记住其当前的状态;
|
|
- 可以接收输⼊,根据输⼊的内容和⾃己的原先状态,修改⾃己当前状态,并且可以有对应输出;
|
|
- 当进⼊某个特殊状态如停机状态的时候,将不再接收输⼊,停⽌⼯作。
|
|
|
|
`OpenGL`本身就是一个庞大的状态机,它同样:
|
|
|
|
- 可以记录自己的状态(如当前使用的颜色,是否开启了混合功能等);
|
|
- `OpenGL`可以接收输入(当调用`OpenGL`函数的时候,实际上可以看成`OpenGL`在接收我们的输入),根据输入的内容和自己的状态,修改自己的状态,并且可以得到输出(比如我们调用`glColor3f`,则`OpenGL`接收到这个输入后会修改自己的当前颜色这个状态;我们调用`glRectf`,则`OpenGL`会输出一个矩形);
|
|
- `OpenGL`可以进入停止状态,不再接收输入。在程序退出前,`OpenGL`总会先停止工作的。
|
|
|
|
> 需要注意的是,它每一次状态改变都是全局的,因此在完成某状态下的功能后,需要把状态关闭/切换回去。
|
|
|
|
如可以使用`glColor函数`来选择一种颜色,以后绘制的所有物体都是这种颜色,除非再次使用`glColor函数`重新设定;同理,可以使用`glTexCoord函数`来设置一个纹理坐标,以后绘制的所有物体都是采用这种纹理坐标,除非再次使用`glTexCoord函数`重新设置。
|
|
|
|
总的来说,**`OpenGL`是一个状态机,它保持自身的状态,除非用户输入一条指令让它改变状态。**
|
|
|
|
例如:
|
|
|
|
```c
|
|
// 获取是否深度测试/混合
|
|
glIsEnabled(GL_DEPTH_TEST);
|
|
glIsEnabled(GL_BLEND);
|
|
|
|
// 开启/关闭深度测试
|
|
glEnable(GL_DEPTH_TEST);
|
|
glDisable(GL_DEPTH_TEST);
|
|
|
|
// 开启/关闭混合
|
|
glEnable(GL_BLEND);
|
|
glDisable(GL_BLEND);
|
|
复制代码
|
|
```
|
|
|
|
### 3.2 OpenGL上下文
|
|
|
|
`OpenGL`是面向过程的,它在渲染的时候需要一个`Context`来记录渲染需要的所有信息和状态,也就是`OpenGL上下文`。应用程序在调用任何OpenGL的指令之前,都需要首先创建一个`OpenGL上下文`。
|
|
|
|
- `OpenGL上下文`和`OpenGL状态机`的联系是紧密的,可以认为`OpenGL上下文`就是一组`OpenGL状态机`。
|
|
- `OpenGL`采用了`Client-Server`模式,`GPU`相当于一台服务器,可对应多个客户端即上下文,而一个客户端维护着一组状态机。大部分`OpenGL指令`都是异步的,不是立即执行,只是上下文向服务器发送了一些命令(当然也有一些API可实现同步功能)。
|
|
- `OpenGL上下文`是一个线程私有(thread-local)的变量,也就是说如果我们在线程中绘制,那么需要分别为每个线程指定一个上下文的,而且多个线程不能同时指定同一个上下文。
|
|
- 由于`OpenGL上下文`是一组庞大的`OpenGL状态机`,切换上下文往往会产生较大的开销,但是不同的绘制模块,可能需要使用完全独立的状态管理。因此,可以在应用程序中分别创建多个不同的上下文,在不同线程中使用不同的上下文,上下文之间共享纹理、缓冲区等资源。这样的方案,会比反复切换上下文,或者大量修改渲染状态更加合理高效。
|
|
|
|
### 3.3 图元
|
|
|
|
`图元`(Primitive),是基本图形元素的简称,在`OpenGL/OpenGL ES`中,任何图像都是由图元组成。
|
|
|
|
- `OpenGL`的图元:点、线段、三角形、四边形、多边形
|
|
- `OpenGL ES`的图元:点、线段、三角形
|
|
|
|
### 3.4 顶点数组和顶点缓冲区
|
|
|
|
在绘制图像时,图像的顶点位置数据就是`顶点数据`。
|
|
|
|
在调⽤`OpenGL`绘制方法时,
|
|
|
|
- 如果顶点数据是由内存传⼊的,即通常是以数组的形式把顶点数据存储在一块内存中,这个数组被称为`顶点数组`(Vertex Array);
|
|
- 性能更高的做法是,提前分配⼀块显存,将顶点数据预先存入到显存当中,这部分的显存,就被称为`顶点缓冲区`(Vertex Buffer)。
|
|
|
|
### 3.5 渲染(Rendering)
|
|
|
|
在`OpenGL`中,任何事物都是处于3D空间的,而屏幕/窗口显示的是2D。将原始图形/图像数据转换成3D空间图像,并最终显示在2D屏幕/窗口,这个操作就是`渲染`(Rendering)。
|
|
|
|
渲染主要有两大流程,分别是:
|
|
|
|
- `顶点渲染`:把顶点数据通过变换、过滤、插值等系列操作形成最终形状的过程。
|
|
- `像素渲染`:在形状中填充色彩。在这个过程中,被填充的色彩可以来自于顶点颜色、纹理甚至是通过某些数值计算出来的色彩(如光照)。
|
|
|
|
### 3.6 管线
|
|
|
|
`图形渲染管线`(Graphics Pipeline),简称`管线`,描述的是渲染图形的过程。渲染图形并非是一蹴而就的,它的整个过程又会经历一个个阶段,类似于工厂的流水线作业。
|
|
|
|
管线是个抽象的概念,之所以称之为管线是因为显卡在处理数据的时候是按照一个固定的顺序来的,⽽且严格按照这个顺序(就像⽔从一根管⼦的⼀端流到另⼀端,这个顺序是不能打破的)。
|
|
|
|
管线可以分为几个阶段,每个阶段将会把前一个阶段的输出作为输入。所有这些阶段都是高度专门化的(它们都有一个特定的函数),并且很容易并行执行。
|
|
|
|
管线可分为 `固定管线` 和 `可编程管线`:
|
|
|
|
- `固定管线`是固化的一个渲染流程,只需要开发者在`CPU`端输入渲染所需要的参数/数据,并指定特定的开关,调用函数就能完成渲染操作。它不需要也不允许开发者去自定义渲染的具体逻辑。
|
|
- `可编程管线`是必须由开发者实现渲染逻辑,否则无法渲染出最终的图像。开发者可以根据自己的具体需要来编写顶点渲染和像素渲染的具体逻辑,可最大程度的简化渲染管线的逻辑以提高渲染效率,也可自己实现特定的算法和逻辑来渲染出固定管线无法渲染的效果。具有很高的可定制性,但同时也对开发者提出了更高的要求。
|
|
|
|
### 3.7 着色器
|
|
|
|
`着色器`(Shader)是运行在`GPU`上的程序,用于实现实现渲染的,这些小程序为管线的某个特定部分而运行(把输入转化为输出)。`OpenGL`在实际调⽤绘制函数之前,还需要指定⼀个着⾊器程序。
|
|
|
|
- 着色器只是一种把输入转化为输出的程序,且是一种非常独立的程序,因为它们之间不能相互通信,它们之间唯一的沟通只有通过输入和输出。
|
|
- 常见的着色器主要有`顶点着色器`、`片元着色器`这两种,当然也有一些其他着色器(如`几何着色器`、`曲面细分着色器`等),只是没前两种常用(直至`OpenGL ES 3.0`,可编程的着色器也只有`顶点着色器`和`片元着色器`这两种)。
|
|
|
|
#### 3.7.1 顶点着色器
|
|
|
|
`顶点着色器`(Vertex Shader)是用来操作顶点数据的(旋转、平移、投影等)。顶点着色器是逐顶点运算的程序,也就是说**每个顶点数据都会执行⼀次顶点着⾊器,当然这是并行的,并且顶点着⾊器运算过程中⽆法访问其他顶点的数据**。
|
|
|
|
#### 3.7.2 片元着色器
|
|
|
|
`片元着色器`(Fragment Shader)是用于计算每个像素填充颜色的程序。它是逐像素运算的程序,即**每个像素都会执行一次片元着色器,当然这也是并行的、独立的。**
|
|
|
|
思考:为什么`OpenGL`使用`GPU`而不是`CPU`?
|
|
|
|
> 有的书籍把`片元着色器`叫做`像素着色器`(Pixel Shader),或者`片段着色器`,开发者只需要知道这3者是同一个东西即可(只是叫法不同,另外,`片元着色器`在`Metal`里叫做`片元函数`)。
|
|
|
|
#### 3.7.3 GLSL
|
|
|
|
`GLSL(OpenGL Shading Language)`是编写着色器的语言,这是一种类C的语言。`GLSL`是为图形计算量身定制的,它包含一些针对向量和矩阵操作的有用特性。
|
|
|
|
#### 3.7.4 着色器的渲染流程
|
|
|
|
着色器也是会经过编译、链接等步骤,并最终生成`着色器程序`(glProgram)的,它必定同时包含`顶点着色器`和`片元着色器`的运算逻辑,其他着色器则是可选的(如细分着色器)。
|
|
|
|
简单介绍一下着色器的渲染流程,大致如下图所示:
|
|
|
|
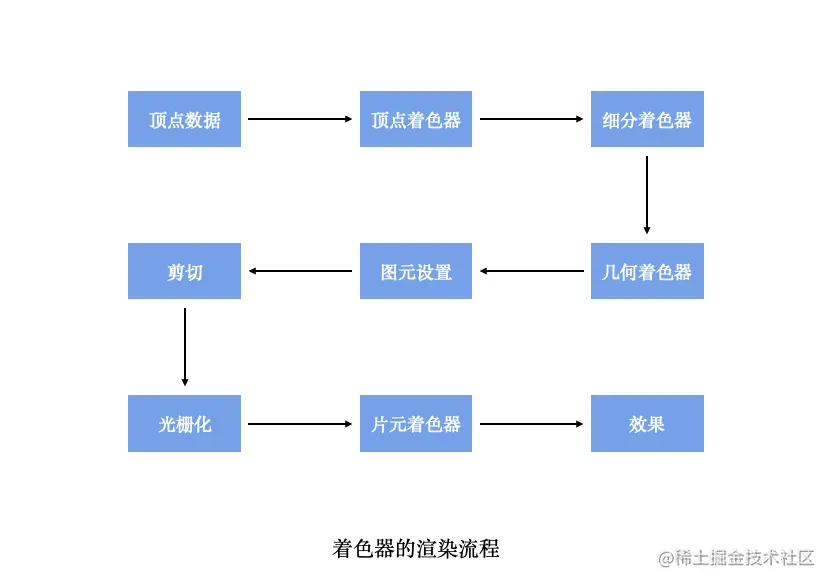
|
|
|
|
说明:
|
|
|
|
1. 在`OpenGL`进行渲染的时候,首先由顶点着色器对顶点数据进行运算,再经过图元装配,将顶点转化为图元
|
|
2. 接着就是光栅化处理,图元数据由此转换为栅格化数据
|
|
3. 最后,栅格化数据经由片元着色器运算(逐像素,并决定像素的填充色),渲染成型。
|
|
|
|
> 注意:这里只是个大致的流程(以着色器的视角)。
|
|
|
|
### 3.8 光栅化
|
|
|
|
`光栅化`(Rasterization)是把顶点数据转换为片元的过程,具有将图转化为一个个栅格组成的图象的作用,特点是每个元素对应帧缓冲区中的一像素。
|
|
|
|
- 光栅化其实是一种将
|
|
|
|
```
|
|
几何图元
|
|
```
|
|
|
|
变为
|
|
|
|
```
|
|
二维图像
|
|
```
|
|
|
|
的过程。该过程包含了两部分的工作,光栅化过程产生的是
|
|
|
|
```
|
|
片元
|
|
```
|
|
|
|
- 第一部分工作:决定窗口坐标中的哪些整型栅格区域被基本图元占用;
|
|
- 第二部分工作:分配一个颜色值和一个深度值到各个区域。
|
|
|
|
- 光栅化接收的输入是`几何图元`,其输出的是`像素`(参考着色器渲染流程),所以也可以通俗地理解成`像素化`
|
|
|
|
### 3.9 纹理
|
|
|
|
`纹理`可以理解为图片(实质上是`位图`),图像渲染时经常需要填充图片。这里的图片其实就是纹理,在`OpenGL`中,我们更喜欢称之为`纹理`。
|
|
|
|
- 常见图像文件格式(BMP,TGA,JPG,GIF,PNG)
|
|
- 常见纹理格式(R5G6B5,A4R4G4B4,A1R5G5B5,R8G8B8, A8R8G8B8等)
|
|
|
|
### 3.10 混合
|
|
|
|
`混合`(Blending)是把某一像素位置原来的颜色和将要画上去的颜色,通过某种方式(混合算法)混在一起,从而实现特殊的效果。简单理解就是把两种/多种颜色混合在一起。
|
|
|
|
- 混合的算法可以通过`OpenGL`的函数进⾏指定。但是`OpenGL`提供的混合算法是有限的,如果需要更加复杂的混合算法,⼀般可以通过`片元着⾊器`实现,当然性能会⽐原⽣的混合算法差一些。
|
|
|
|
### 3.11 矩阵
|
|
|
|
在`OpenGL`中,矩阵常常被用来进行辅助运算,如:
|
|
|
|
- `变换矩阵`(Transformation)用于图形的平移、缩放、旋转变换;
|
|
- `投影矩阵`(Projection)用于将3D坐标转换为二维屏幕坐标,实际线条也将在二维坐标下进行绘制。 等。
|
|
|
|
### 3.12 帧缓存
|
|
|
|
`帧缓冲存储器`(Frame Buffer),简称`帧缓存`或`显存`,它是接收渲染结果的缓冲区,为`GPU`指定存储渲染结果的区域。
|
|
|
|
关于`帧缓存`,说明如下:
|
|
|
|
- 全部的图形图像都共享内存中同一个`帧缓存`。
|
|
- `帧缓存`是实时的:`帧缓存`中存储的是一帧一帧的、渲染完成的图像,显卡会不停的刷新`帧缓存`, 这每一帧如果不捕获的话,则会被丢弃。
|
|
- `帧缓存`的每一帧都是一个显性的信息:假设分辨率是`750 x 1334`,则每一帧保存的是`750 x 1334`个像素点(每一个像素点都有颜色值)。
|
|
|
|
> `缓冲区`(Buffer)这个中文译意源自当计算机的高速部件与低速部件通讯时,必须将高速部件的输出暂存到某处,以保证高速部件与低速部件相吻合。后来这个意思被扩展了,成为“临时存贮区”的意思。
|
|
|
|
## 4、 思考:
|
|
|
|
### 4.1 Why GPU?
|
|
|
|
思考:为什么`OpenGL`使用`GPU`而不是`CPU`?
|
|
|
|
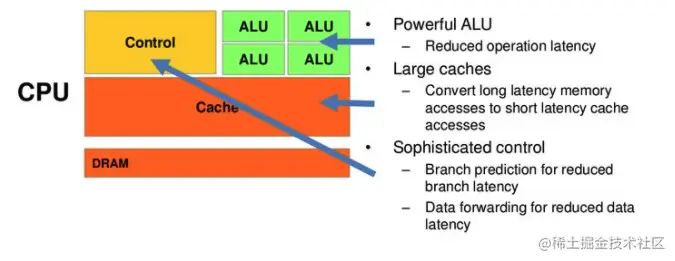
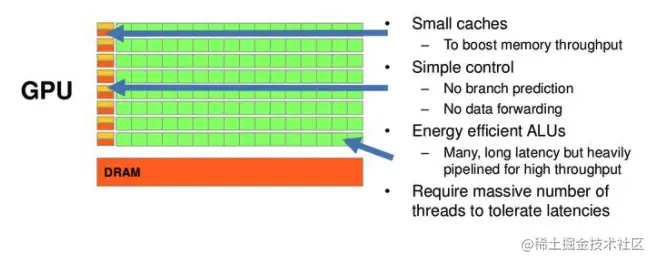
解析:解答这个问题要理解`GPU`(中央处理器)和`CPU`(图形处理器)的区别。首先看一下这两者的设计,大致如下:
|
|
|
|
|
|
|
|
|
|
|
|
> 图片来自 **Nvidia CUDA** 文档,其中绿色的是计算单元,橙红色的是存储单元,黄色的是控制单元。
|
|
|
|
从图中不难看出,
|
|
|
|
- ```
|
|
CPU
|
|
```
|
|
|
|
具有
|
|
|
|
- 强大的算术运算单元(ALU),它可以在很少的时钟周期内完成算术运算;
|
|
- 大的缓存,这可以降低延时;
|
|
- 复杂的逻辑控制单元,当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
|
|
|
|
- ```
|
|
GPU
|
|
```
|
|
|
|
具有
|
|
|
|
- 很多的算术运算单元,计算量大;
|
|
- 很小的缓存,缓存的目的不是保存后面需要访问的数据,而是为`Thread`服务,这点和`CPU`不同。如果有很多线程需要访问同一个数据,缓存会合并这些访问,然后再去访问`DRAM`(因为需要访问的数据保存在`DRAM`中而不是`cache`里面),获取数据后`cache`会转发这个数据给对应的线程,也就是说,`GPU`的小缓存充当的是数据转发的角色。
|
|
- 简单的控制单元,主要是把多个访问合并成少的访问。
|
|
|
|
此外,`CPU`虽然号称多核,但总数没有超过两位数;而`GPU`的核数远超`GPU`,被称为众核。
|
|
|
|
总的来说,**`CPU`擅长逻辑控制以及串行的运算,而`GPU`则擅长大规模的并发计算**。在`OpenGL`渲染图形图像的时候,往往伴随着海量的计算(如对每一个顶点进行同样的坐标变换,对每一个片元计算颜色值等等),因此,`OpenGL`使用`GPU`而不是`CPU`。
|
|
|
|
## 5、友情链接
|
|
|
|
- [OpenGL专有名词解析(夹杂通俗举例和个人理解)](https://link.juejin.cn?target=https%3A%2F%2Fwww.jianshu.com%2Fp%2Fa7096a6c16a7)
|
|
- [帧缓存](https://link.juejin.cn?target=https%3A%2F%2Fbaike.baidu.com%2Fitem%2F%E5%B8%A7%E7%BC%93%E5%AD%98%2F5725254)
|
|
- [CPU和GPU的区别](https://link.juejin.cn?target=https%3A%2F%2Fwww.zhihu.com%2Fquestion%2F19903344%2Fanswer%2F96081382)
|
|
|
|
|
|
原文链接:https://juejin.cn/post/6940900616881307679 |